主要研究方向:
- 细粒度多模态大模型:提取并融合文本、图像、视频等多模态的数据表征,通过大语言模型进行推理,经过微调后适配到多种细粒度视觉感知任务。从人类视觉系统的“双流假设”出发,视觉感知可分解为“识别对象”、“确定位置”与“跟踪变化”三个基础阶段,分别对应细粒度多模态大模型的三个维度:(1)类别细粒度:区分同一大类下高度相似的不同子类别。例如,不仅识别出“鸟”,更能区分“小纹霸鹟”与“阿卡迪亚霸鹟”等具体鸟类物种。(2)空间细粒度:在高分辨率输入中对微小、密集或语义复杂的区域进行定位与识别。不仅检测显著物体,还能根据逻辑推理精准定位复杂场景中的特定目标或理解精细的局部细节。(3)时间细粒度:在视频中定位和理解事件或动作,不仅生成视频摘要,还能精确定位动作的时间边界,并将复杂动作分解为子动作进行时序分析。
- Hulingxiao He, Zhi Tan and Yuxin Peng*, "Learning Taxonomy on Hyperbolic Manifolds for Large Multimodal Models", Forty-Third International Conference on Machine Learning (ICML), Seoul, South Korea, Jul. 6-11, 2026. (Accept)
- Hulingxiao He, Zhi Tan and Yuxin Peng*, "Taxonomy-Aware Representation Alignment for Hierarchical Visual Recognition with Large Multimodal Models", The IEEE/CVF Conference on Computer Vision and Pattern Recognition 2026 (CVPR), Denver CO, USA, Jun. 3-7, 2026. (Accept)【pdf】【source code】【AI科技评论报道】
- Jinglin Xu, Sibo Yin and Yuxin Peng*, "Human-centric Fine-grained Action Quality Assessment", IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI), vol. 47, no. 8, pp. 6242-6255, Aug. 2025.【pdf】【source code】【宣传海报】
- Yuxin Peng*, Zishuo Wang, Geng Li, Xiangtian Zheng, Sibo Yin and Hulingxiao He, "A Survey on Fine-Grained Multimodal Large Language Models", Chinese Journal of Electronics (CJE), 2026. (Accept)【pdf】【中国电子学会报道】
- Yuxin Peng*, Minghang Zheng and Yang Liu, "Cross-Modal Retrieval from Coarse-Grained to Fine-Grained Perspectives: A Survey", Journal of Computer Science and Technology (JCST), 2026. DOI: 10.1007/s11390-026-5922-5. 【pdf】【JCST报道】
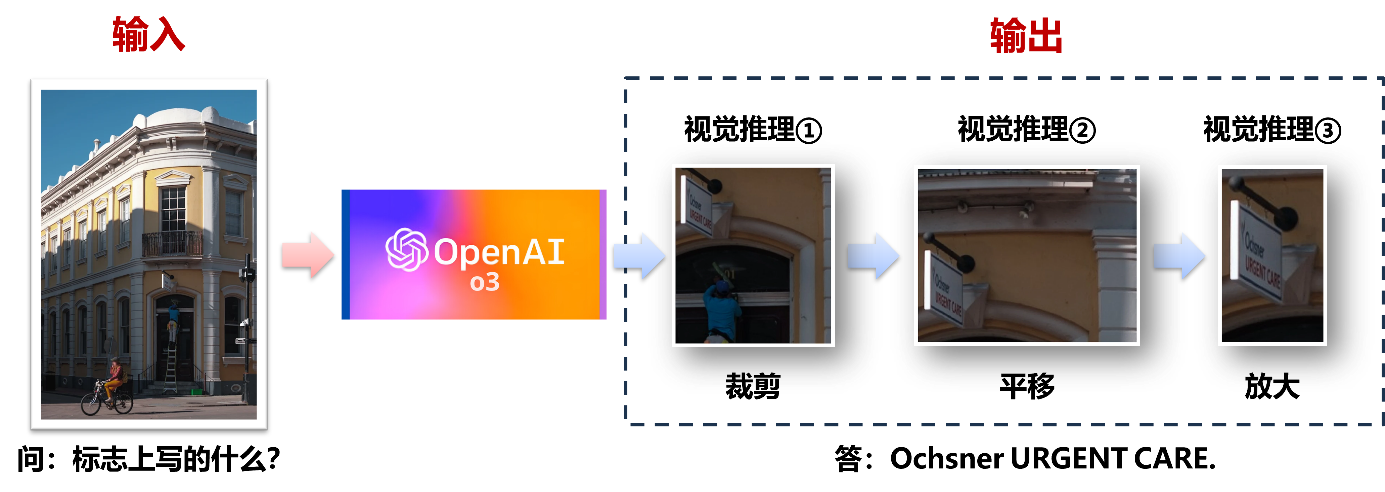
- 细粒度视觉推理大模型:通过“图像思考(thinking with images)”,利用视觉模态作为推理中间步骤,赋予模型主动感知—主动聚焦—主动验证的视觉推理能力,能够自适应地执行图像缩放、裁剪、局部放大等多步操作,对图像关键区域进行逐层深入的细粒度感知,突破高分辨率图像处理及复杂场景下的小目标识别难题,使得大模型能够在保留全局视野的同时,精准捕捉局部微弱但判别性强的细节视觉线索,完成更深层次的细粒度视觉理解任务。
- Geng Li and Yuxin Peng*, "BVS: Bayesian Visual Search with Multimodal Large Language Model for Fine-grained Perception", Forty-Third International Conference on Machine Learning (ICML), Seoul, South Korea, Jul. 6-11, 2026. (Accept)
