2025-02-27:MIPL的7篇论文被CVPR 2025接收
MIPL共有7篇论文被接收,研究终身行人重识别、细粒度视觉理解、海报广告生成、视频运动迁移、视频提示学习、在线提示学习、视频配音生成。
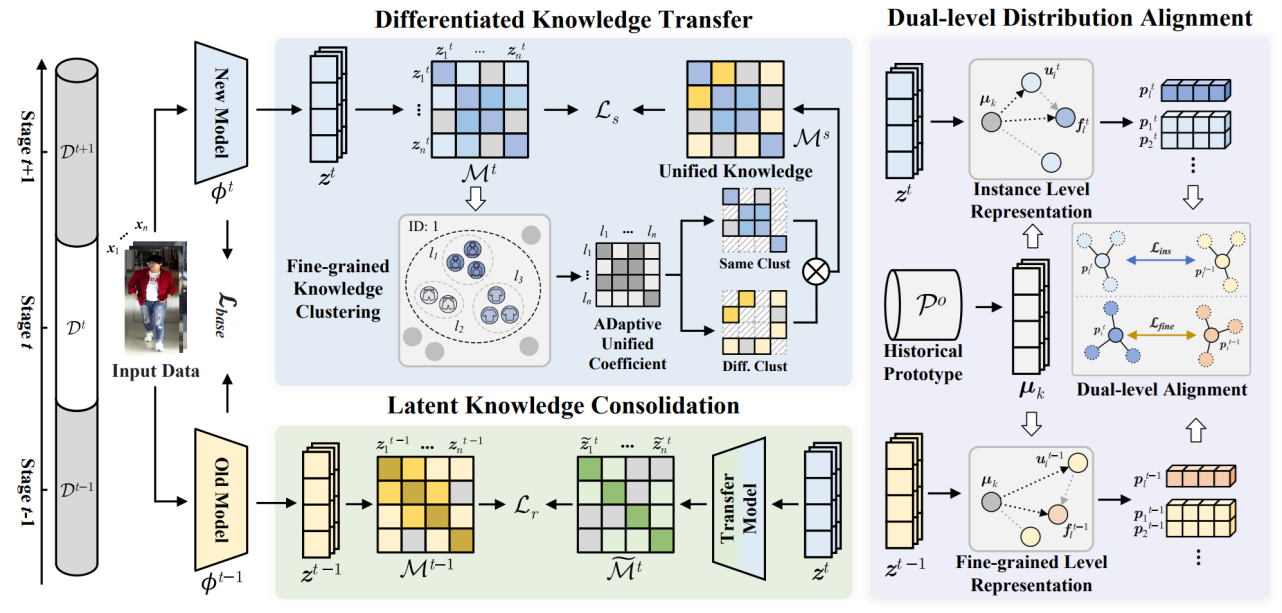
(1)DKC: 基于差异化知识巩固的换装终身行人重识别
DKC: Differentiated Knowledge Consolidation for Cloth-Hybrid Lifelong Person Re-identification
作者:崔振宇(博士生),周嘉欢,彭宇新
通讯作者:彭宇新
论文链接:https://ieeexplore.ieee.org/document/11095097
源代码链接:https://github.com/PKU-ICST-MIPL/DKC-CVPR2025
终身行人重识别旨在持续学习新增数据中的行人匹配知识。然而,在终身学习过程中,行人服装会发生不定期变化,要求模型能够累积相互冲突的行人服装与非服装知识。为克服该问题,本文引入了换装行人重识别任务(Cloth-Hybrid Lifelong Person Re-identification),旨在利用持续到来的换装和非换装数据进行终身行人重识别。然而,现有方法仅考虑了单一知识的巩固,无法兼顾多种相互冲突的知识,因而对不同场景的处理能力受限。
针对上述挑战,本文提出了一种基于差异化知识巩固的终身行人重识别方法,通过选择性地学习和巩固差异化的新旧知识,促进换装和非换装数据中相互冲突的行人鉴别性知识的学习与保留。具体贡献如下:(1)差异化知识转移:通过细粒度自聚类自动发现冲突的新知识,并选择性地将其与旧知识融合用于新知识学习,促进了差异化旧知识的发现与获取。(2)潜在知识巩固:利用更新后的深度特征对旧特征进行重构,缓解模型在学习包含冲突的新知识后,模型对旧知识产生的遗忘。(3)多层次知识分布对齐:在不同特征分布层级中,对齐并整合具有差异的新旧知识,实现冲突知识共存。本文方法在构建的多个换装行人重识别基准测试中取得了优于现有方法的性能。
该论文的第一作者是北京大学王选计算机研究所2021级博士生崔振宇,通讯作者是彭宇新教授。
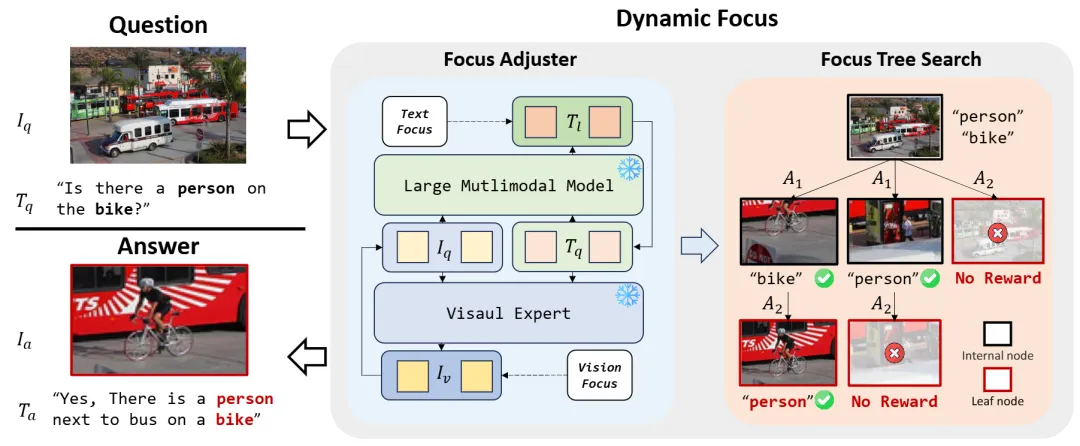
(2)DyFo: 基于动态聚焦的训练无关视觉搜索方法
DyFo: A Training-Free Dynamic Focus Visual Search for Enhancing LMMs in Fine-Grained Visual Understanding
