2026-01-26:MIPL的2篇论文被ICLR 2026接收
MIPL共有2篇论文入选,研究细粒度多模态大模型和视觉语言大模型细粒度评测。
(1)Fine-R1: 通过思维链推理增强多模态大模型的细粒度视觉识别能力
Fine-R1: Make Multi-modal LLMs Excel in Fine-Grained Visual Recognition by Chain-of-Thought Reasoning
作者:何胡凌霄(博士生),耿子竣(博士生),彭宇新
通讯作者:彭宇新
论文链接:https://openreview.net/pdf?id=kyzHM557gE
源代码链接:https://github.com/PKU-ICST-MIPL/FineR1_ICLR2026
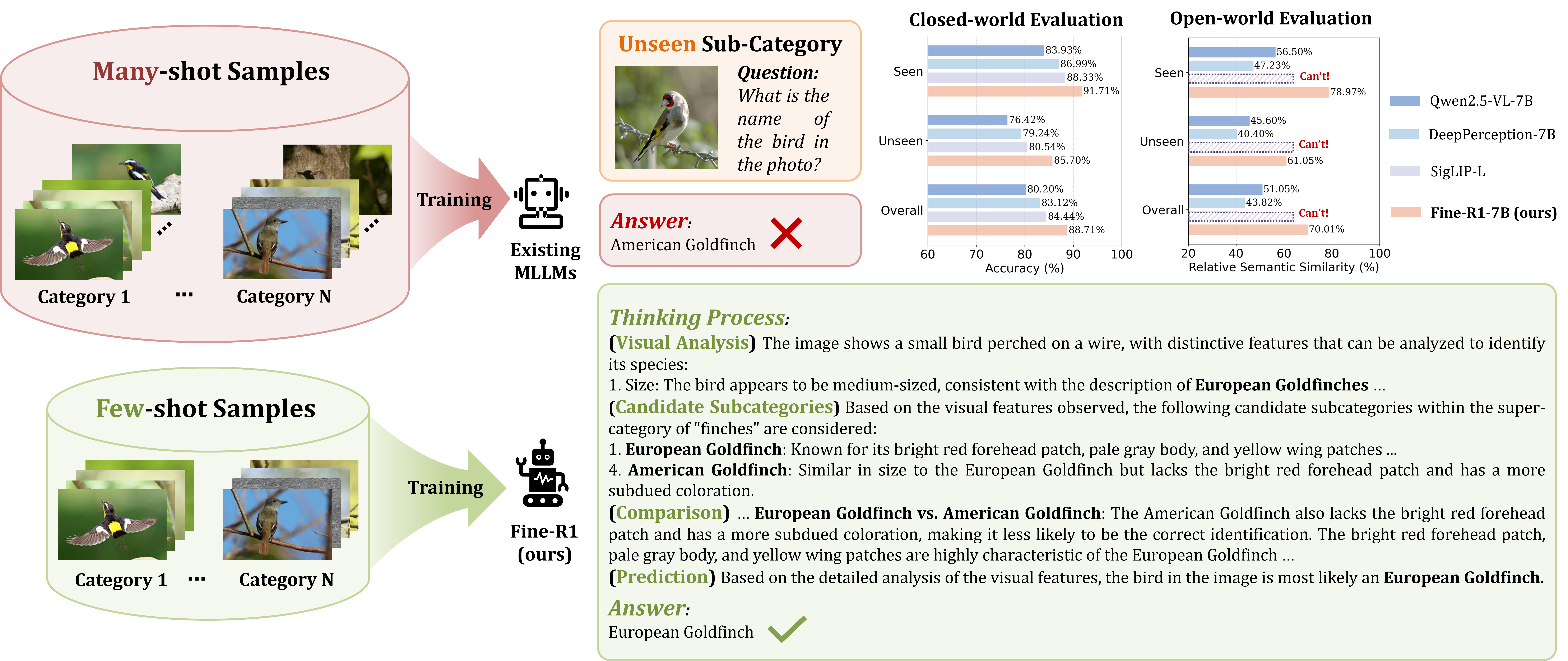
多模态大模型的细粒度视觉识别能力依赖大量训练数据,但由于细粒度标注数据收集难度高、标注成本大,无法满足大模型训练所需的标注数据规模。此外,大模型在包含有限子类别的数据上训练后,难以泛化到训练集外的子类别,无法识别不限定范围的开放域细粒度子类别。
针对上述问题,本文提出了思维链推理增强的细粒度视觉识别大模型Fine-R1,通过思维链监督微调与三元组增强策略优化,提升了大模型运用训练集已有细粒度子类别知识推理未见子类别的能力,主要包含两个构建步骤:(1)思维链监督微调:模拟人