2026-02-21:MIPL的7篇论文被CVPR 2026接收
MIPL共有7篇论文被接收,研究视频自动生成、多模态大模型层次视觉识别、美学理解、虚拟换装、开放世界视频时序定位、多模态模型理解生成统一和3D布局生成。
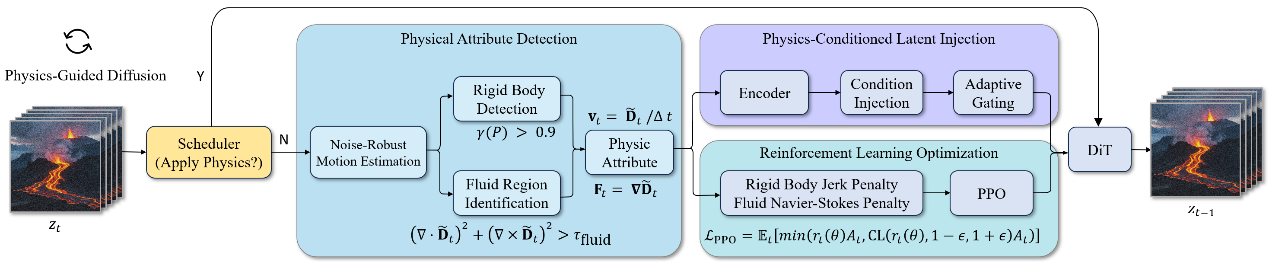
(1)NS-Diff: 物理引导的视频生成强化学习框架
NS-Diff: Fluid Navier–Stokes Guided Video Diffusion via Reinforcement Learning
作者:邓梓焌(博士生),彭宇新
通讯作者:彭宇新
论文链接:http://39.108.48.32/mipl/download_paper.php?fileId=202601
源代码链接:https://github.com/PKU-ICST-MIPL/NS-Diff_CVPR2026
尽管当前视频生成模型视觉效果惊艳,但在物理真实性上仍存在巨大瓶颈,尤其在模拟刚体与流体运动时面临很大困难。现有方法在追求视觉效果的同时,难以满足真实世界的物理规律约束,导致视觉生成内容如物体运动等缺乏物理真实感,这也是当前AIGC普遍存在的巨大挑战。
针对上述挑战,本文提出了一种物理引导的视频生成强化学习框架NS-Diff,将物理约束融入视频扩散过程中,以提升生成视频的物理真实感。其主要贡献包括:(1)噪声鲁棒的物理动力学检测器:设计了可在含噪潜在帧中精准分析运动信息的检测器,实现对刚体与流体区域的有效区分。(2)物理条件潜在注入模块:将速度场、形变梯度等关键物理信息编码,并通过交叉注意力机制注入DiT去噪器,从而实现对生成过程的物理引导。(3)强化学习优化模块:引入强化学习,通过策略梯度对流体施加简化的纳维-斯托克斯约束,对刚体施加最小化急动度(Jerk)原则,确保了动态过程的物理合理性。实验结果表明,在PhysVideoBench、UCF、MSR-VTT等多个基准测试中,本文提出的NS-Diff不仅将刚体运动的急动度误差降低43%、流体动力学的散度减少33%,还在视频保真度指标上提高了22.7%,实现了物理真实性与视觉真实性的双重提升。