- Geng Li, Jinglin Xu, Yunzhen Zhao and Yuxin Peng*, "DyFo: A Training-Free Dynamic Focus Visual Search for Enhancing LMMs in Fine-Grained Visual Understanding", 38th IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , Music City Center, Nashville TN, USA, Jun. 11-15, 2025. (Highlight, 13.5%) 【pdf】【source code】【Poster】【VALSE 报道】【CVer报道】【极市平台报道】
- Hulingxiao He, Zijun Geng and Yuxin Peng*, "Fine-R1: Make Multi-modal LLMs Excel in Fine-Grained Visual Recognition by Chain-of-Thought Reasoning", The Fourteenth International Conference on Learning Representations (ICLR), Rio de Janeiro, Brazil, Apr. 23-27, 2026. (Accept)【pdf】【source code】【量子位报道】【极市平台报道】【CVer报道】
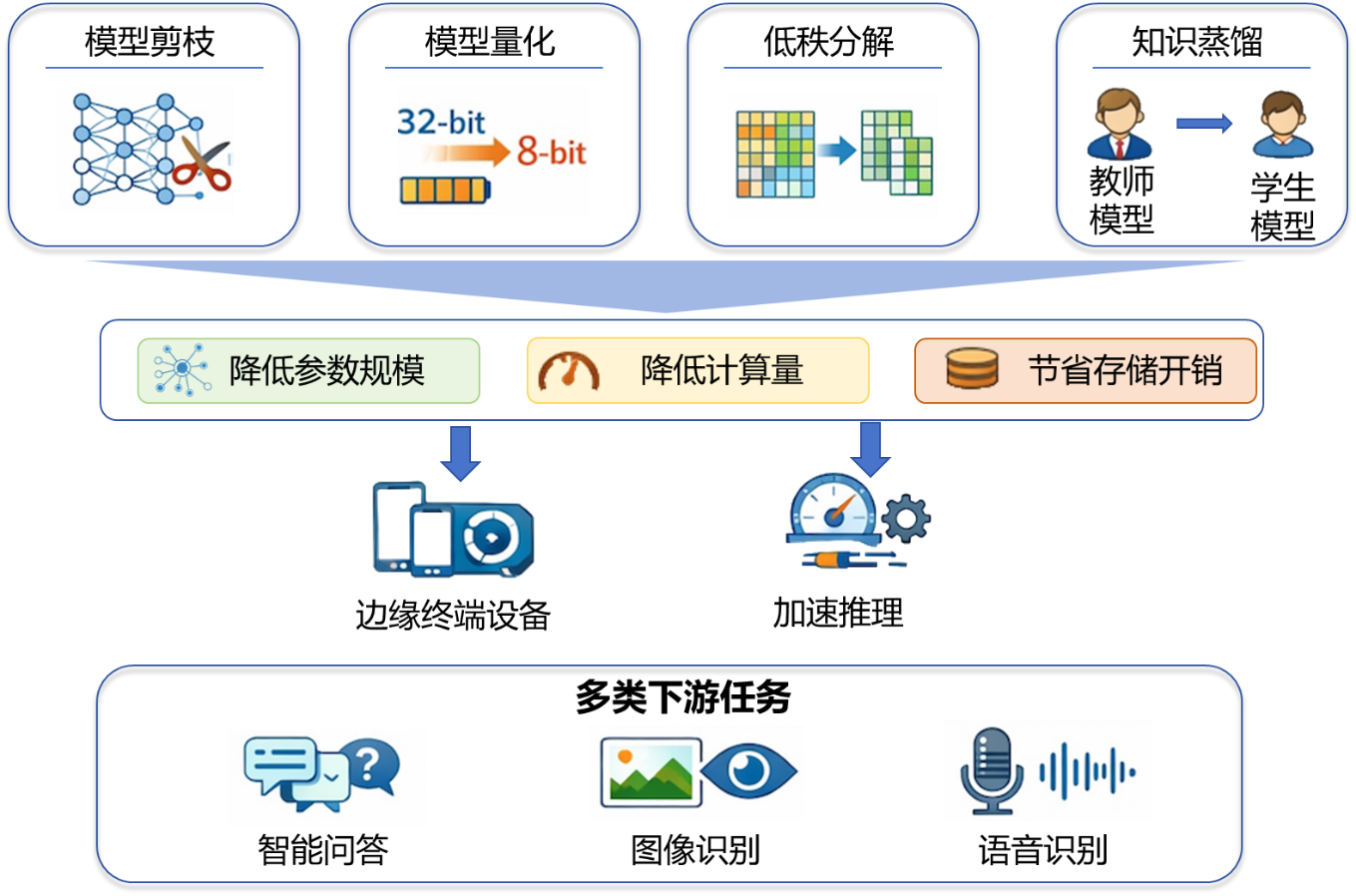
- 大模型轻量化:面向大模型在实际场景中的落地需求,研究模型剪枝、量化、低秩分解、知识蒸馏等轻量化技术,在保持模型精度的同时,大幅降低参数规模、计算开销与存储成本,实现大模型在手机、平板、智能汽车等端侧设备上的高效部署与实时推理。
- Zishuo Wang, Xiangtian Zheng and Yuxin Peng*, "FinePruner: Unbiased Attention-Head-Level Fine-grained Token Reduction for Efficient Inference of Large Vision-Language Models", IEEE Transactions on Image Processing (TIP) , 2026. (Accept)
- Xiangtian Zheng, Zishuo Wang and Yuxin Peng*, "TiFRe: Text-guided Video Frame Reduction for Efficient Video Multi-modal Large Language Models", arXiv, Feb. 2026. 【pdf】
- AIGC:研究内容与风格可控的生成扩散模型,实现图像、视频等视觉内容的高质量、多样化生成。例如,在电商场景中,可根据商品图像与设计文案自动生成视觉美观、布局合理的宣传海报;或结合人物图像与动作描述,生成主体一致、动作自然的短视频内容。
- Zijun Deng and Yuxin Peng*, "NS-Diff: Fluid Navier–Stokes Guided Video Diffusion via Reinforcement Learning", The IEEE/CVF Conference on Computer Vision and Pattern Recognition 2026 (CVPR), Denver CO, USA, Jun. 3-7, 2026. (Accept)【pdf】【source code】
- HsiaoYuan Hsu, Yuxin Peng*, "Scan-and-Print: Patch-level Data Summarization and Augmentation for Content-aware Layout Generation in Poster Design", The 34th International Joint Conference on Artificial Intelligence (IJCAI-25) AI, the Arts and Creativity Special Track, pp. 10090-10098, Apr. 2025. 【pdf】【source code】