类的思考过程,构建“视觉分析-候选子类别-对比分析-预测结果”的结构化思维链,通过少样本监督微调,为多模态大模型快速构建推理能力;(2)三元组增强策略优化:在强化微调过程中,选取正样本(同一子类别)和负样本(不同子类别),通过引入正样本的思考轨迹,提升大模型对类内差异的鲁棒性,通过最大化输入图像与负样本的预测分布差异,提升大模型对类间差异的辨识性。实验结果表明,在每类仅需4张训练图像的情况下,本方法对训练集内外子类别的识别准确率均超越了OpenAI的CLIP、谷歌DeepMind的SigLIP等判别式模型。
该论文的第一作者是北京大学王选计算机研究所2023级博士生何胡凌霄,通讯作者是彭宇新教授。
(2)视觉语言大模型在细粒度图像任务上的系统评测
Benchmarking Large Vision-Language Models on Fine-Grained Image Tasks: A Comprehensive Evaluation
作者:于泓涛(东南大学),魏秀参(东南大学),彭宇新(北京大学),Serge Belongie(哥本哈根大学)
通讯作者:魏秀参
论文链接:https://openreview.net/pdf?id=cVc74MLspe
源代码链接:https://github.com/SEU-VIPGroup/FG-BMK
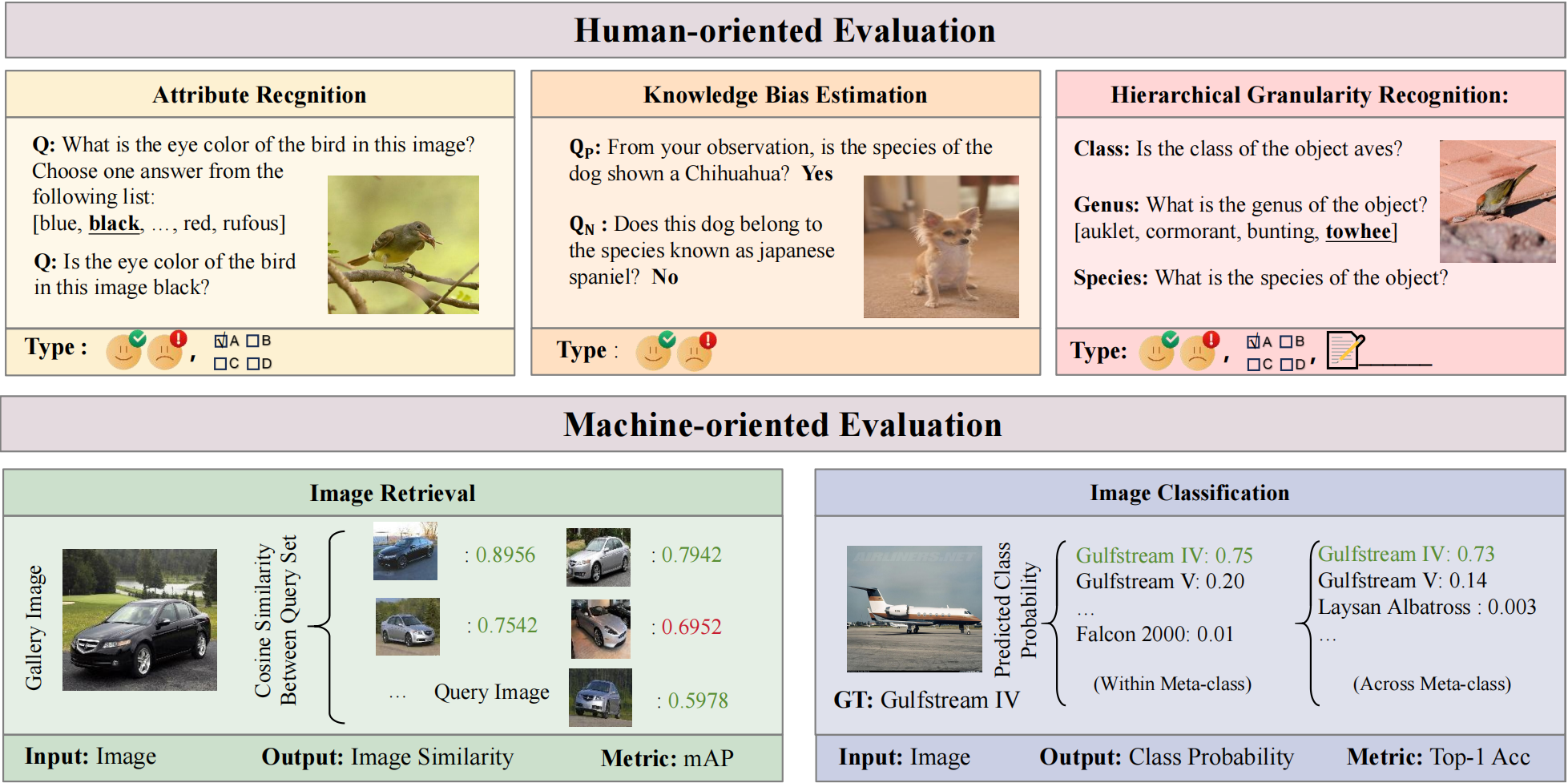