该论文的第一作者是北京大学王选计算机研究所2022级博士生邓梓焌,通讯作者是彭宇新教授。
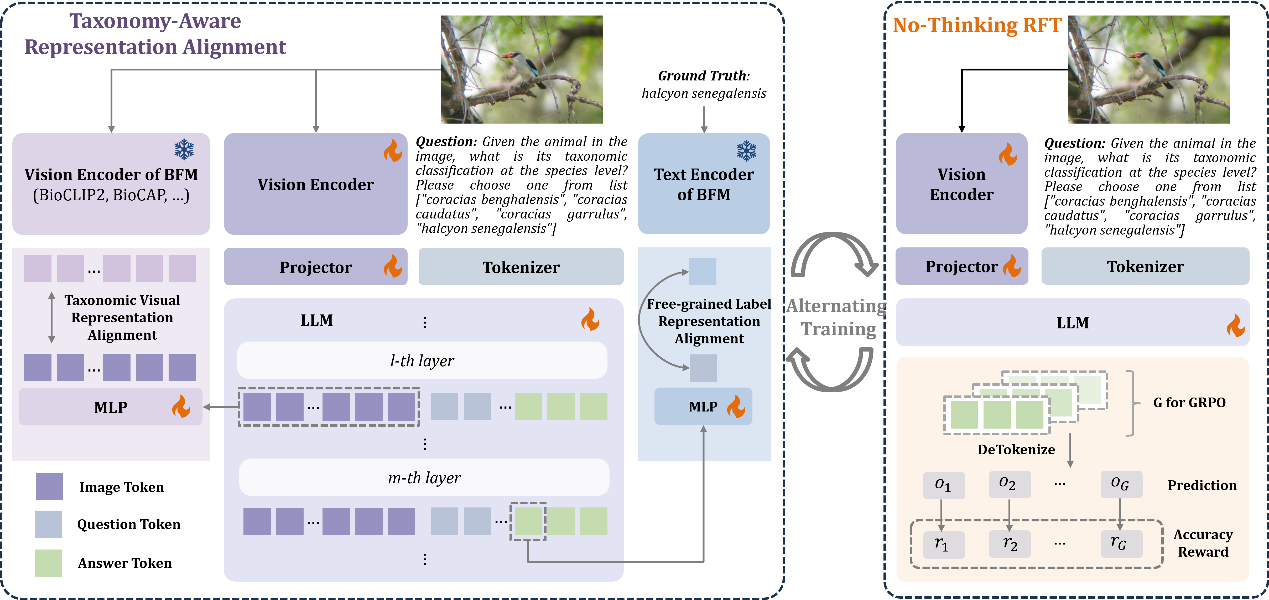
(2)面向多模态大模型层次视觉识别的分类感知表征对齐方法
Taxonomy-Aware Representation Alignment for Hierarchical Visual Recognition with Large Multimodal Models
作者:何胡凌霄(博士生),谭智(硕士生),彭宇新
通讯作者:彭宇新
论文链接:https://arxiv.org/abs/2603.00431
源代码链接:https://github.com/PKU-ICST-MIPL/TARA_CVPR2026
真实世界中的对象通常包含极其丰富的类别层次,形成分类树结构。以蓝锥嘴雀为例,类别层次从粗粒度到细粒度依次包含:动物界-脊索动物门-鸟纲-雀形目-唐纳雀科-锥嘴雀属-蓝锥嘴雀(界-门-纲-目-科-属-种)。区别于传统的细粒度视觉识别(Fine-Grained Visual Recognition, FGVR),层次视觉识别(Hierarchical Visual Recognition, HVR)旨在预测所属的所有类别层次,而不仅仅预测最终的细粒度类别。尽管现有多模态大模型的细粒度视觉识别能力超越了CLIP等判别式模型,但由于缺乏分类树知识,无法从粗到细实现每一层的精准识别。
针对上述问题,本文提出了分类感知表征对齐方法(Taxonomy-Aware Representation Alignment,TARA),用于将分类树结构知识注入多模态大模型。通过将大模型与生物基础模型(Biology Foundation Model, BFM)的视觉表征对齐,促进大模型提取具备完整分类树结构的视觉表征。