作者:李耕(博士生),徐婧林,赵韫禛,彭宇新
通讯作者:彭宇新
论文链接:https://ieeexplore.ieee.org/document/11093219
源代码链接:https://github.com/PKU-ICST-MIPL/DyFo_CVPR2025
随着多模态大模型(LMMs)不断取得突破,其在“图像思考(thinking with images)”等复杂视觉推理任务中的潜力日益凸显。然而,当前主流开源LMMs仍依赖“看图回答”范式,难以应对高分辨率图像和复杂场景中的细粒度理解任务,存在聚焦不准、信息冗余和幻觉生成等问题。现有解决方案多依赖额外训练或对模型结构进行改动,缺乏通用性和工程可复用性。
针对上述挑战,本文提出DyFo(Dynamic Focus),一种训练无关、即插即用的动态聚焦视觉搜索方法。其核心思想是模拟人类视觉搜索行为,通过视觉专家模型与多模态大模型的协同,引入蒙特卡洛树搜索(MCTS)策略,在无需额外训练的前提下,逐步聚焦图像关键区域,有效过滤无关信息,提升细粒度理解能力。具体贡献如下:(1)聚焦调节器:设计语义聚焦与语义发散两类动作机制,联合LMM与视觉专家动态调整关注区域,模拟人类视觉中的聚焦与扩展策略;(2)聚焦树搜索:引入蒙特卡洛树搜索算法构建聚焦路径,在选择、扩展与反向传播的三阶段中高效探索最优聚焦策略;(3)异步推理架构:DyFo具备良好的模块化兼容性与工程可扩展性,支持多策略灵活组合并提升推理效率;(4)通用性与性能:DyFo无需修改基础模型结构,能够直接增强LLaVA-1.5、Qwen2-VL等主流LMMs,并在POPE与V* Bench等多个细粒度理解基准上取得显著性能提升。实验结果表明,DyFo在COCO、AOKVQA、GQA等多个POPE子集上减少幻觉生成,提升理解准确率;在V* Bench上,超越SEAL等专用聚焦方法,展示出对复杂高分辨率场景下细粒度目标识别与空间推理能力。
该论文的第一作者是北京大学王选计算机研究所2023级博士生李耕,通讯作者是彭宇新教授,论文已被CVPR 2025接收为Highlight(前13.5%),代码已于GitHub开源。
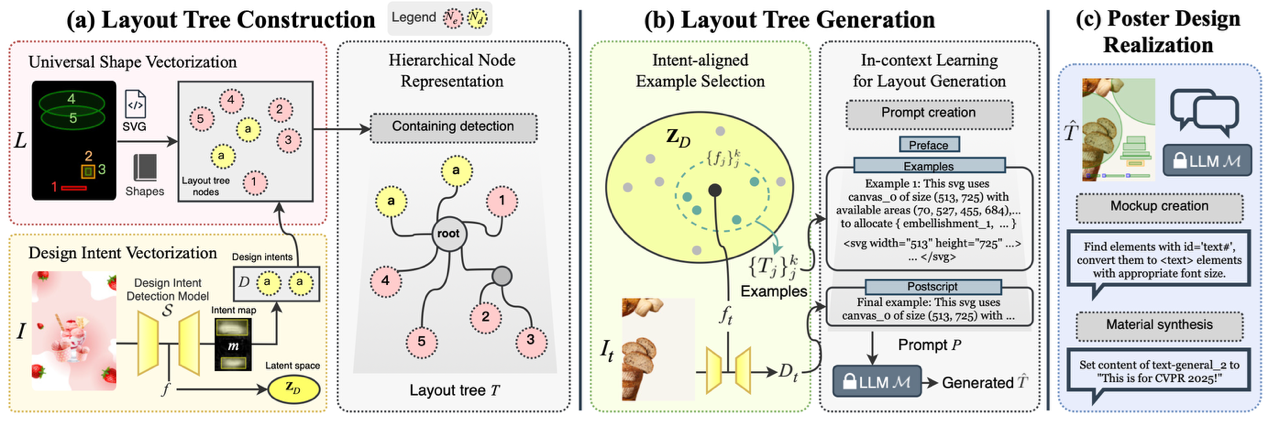
(3)PosterO: 基于布局树结构化表示的内容感知图文布局生成方法
PosterO: Structuring Layout Trees to Enable Language Models in Generalized Content-Aware Layout Generation
