2025-09-26:MIPL的1篇论文被CJE(即《电子学报(英文版)》)接收
北京大学多媒体信息处理研究室(MIPL)共有1篇论文被接收,研究自动驾驶语义场景补全。
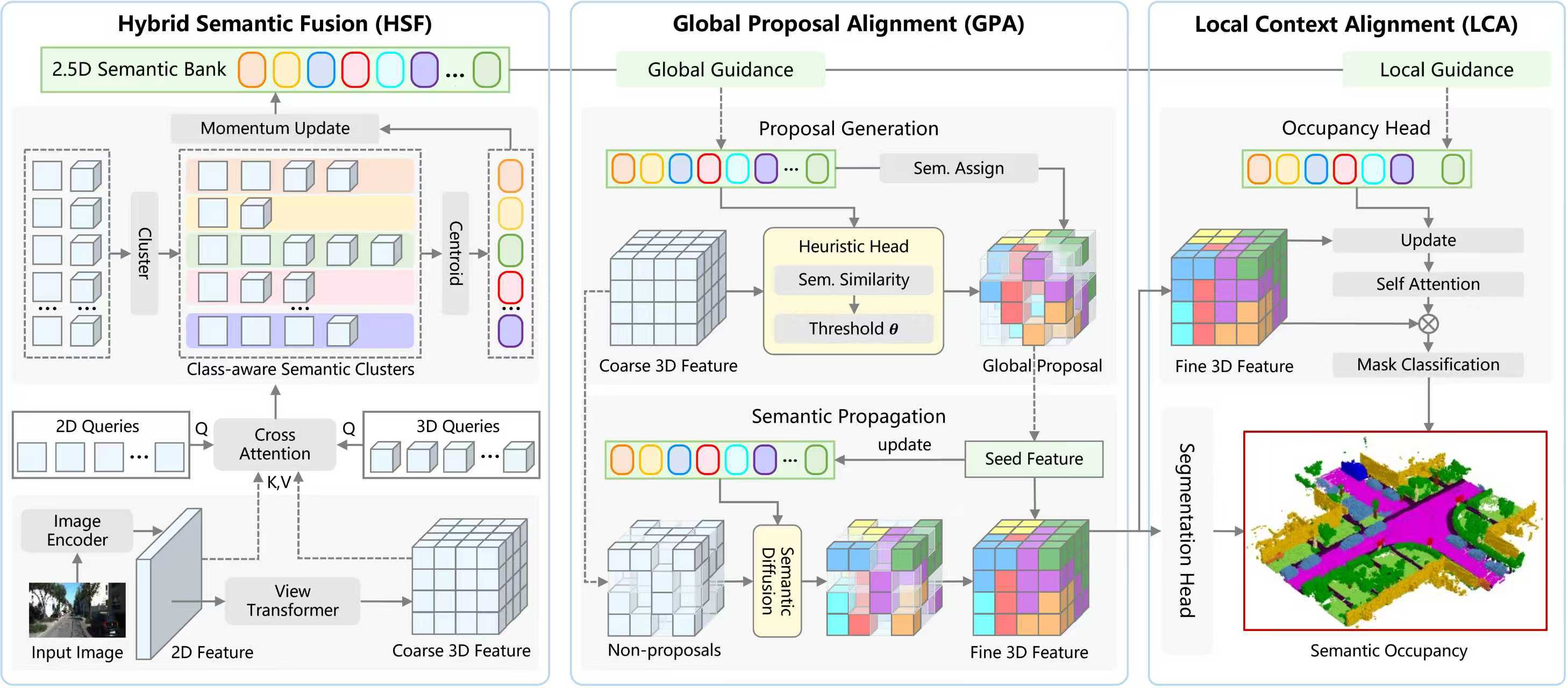
(1)GaLa-2.5D: 用于自动驾驶中基于摄像头的 3D 语义场景补全的 2.5D 语义引导全局-局部对齐
GaLa-2.5D: Global-Local Alignment with 2.5D Semantic Guidance for Camera-based 3D Semantic Scene Completion in Autonomous Driving
作者:杨至文(博士生),彭宇新
通讯作者:彭宇新
基于摄像头的自动驾驶语义场景补全旨在从多视角图像中重建完整的三维语义场景,即预测空间中每个体素的几何占用状态与语义类别,实现对复杂环境的精细感知与重建,在自动驾驶、机器人导航等场景中具有重要的研究和应用价值。然而,现有的自动驾驶语义场景补全方法主要依赖复杂的基于体素的 3D 模型来处理投影得到的体素特征,但却忽略了视角转换过程中2D图像特征和3D体素特征之间的细粒度语义不一致的问题。
针对上述挑战,本文引入了基于 2.5D 语义引导的全局-局部对齐 (GaLa-2.5D) 框架,该框架通过一个 2.5D 语义库保持一致的细粒度语义,为对齐的视角转换和精确的场景补全提供全局和局部引导。具体来说,为了在视角转换中保留细粒度语义,本文首先使用一个混合语义融合模块,该模块维护一个动态更新的 2.5D 语义库,从 2D 和 3D 特征中查询和聚类对齐的语义。然后,本文设计了一个全局提议对齐模块,该模块利用 2.5D 语义的全局引导动态过滤种子体素,在整个场景中分配细粒度语义。最后,本文提出了一个局部上下文对齐模块,该模块在 2.5D 语义的局部引导下对齐上下文几何结构和语义相关性,减少场景补全中的歧义。实验结果表明,本方法在常用自动驾驶数据集SemanticKITTI和SSCBench-KITTI-360上均取得了性能提升。
该论文的第一作者是北京大学王选计算机研究所2022级博士生杨至文,通讯作者是彭宇新教授。