同时,通过将大模型输出答案的首个词元(token)表征与经BFM编码后的真实类别表征对齐,促进大模型根据指定的层次,将具备完整分类树结构的视觉表征映射为对应层次的类别名称。实验结果表明,本方法不仅能增强现有大模型的细粒度视觉识别能力,提升最终的细粒度类别的识别准确率,还能增强层次视觉识别能力,从粗到细提升分类树上每一层的识别准确率。
该论文的第一作者是北京大学王选计算机研究所2023级博士生何胡凌霄,通讯作者是彭宇新教授。
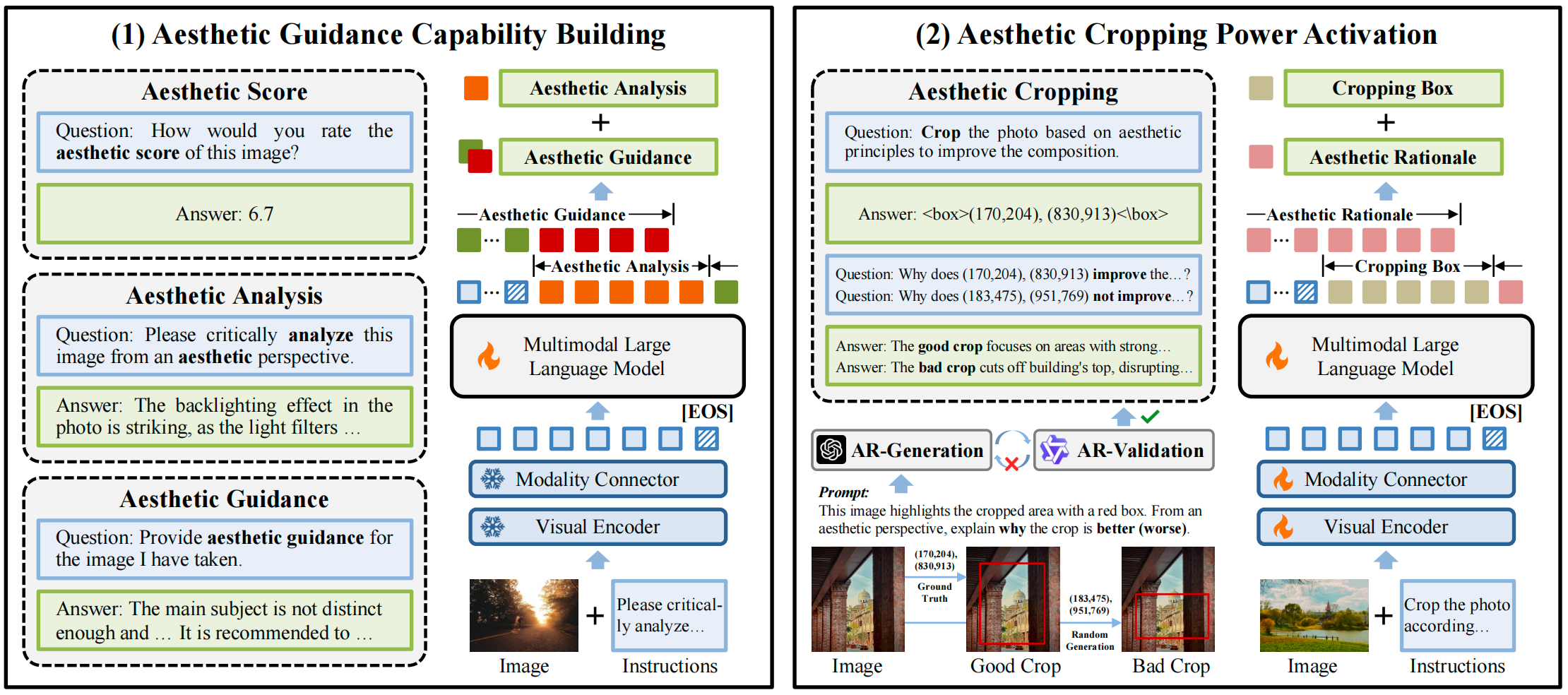
(3)Venus:面向美学指导与裁剪的多模态大模型基准评测与能力增强
Venus: Benchmarking and Empowering Multimodal Large Language Models for Aesthetic Guidance and Cropping
作者:都天翔(博士生),何胡凌霄(博士生),彭宇新
通讯作者:彭宇新
论文链接:https://arxiv.org/abs/2602.23980
源代码链接:https://github.com/PKU-ICST-MIPL/Venus_CVPR2026
美学指导(Aesthetic Guidance)旨在对照片进行美学评价,识别画面问题并给出准确、易理解且可操作的拍摄建议,帮助非专业用户拍出接近专业摄影师水准的照片;而美学裁剪(Aesthetic Cropping)则面向拍摄后的取景优化,通过图像裁剪来提升构图质量。然而,当前多模态大模型在这两个美学任务中存在明显不足:在美学指导中,模型往往倾向于给出“过度正向”的反馈,即对存在明显问题的照片仍进行偏赞美式的正向描述,无法精准定位拍摄缺陷并提供可操作的调整方案;在美学裁剪中,模型难以准确识别照片主体并区分画面中的干扰区域,因此无法确定合理的裁剪范围,裁剪后的照片往往偏离理想构图。