作者:徐筱媛(硕士生),彭宇新
通讯作者:彭宇新
论文链接:https://ieeexplore.ieee.org/document/11093816
源代码链接:https://github.com/PKU-ICST-MIPL/PosterO-CVPR2025
在AI海报设计中,图文布局生成旨在根据给定图像,自动编排符合设计意图、包含任意形状元素的图文布局,设计Logo、文本等元素的位置、大小与样式,实现海报自动生成。现有方法大多采用以图像中心的方案,严重依赖数据驱动的生成模型,主要面临如下2大局限性:(1)布局多样性低:现有方法过度依赖图像显著性等先验信息,容易陷入局部最优解,导致生成的布局同质化,难以适应不同场景下不同的设计意图。(2)布局表示能力弱:传统布局表示仅支持单一的矩形元素,且视觉约束与布局元素割裂,无法描述复杂的元素形状(如曲线、椭圆等)与图文间的关系。
针对上述问题,本文提出了一种基于布局树结构化表示的内容感知图文布局生成方法PosterO,具体分为3个部分:(1)布局树构建:将图像-布局数据对中的元素统一为结构化的SVG树,通过通用形状向量化支持曲线、椭圆等任意形状,同时通过设计意图向量化将图像中的可用设计区域作为视觉约束融入树中,并通过层级节点表示显式建模元素间的包含关系,最终将设计数据转化为大语言模型可理解的语言格式。(2)布局树生成:在推理阶段,针对给定的测试图像,首先从范例库中动态选取少量布局树作为上下文示例,然后利用大语言模型的上下文学习能力,生成与测试图像内容相匹配的新布局树。(3)版面设计:在生成布局树后,将结构化的布局树转化为包含具体设计素材(如Logo、文本)的海报。实验结果表明,本方法在主流图文布局生成数据集CGL和PKU PosterLayout上布局生成质量相比现有最佳方法分别提升了40.1%和31.1%。
该论文的第一作者是北京大学王选计算机研究所2022级硕士生徐筱媛,通讯作者是彭宇新教授。
(4)基于可控运动解耦与重组的零样本运动迁移框架
ConMo: Controllable Motion Disentanglement and Recomposition for Zero-Shot Motion Transfer
作者:高嘉怿(实习生), 尹子进, 花昌诚, 彭宇新, 梁孔明, 马占宇, 郭军, 刘洋
通讯作者:刘洋
论文链接:https://ieeexplore.ieee.org/document/11094968
源代码链接:https://github.com/Andyplus1/ConMo