- HsiaoYuan Hsu and Yuxin Peng*, "PosterO: Structuring Layout Trees to Enable Language Models in Generalized Content-Aware Layout Generation", 38th IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , Music City Center, Nashville TN, USA, Jun. 11-15, 2025. 【pdf】【source code】
- 美学理解:模拟人类的审美感知与情感响应过程,研究面向图像与视频的美学质量评价、情感语义分析及审美导向的生成与增强技术,包括影像美学分析、智能拍摄引导、构图取景优化、可控照片精修等任务。例如,给定一张照片,模型可基于摄影美学规则自动诊断画面问题,智能推荐取景范围与拍摄机位,并进一步优化画面构图布局、光影关系与色彩层次,帮助非专业用户创作出媲美专业摄影师水准的作品。
- Tianxiang Du, Hulingxiao He and Yuxin Peng*, "AesFormer: Transform Everyday Photos into Beautiful Memories", Forty-Third International Conference on Machine Learning (ICML), Seoul, South Korea, Jul. 6-11, 2026. (Accept)
- Tianxiang Du, Hulingxiao He and Yuxin Peng*, "Venus: Benchmarking and Empowering Multimodal Large Language Models for Aesthetic Guidance and Cropping", The IEEE/CVF Conference on Computer Vision and Pattern Recognition 2026 (CVPR), Denver CO, USA, Jun. 3-7, 2026. (Accept)【pdf】【source code】【量子位报道】
- Guohao Zhao and Yuxin Peng*, "PG-VTON: Single-Pass Training-Free Virtual Try-On via Patch-Guided Reference Alignment", The IEEE/CVF Conference on Computer Vision and Pattern Recognition 2026 (CVPR), Denver CO, USA, Jun. 3-7, 2026. (Accept)【pdf】【source code】
- 自动驾驶:综合利用激光雷达、视觉相机、毫米波雷达等多传感器数据,构建从原始传感器输入到控制信号输出的端到端模型架构,实现对复杂动态环境的精准感知、意图理解与决策规划。
- Zhiwen Yang and Yuxin Peng*, "Multi-Resolution Alignment for Voxel Sparsity in Camera-Based 3D Semantic Scene Completion", IEEE Transactions on Image Processing (TIP) , 2026. (Accept) 【pdf】【source code】
- Zhiwen Yang and Yuxin Peng*, "HD²-SSC: High-Dimension High-Density Semantic Scene Completion for Autonomous Driving", 40th AAAI Conference on Artificial Intelligence (AAAI), Singapore, Jan. 20-27, 2026. 【pdf】【source code】
- Zhiwen Yang and Yuxin Peng*, "SPHERE: Semantic-PHysical Engaged REpresentation for 3D Semantic Scene Completion", The 33rd ACM International Conference on Multimedia (ACM MM), Dublin, Ireland, Oct. 27-31, 2025. 【pdf】【source code】【video】