针对上述挑战,本文首先构建了一个新的美学指导数据集与评测基准AesGuide,涵盖如下2个特点:(1)问题定位:每张照片配有专业美学评价,明确指出构图松散、光线失衡、人景关系不协调等关键审美问题;(2)拍摄指导:给出可操作的拍摄建议,强调“问题-原因-改法”的完整闭环。在此基础上,本文进一步提出一种以美学指导能力为核心的裁剪能力激活方法,实现先学习美学指导,再以指导带动裁剪,联合学习两个任务。具体贡献如下:(1)美学指导能力构建:基于AesGuide进行监督微调,通过构建“整体印象-细致分析-可操作建议”的渐进式审美问答思维链,引导模型形成更接近人类的审美推理路径,赋予大模型美学指导能力;(2)美学裁剪能力激活:引入基于思维链的裁剪推理,训练模型同时预测裁剪框坐标及其对应的裁剪依据文本,从而联合学习几何取景决策与构图逻辑,确定合理的裁剪范围。实验结果表明,本文方法在构建的美学指导评测基准和开源美学裁剪评测基准FLMS上均取得了优于现有方法的效果。
该论文的第一作者是北京大学王选计算机研究所2025级博士生都天翔,通讯作者是彭宇新教授。
(4)PG-VTON: 基于图像块引导进行参考服装对齐的单步免训练虚拟换装方法
PG-VTON: Single-Pass Training-Free Virtual Try-On via Patch-Guided Reference Alignment
作者:赵国豪(博士生),彭宇新
通讯作者:彭宇新
论文链接:http://39.108.48.32/mipl/download_paper.php?fileId=202604
源代码链接:https://github.com/PKU-ICST-MIPL/PG-VTON_CVPR2026
虚拟换装(Virtual Try-On,VTON)技术旨在将服装渲染到人物图像上,同时保留人物的姿态、身份和外观特征,在电子商务和内容创作领域具有重要的应用价值。然而,当前虚拟换装方法大多需要在特定的换装数据集上进行训练,这类数据集大多局限于室内影棚环境、单一拍摄视角和同质化服装风格,容易导致模型过拟合,迁移到室外街拍等复杂场景时(姿态复杂、光照多样、遮挡严重、服装类型变化),容易出现纹理模糊、颜色漂移与形变失真等跨域泛化问题。