
2026-01-26:MIPL的1篇论文被TIP期刊接收
IEEE Transactions on Image Processing (TIP)是图像处理与计算机视觉领域的国际学术期刊,中国计算机学会(CCF)推荐的A类期刊,主要关注图像与视频处理、分析、增强及相关算法等前沿研究,影响因子13.7。
MIPL有1篇论文被接收,研究自动驾驶语义补全。
MRA: 基于相机的自动驾驶语义场景补全中面向体素稀疏性的多分辨率对齐方法
MRA: Multi-Resolution Alignment for Voxel Sparsity in Camera-Based 3D Semantic Scene Completion
作者:杨至文(博士生),彭宇新
通讯作者:彭宇新
源代码链接:https://github.com/PKU-ICST-MIPL/MRA_TIP
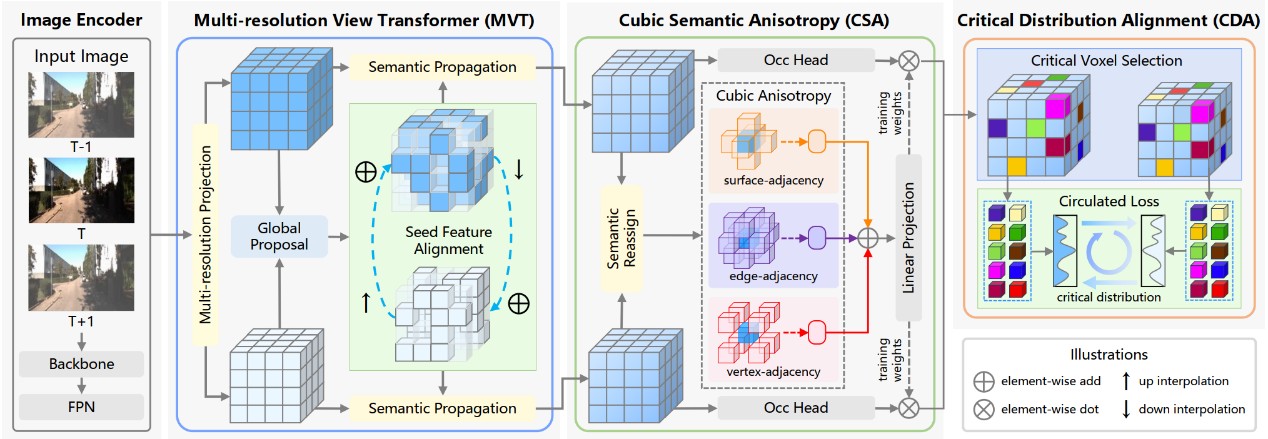
基于相机的3D语义场景补全(Camera-based 3D Semantic Scene Completion, SSC)旨在仅通过2D图像输入来预测3D场景中每个体素的几何占据情况和语义类别,为自动驾驶系统的感知、预测和规划提供了体素级的场景理解基础。尽管现有方法已取得显著进展,但其优化过程完全依赖体素标签的监督,且面临“体素稀疏性”(Voxel Sparsity)挑战——自动驾驶场景中绝大多数(超过92.9%)的体素处于未被占用状态,导致被占用区域的梯度传播受限,这既限制了优化效率,也制约了模型性能。
针对上述挑战,本文提出了一种面向体素稀疏性的多分辨率对齐方法MRA,旨在挖掘多分辨率3D特征间的场景级和实例级一致性作为辅助监督信号。具体来说,本文首先提出了多分辨率视角转换器(MVT),将2D图像特征投影为多分辨率3D特征,并通过融合判别性的种子特征实现场景级的初步对齐;其次,设计了立方语义各向异性(CSA)模块,通过语义重分配和聚合立方邻域内的语义差异,精准量化每个体素的实例级语义显著性;最后,提出了关键分布对齐(CDA)模块,在CSA的指导下筛选出关键体素作为锚点,并应用循环损失对不同分辨率下的关键特征分布一致性进行约束。这种自对齐机制提供了互补的监督信号,有效缓解了稀疏标签带来的优化难题。实验结果表明,本方法在常用自动驾驶数据集SemanticKITTI和SSCBench-KITTI-360上均取得了很大的性能提升。
该论文的第一作者是北京大学王选计算机研究所2022级博士生杨至文,通讯作者是彭宇新教授。
MIPL有1篇论文被接收,研究自动驾驶语义补全。
MRA: 基于相机的自动驾驶语义场景补全中面向体素稀疏性的多分辨率对齐方法
MRA: Multi-Resolution Alignment for Voxel Sparsity in Camera-Based 3D Semantic Scene Completion
作者:杨至文(博士生),彭宇新
通讯作者:彭宇新
源代码链接:https://github.com/PKU-ICST-MIPL/MRA_TIP
基于相机的3D语义场景补全(Camera-based 3D Semantic Scene Completion, SSC)旨在仅通过2D图像输入来预测3D场景中每个体素的几何占据情况和语义类别,为自动驾驶系统的感知、预测和规划提供了体素级的场景理解基础。尽管现有方法已取得显著进展,但其优化过程完全依赖体素标签的监督,且面临“体素稀疏性”(Voxel Sparsity)挑战——自动驾驶场景中绝大多数(超过92.9%)的体素处于未被占用状态,导致被占用区域的梯度传播受限,这既限制了优化效率,也制约了模型性能。
针对上述挑战,本文提出了一种面向体素稀疏性的多分辨率对齐方法MRA,旨在挖掘多分辨率3D特征间的场景级和实例级一致性作为辅助监督信号。具体来说,本文首先提出了多分辨率视角转换器(MVT),将2D图像特征投影为多分辨率3D特征,并通过融合判别性的种子特征实现场景级的初步对齐;其次,设计了立方语义各向异性(CSA)模块,通过语义重分配和聚合立方邻域内的语义差异,精准量化每个体素的实例级语义显著性;最后,提出了关键分布对齐(CDA)模块,在CSA的指导下筛选出关键体素作为锚点,并应用循环损失对不同分辨率下的关键特征分布一致性进行约束。这种自对齐机制提供了互补的监督信号,有效缓解了稀疏标签带来的优化难题。实验结果表明,本方法在常用自动驾驶数据集SemanticKITTI和SSCBench-KITTI-360上均取得了很大的性能提升。
该论文的第一作者是北京大学王选计算机研究所2022级博士生杨至文,通讯作者是彭宇新教授。