文本到视频(Text-to-Video, T2V)生成技术的发展推动了运动迁移的实现,使其能够基于现有视频素材控制生成视频的运动状态。然而,当前运动迁移方法存在两大局限:(1)难以处理多主体视频场景,无法精准迁移特定主体的运动特征;(2)当迁移对象为不同形状的主体时,难以保留运动的多样性与准确性。
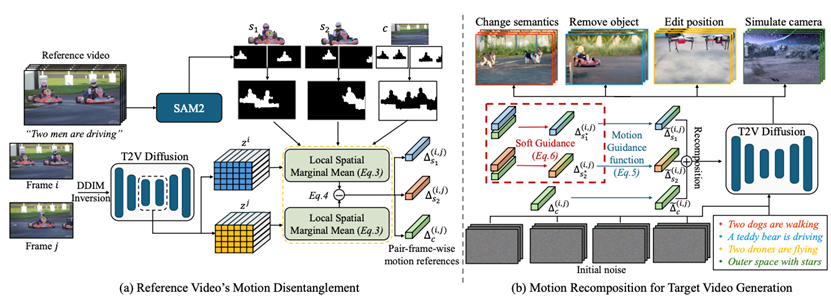
针对上述挑战,本文提出一种零样本运动迁移框架 ConMo,通过对主体运动与相机运动进行解耦和重组,实现更灵活的运动控制。该框架仅借助主体掩码,即可从源视频的复杂轨迹中分离出个体主体与背景的运动线索,并将这些线索重组用于目标视频生成。具体贡献如下:(1)运动解耦机制:通过主体掩码实现复杂场景中各主体运动与背景运动的精准分离,为多主体场景的运动迁移提供基础;(2)软引导重组策略:在重组阶段引入软引导机制,通过控制原始运动的保留程度调整形状约束,助力主体形状适应与语义转换;(3)多场景应用拓展:突破传统方法限制,支持主体大小与位置编辑、主体移除、语义修改及相机运动模拟等多样化应用。实验结果表明,ConMo 在运动保真度和语义一致性方面取得了优于现有方法的性能。
该论文的第一作者是北京大学王选计算机研究所实习生高嘉怿,通讯作者是刘洋助理教授,与彭宇新教授合作完成。
(5)STOP: 面向视频理解的空间-时间动态提示集成
STOP: Integrated Spatial-Temporal Dynamic Prompting for Video Understanding
作者:刘子宸(硕士生),徐昆仑,苏冰,邹旭,彭宇新,周嘉欢
通讯作者:周嘉欢
论文链接:https://ieeexplore.ieee.org/document/11094049
源代码链接:https://github.com/zhoujiahuan1991/CVPR2025-STOP
通过大规模图像-文本对预训练的CLIP等视觉-语言模型已在众多图像任务中展现出优异的性能。然而,将这些模型扩展到视频任务中仍然面临挑战,主要原因在于标注视频数据的匮乏以及高昂的训练成本。近期的研究尝试通过引入可学习的提示,将CLIP适应视频任务,但这些方法通常采用单一静态提示来处理所有视频序列,忽视了跨帧的时间动态和空间变化,严重限制了模型对视频理解所需时间信息的提取和利用能力。
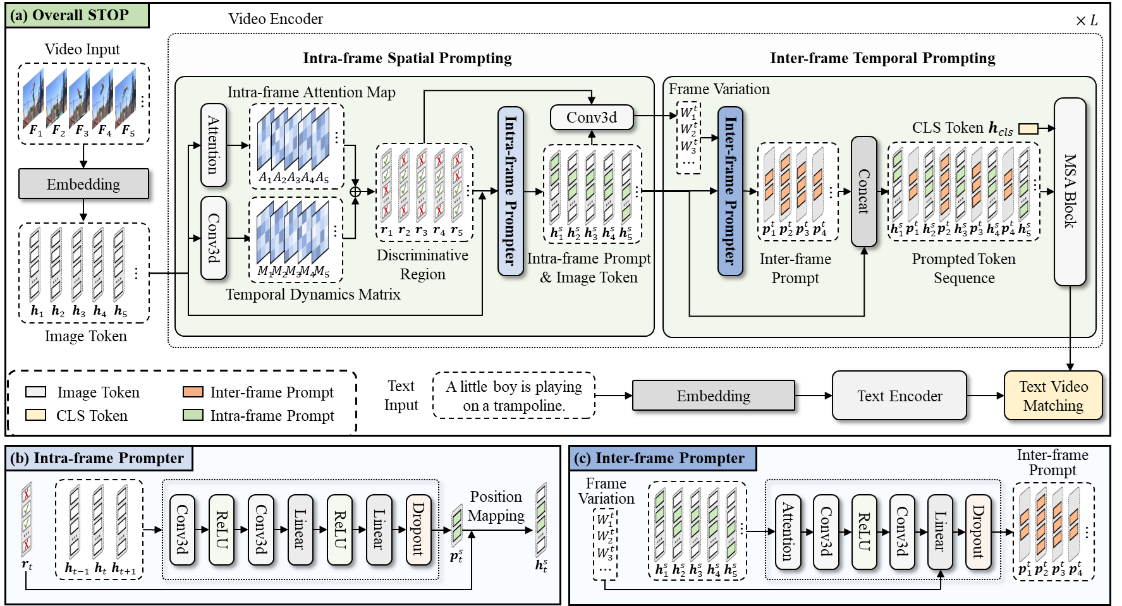