近期免训练(Training-free)虚拟换装方法虽然鲁棒性更强,但通常依赖繁琐的人体姿态估计、语义匹配以及多次扩散生成调用。这种复杂的推理流程不仅带来了显著的推理延迟与计算开销,也导致其实际部署变得非常困难。
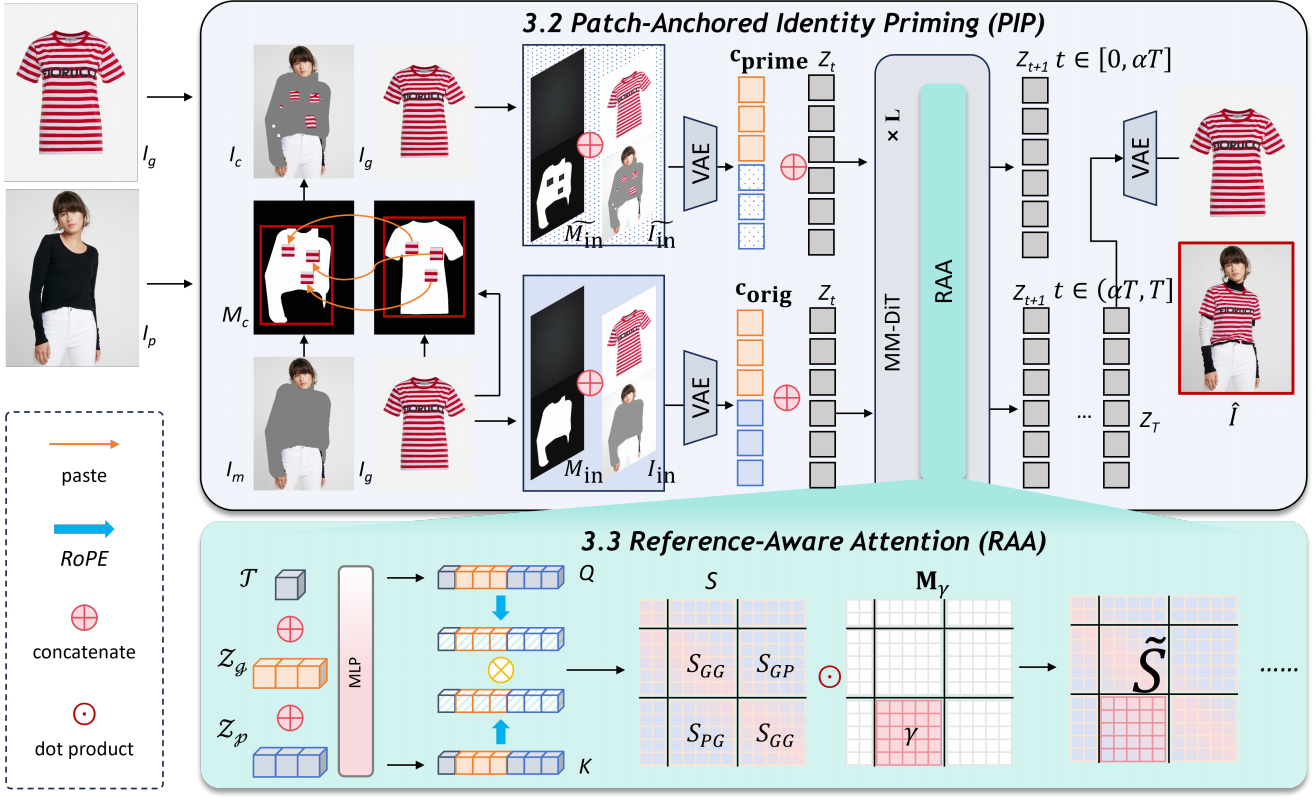
针对上述挑战,本文提出了一种基于图像块引导参考对齐的单步、免训练虚拟换装框架(PG-VTON)。该方法摒弃了对特定任务数据的依赖,也无需繁琐的多阶段推理,深入挖掘了预训练修复(Inpainting)模型潜在的上下文补全能力。本文主要贡献包括:(1)图像块锚定身份引导(PIP, Patch-Anchored Identity Priming):在去噪早期注入少量局部服装图像块作为视觉锚点,有效引导生成轨迹,避免了直接“硬粘贴”带来的接缝明显和位置错乱等问题。(2)参考感知注意力(RAA, Reference-Aware Attention):在注意力机制中选择性增强对服装特征的关注程度,有效保持纹理、标志和边缘等精细特征。实验结果表明,PG-VTON在DressCode和VITON-HD等基准测试中达到了免训练方法的SOTA性能,能够生成更清晰的纹理和标志,同时能够泛化到主体插入(Subject Insertion)等更广泛的参考条件生成任务中,并且仅需单次扩散推理即可完成生成,实现了生成质量与推理效率的同步提升。
该论文的第一作者是北京大学王选计算机研究所2024级博士生赵国豪,通讯作者是彭宇新教授。
(5)OmniVTG: 面向开放世界视频时序定位的大规模数据集与训练范式
OmniVTG: A Large-Scale Dataset and Training Paradigm for Open-World Video Temporal Grounding
作者:郑明航(博士生),尹子昊,杨怡,彭宇新,刘洋