随着视觉语言大模型(LVLM)的快速发展,它们在通用视觉感知与推理任务上表现出色,但在细粒度视觉任务这一视觉基础问题上的能力边界尚不清晰。
针对上述问题,本文提出了一个综合性的细粒度能力评测基准FG-BMK,包含超过1,000,000条问题与280,000张图像,从人类交互与特征表征两个视角对12个模型进行系统评测,分别评估其在对话式细粒度视觉理解任务与视觉特征判别任务上的表现。为保证数据质量与多样性,FG-BMK涵盖多个细粒度数据源,覆盖多领域与层级粒度。
基于大规模实验,本文得到了一系列对“训练范式—对齐机制—鲁棒性—推理能力”的结论与启示:(1)大模型训练过程中的对比学习范式能显著提升视觉特征的表征能力,而生成/重建范式的效果则稍显逊色。(2)图文粒度不匹配(一图胜千言)的视觉-文本对齐会削弱视觉特征的表征能力,揭示了当前LVLM对齐策略在细粒度场景下的局限性。(3)相较于传统卷积模型,视觉语言大模型在细粒度任务中对特征扰动更为敏感,整体鲁棒性更弱。(4)LVLM的细粒度属性感知能力不均衡:对颜色与纹理等外观属性感知能力较强,对形状等结构属性感知能力较差。(5)LVLM在细粒度任务上的整体表现仍弱于细粒度垂域模型,相关能力仍有较大的提升空间。
这些发现系统揭示了当前视觉语言大模型在细粒度视觉任务中的局限,为后续提升LVLM的细粒度视觉能力奠定了评测基础与研究框架。
该论文的第一作者是东南大学2025级博士生于泓涛,通讯作者是魏秀参教授。