针对上述挑战,本文提出了一种面向视频理解的空间-时间动态提示集成方法STOP,旨在通过多层级提示设计引导CLIP模型关注视频数据中的动态区域以增强其对行为和事件的理解。具体贡献如下:(1)帧内空间提示生成器:基于3D卷积结构生成针对动态区域的空间提示,指导模型关注具有显著时间变化的区域,从而增强模型对视频数据中细粒度信息的捕捉能力。(2)帧间时间提示生成器:考虑到视频帧之间的动态变化不同,这会影响帧对视频理解的重要性,本文提出了帧间时间提示,以帮助预训练模型关注关键帧。(3)帧内帧间协同提示:首先基于帧内空间提示识别出的判别区域,进而计算这些区域在不同帧之间的变化程度,对于具有显著时间动态变化的关键帧,利用轻量级的提示生成器动态生成帧间提示,并将其插入到两帧之间,提供细粒度的时间信息,帮助模型聚焦并理解关键帧。帧内空间提示和帧间时间提示相互补充,指导模型关注关键的空间和时间位置,从而提升其对视频的准确理解。多个视频基准测试中的大量实验表明,STOP相比于现有方法展现出性能优势。
该论文的第一作者是北京大学王选计算机研究所2022级硕士生刘子宸,通讯作者是周嘉欢助理教授,与彭宇新教授合作完成。
(6)SCAP: 基于支撑集合属性提示学习的测试时自适应
SCAP: Transductive Test-Time Adaptation via Supportive Clique-based Attribute Prompting
作者:张宸语(本科生),徐昆仑(博士生),刘子宸,彭宇新,周嘉欢
通讯作者:周嘉欢
论文链接:https://ieeexplore.ieee.org/document/11094895
源代码链接:https://github.com/zhoujiahuan1991/CVPR2025-SCAP
智能算法模型在测试阶段面对未知数据分布时,往往会发生显著的性能退化。为克服该问题,测试时适应(Test-Time Adaptation, 简称为TTA)近年来受到学界关注,其目标为在测试阶段动态调整预训练模型以应对测试数据分布偏移问题。然而,现有TTA方法主要针对单个测试样本进行独立优化,难以保障所学知识对不同样本的泛化能力,导致更新的模型性能受限。
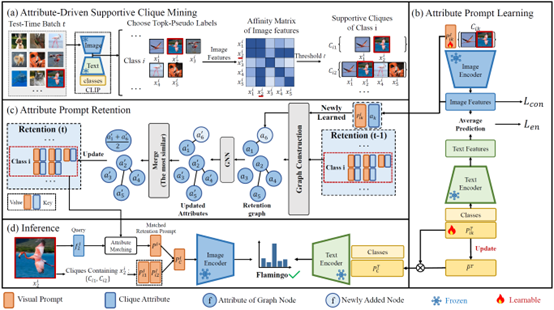
针对上述挑战,本文提出了一种基于支撑集合属性提示学习的测试时自适应方法,通过挖掘批次数据中的视觉相似性和语义关联性,促进模型对测试域中目标鉴别性特征的学习。具体贡献如下:(1)支撑集合挖掘:利用CLIP的视觉编码器提取图像特征,并通过计算跨样本特征相似性矩阵自动构建支撑集合。(2)属性提示学习:为每个支撑集合学习视觉和文本模态的属性提示,分别用于提取图像和文本模态中的共享特征。(3)属性知识保存:通过构建属性提示池动态存储历史属性提示,为了避免属性提示数量持续膨胀,引入了基于图网络的属性信息交互机制,通过相似属性信息融合和冗余裁剪,实现利用有限的存储资源进行属性更新和扩展。本文方法在多个基准测试中取得了优于现有方法的性能。