通讯作者:刘洋
论文链接:http://39.108.48.32/mipl/download_paper.php?fileId=202605
源代码链接:https://github.com/minghangz/OmniVTG
视频时序定位(Video Temporal Grounding, VTG)旨在根据自然语言查询在未剪辑视频中精准识别事件的起止时间 。随着多模态大模型(MLLMs)在开放世界应用中的普及,现有研究暴露出两大挑战:一是现有数据集规模有限且语义覆盖狭窄,导致模型在处理常见与罕见概念时存在显著的性能鸿沟 ;二是简单的监督微调(SFT)不足以消除此鸿沟,模型面对陌生概念时仍缺乏鲁棒的推理机制。
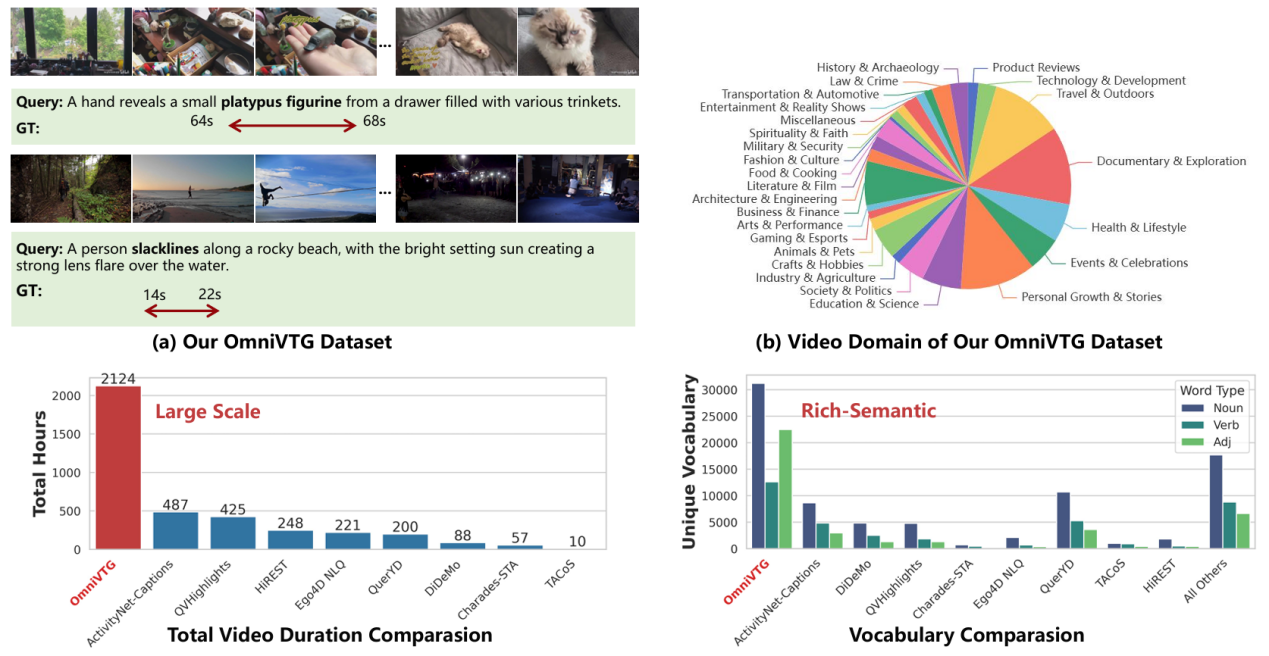
为克服这些局限,本文提出OmniVTG,从数据与方法两方面增强MLLMs的时序定位能力。在数据层面:(1)语义覆盖迭代扩展:提出全新数据收集策略,主动识别词汇盲区并定向检索,构建了包含2124小时视频、超35万条查询的大规模语义丰富数据集;(2)以描述为中心的自动化标注:利用MLLM在密集描述上的优势,生成包含目标罕见词的带时间戳描述,实现高质量全自动标注。在方法层面:(3)自我纠错思维链(CoT):基于模型理解能力强于直接定位能力的洞察,设计了SFT、CoT微调与强化学习的三阶段训练范式。该方法引导模型“先预测,后反思修正”,有效缩小了罕见与常见概念的性能差距,并在四个公开VTG基准上取得了最佳的零样本性能。
该论文的第一作者是北京大学王选计算机研究所2022级博士生郑明航,通讯作者是刘洋助理教授,与彭宇新教授合作完成。
(6)通过理解学会生成:面向统一多模态模型的理解驱动内生奖励机制
Learning to Generate via Understanding: Understanding-Driven Intrinsic Rewarding for Unified Multimodal Models
作者:潘佳栋(硕士生),李亮,彭宇新,汤裕明,王硕寰,孙宇,吴华,黄庆明,王海峰
通讯作者:李亮
论文链接:https://arxiv.org/abs/2603.06043
项目主页链接:https://matrix0721.github.io/gvu.github.io/
近期,统一多模态模型在视觉理解与生成一体化方面取得了显著进展,展现出处理复杂文生图任务的良好潜力。然而,尽管理论上具备统一建模的优势,这类模型在实际表现中仍存在一定的能力断层:其视觉理解能力往往较为突出,而生成能力相对不足。这种差异在一定程度上源于理解与生成过程之间的内在解耦——模型能够较为精细地解析视觉细节,却难以在复杂文本条件下生成语义连贯且结构合理的图像。
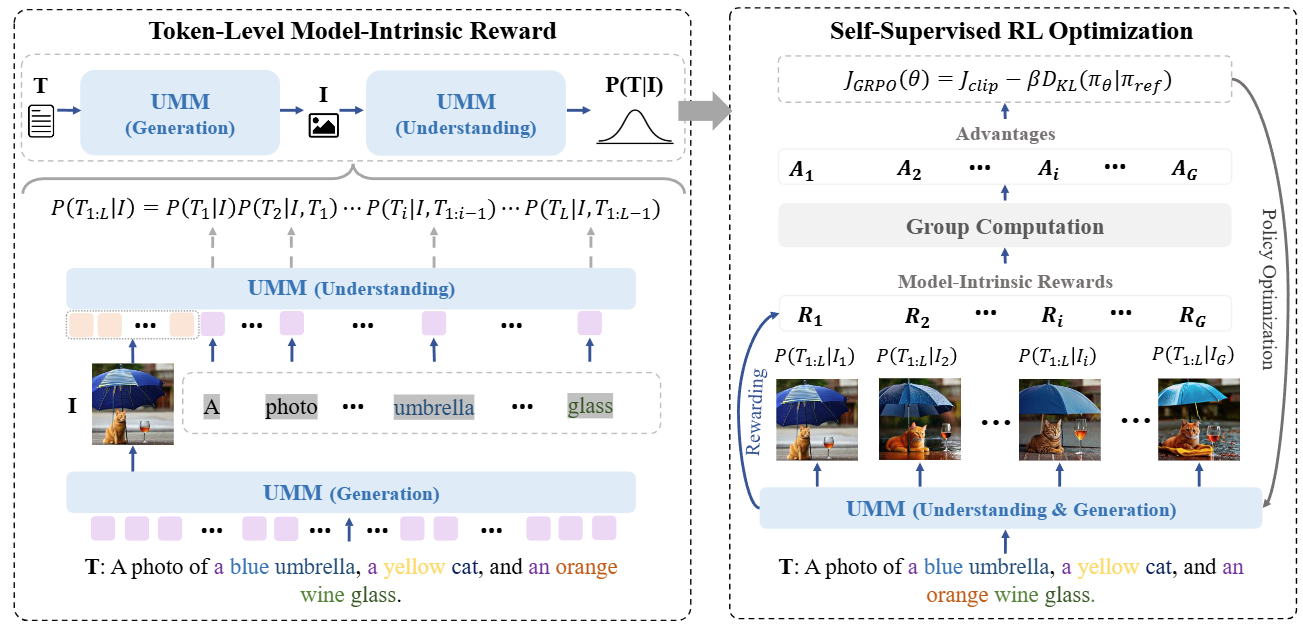
为缓解这一瓶颈,本文尝试挖掘统一多模态模型内部已有的理解能力,以反向促进生成性能的提升。具体而言,本文提出了一种基于词元级图文对齐的内在奖励机制 GvU,使模型在训练过程中同时承担“教师”与“学生”的双重角色:通过理解分支对生成结果进行评估,并将评估信号反馈至生成过程,从而实现自我引导与自我优化。
在此基础上,本文构建了一个自监督强化学习框架,使统一多模态模型能够利用基于理解的内在奖励信号,对生成策略进行迭代优化,而无需依赖额外的外部监督。实验结果表明,该方法在一定程度上提升了模型的生成质量,同时增强了其细粒度视觉理解能力,有效缓解了视觉理解与生成之间的能力差距。
该论文的第一作者是中国科学院计算技术研究所2023级硕士生潘佳栋,通讯作者是李亮研究员,与彭宇新教授合作完成。
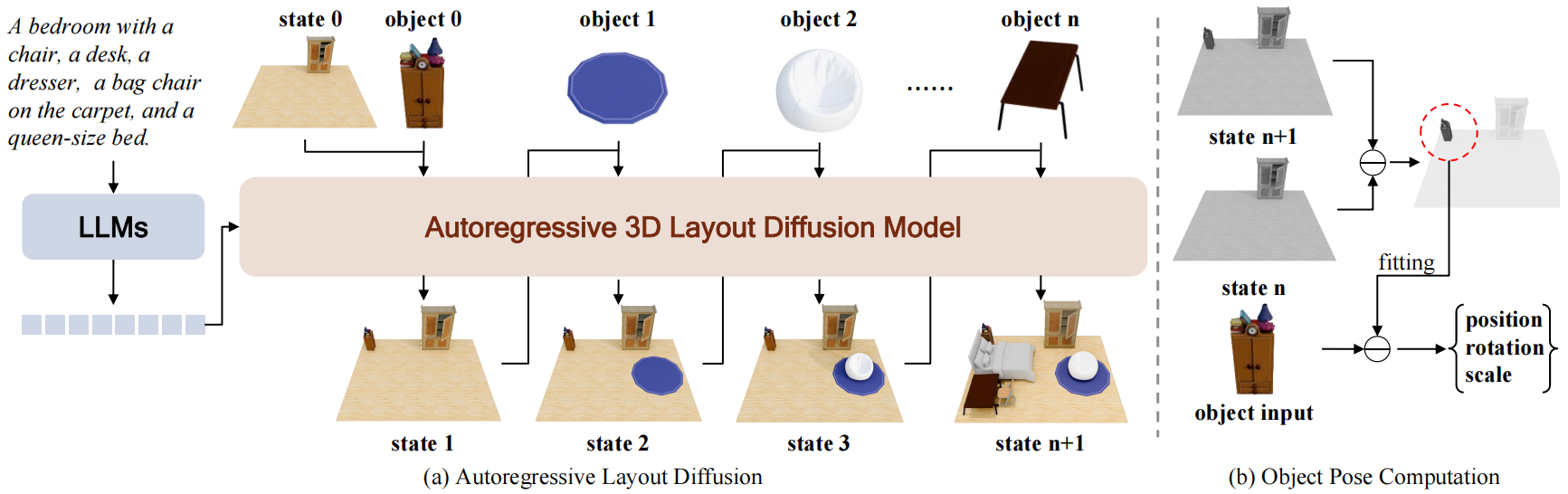
(7)从“文本推理”到“原生3D生成”:复用3D生成模型先验的自回归场景生成新范式
Repurposing 3D Generative Model for Autoregressive Layout Generation