该论文的共同第一作者是北京大学王选计算机研究所2022级本科生张宸语和2023级博士生徐昆仑,通讯作者是周嘉欢助理教授,与彭宇新教授合作完成。
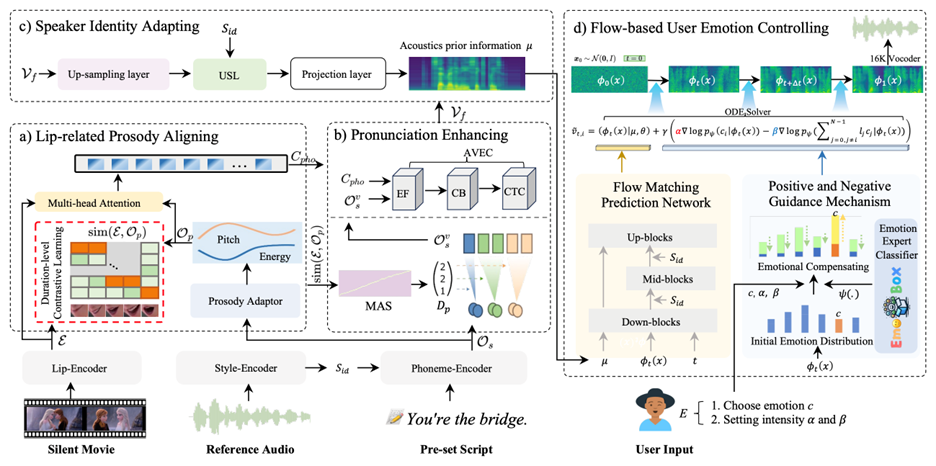
(7)EmoDubber: 面向情绪可控的高质量视频配音方法
EmoDubber: Towards High Quality and Emotion Controllable Movie Dubbing
作者:丛高翔(博士生),潘佳栋,李亮,齐元凯,彭宇新,Anton van den Hengel,杨坚,黄庆明
通讯作者:李亮
论文链接:https://ieeexplore.ieee.org/document/11093271
源代码链接:https://github.com/GalaxyCong/EmoDubber
视频配音又称为视觉声音克隆,旨在将给定文本转换为具有特定音色的语音,同时与视频中角色的嘴唇动作保持同步。它在电影制作、数字媒体和个性化语音AIGC等领域有着广泛的实际应用。然而,当前主流配音方法存在两大局限:(1)难以同时保持视听同步和发音清晰;(2)缺乏表达用户自定义情绪的能力。
针对上述挑战,本文提出EmoDubber,一种情绪可控的配音生成架构,允许用户指定情绪类型和情绪强度,同时满足高质量的唇部同步和发音。具体贡献如下:(1)正负引导机制:引入一种基于 Flow Matching 的用户情绪控制策略,根据用户提供的情绪提示动态调整正负引导的尺度,并在Flow Matching的矢量场预测过程中确定情绪生成的梯度方向,从而放大目标情绪并抑制无关情绪;(2)唇部韵律对齐模块 :设计对比学习来建模唇部运动和音素韵律序列之间的语速关联,帮助模型推理出更鲁棒的视听对齐表示;(3)发音增强策略:引入单调对齐搜索算法将原始音素扩展为视频级音素序列,并使用Efficient Conformer模块将其与上下文嘴唇序列进行跨模态融合,以改善发音清晰度。实验结果表明,EmoDubber在GRID和Chem等多个视频配音数据集上的表现优于国际上同期最优方法。
该论文的第一作者是中国科学院计算技术研究所2024级博士生丛高翔,通讯作者是李亮研究员,与彭宇新教授合作完成,论文已被CVPR 2025接收为Highlight(前13.5%),代码已于GitHub开源https://github.com/GalaxyCong/EmoDubber。