作者:封皓然(硕士生),牛奕帆(本科生),黄泽桓,孙阳天,郭春超,彭宇新,盛律
通讯作者:盛律
论文链接:http://39.108.48.32/mipl/download_paper.php?fileId=202607
源代码链接:https://github.com/fenghora/LaviGen
现有3D布局生成方法通常将场景布局序列化为结构化语言表示,由大语言模型根据文本提示生成包含物体类别及位姿、尺度等几何属性的布局参数文件。然而,该范式本质上仍停留在“文本—符号序列”层面,难以原生建模连续的3D几何关系与物理可行性约束,因而易产生碰撞、漂浮与越界等几何偏差问题。
针对上述问题,本文提出 LaviGen,通过复用3D生成模型在大规模3D场景中学到的几何先验,将布局生成直接建立在原生3D几何分布之上,使模型能够在3D空间中逐步放置物体并更新场景状态,从生成机制上内生地满足物理可行的空间布局约束。方法包含三项关键设计:(1)Autoregressive 3D Layout Diffusion:将当前场景与待放置物体编码为3D潜空间表示,并与噪声拼接输入,在文本条件引导下生成更新后的场景状态,实现渐进式布局合成;(2)Identity-aware Positional Embedding:在位置编码中引入额外的身份嵌入以区分场景流与物体流,并保持空间对齐,增强几何关系建模与语义解耦;(3)Post-Training via Dual-Guidance Self-Rollout:结合场景级整体引导,与逐步的场景—物体对齐监督,缓解长序列生成的曝光偏差与误差累积,提升连贯性与稳定性。
实验结果表明,LaviGen 相比现有最优方法(例如LayoutGPT,LayoutVLM)实现19%的物理合理性提升,并将计算时间降低约65%,同时支持布局完善与布局编辑等下游应用。
该论文的第一作者是清华大学深圳研究生院2024级硕士生封皓然与北京航空航天大学2023级本科生牛奕帆,通讯作者是盛律教授。