2025-06-26:MIPL的4篇论文被ICCV 2025接收
北京大学多媒体信息处理研究室(MIPL)共有4篇论文被接收,成果覆盖点云分析、视频时序定位、开放词汇人物交互检测、弱监督动态场景图生成研究方向。
(1)UPP:基于统一点级提示的点云分析模型
UPP: Unified Point-Level Prompting for Enhanced Point Cloud Analysis
作者:艾子翔(博士生),崔振宇,彭宇新,周嘉欢
通讯作者:周嘉欢
论文链接:https://arxiv.org/abs/2507.18997
源代码链接:https://github.com/zhoujiahuan1991/ICCV2025-UPP
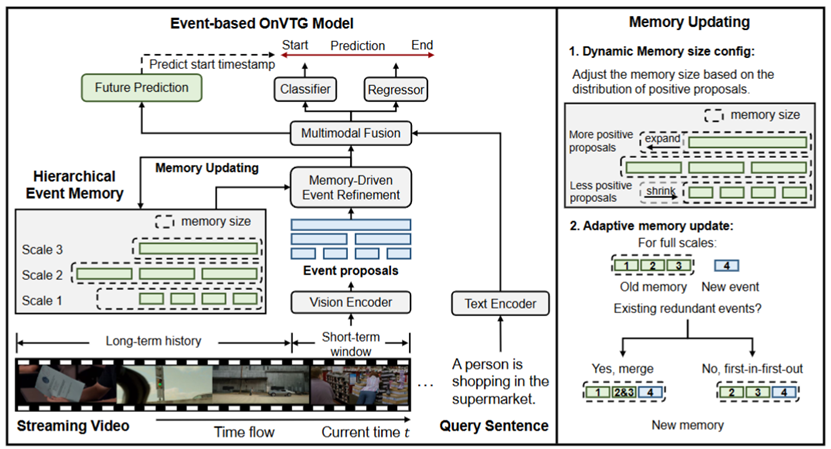
点云分析旨在使模型能够对输入的点云数据进行分类、分割、识别等一系列分析处理。然而,在真实场景中采集得到的点云数据不可避免地存在噪声和残缺问题,将严重降低下游点云分析处理任务的性能。现有方法主要通过多阶段处理的方式对点云数据依次进行去噪、补全和分析操作。然而:(1)点云去噪/补全的过程与下游分析处理任务脱节,导致对下游任务重要的几何特征被破坏;(2)多阶段的点云处理方法带来了较高的计算代价与模型参数,影响了点云分析处理效率。
针对上述挑战,本文提出一种用于增强点云分析处理的统一点级提示方法,通过参数高效的点云提示学习方法将点云去噪、补全和分析能力整合到统一模型中,实现了端到端的点云分析处理。具体贡献如下:(1)点级修正提示器:提出点级修正提示网络,预测并调整每个三维点云的噪声水平,从而滤除噪声为点云补全奠定基础;(2)点级补全提示器:提出点级补全提示网络,通过生成辅助的虚拟点云提示来应对不完整的点云数据,提供全面的几何信息。(3)形状感知单元:提出形状感知模块,对点级修正提示器和点级补全提示器输出的高质量点云进行集成增强,并将增强后的几何信息传递到下游任务,提升点云分析处理能力。实验结果表明,本方法在常用点云分析数据集ModelNet40和ShapeNet55上取得了性能提升。
该论文的第一作者是北京大学王选计算机研究所2025级博士生艾子翔,通讯作者是周嘉欢助理教授,与彭宇新教授合作完成。
(2)基于分层事件存储的在线视频时序定位模型
Hierarchical Event Memory for Accurate and Low-latency Online Video Temporal Grounding
作者:郑明航(博士生),彭宇新,孙本元,杨怡,刘洋
通讯作者:刘洋
论文链接:https://arxiv.org/pdf/2508.04546
源代码链接:https://github.com/minghangz/OnVTG
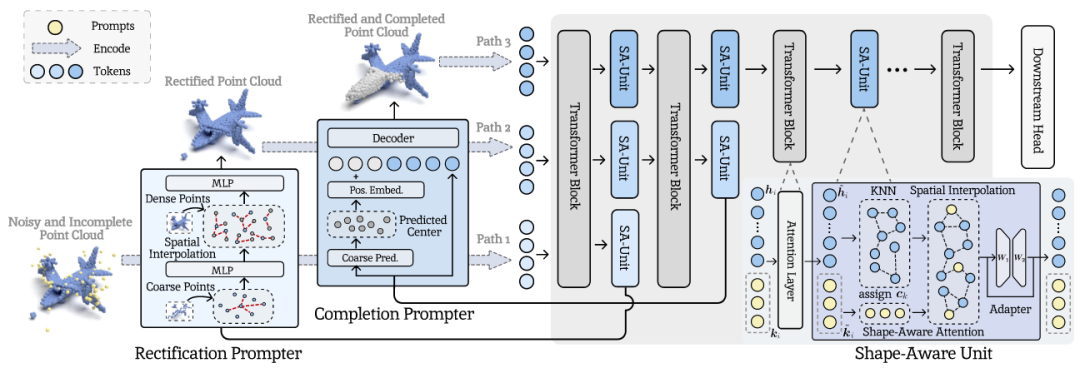
在线视频时序定位旨在让模型能在视频流中实时定位与给定文本查询相关的事件。但不同于常规视频时序定位,该任务要求模型在无法观测未来帧的情况下做出预测。由于在线视频是流式输入且可无限延续,存储所有历史输入既不现实也低效。现有方法主要采用固定大小的帧级别存储器来缓存近期视频帧。然而,这类方法存在局限性:(1) 缺乏有效的事件级别信息建模,导致定位性能不佳 ;(2) 无法保留长期的关键历史信息,从而影响定位的准确性;(3)事件的开始预测存在延迟,需要在事件即将结束时才能给出预测。
针对上述挑战,本文提出一种基于分层事件存储的在线视频时序定位方法,通过构建事件级别的视频表示,高效地利用长期历史信息 。具体贡献如下:(1) 分层事件存储:提出一种分层事件存储结构,能够同时保留近期的细粒度事件信息和长期的粗粒度事件信息,以适应不同尺度事件的定位需求 ;(2) 动态内存更新机制:提出动态内存大小配置与自适应更新规则,融合冗余事件以保留更关键的信息;(3) 预测目标事件是否即将发生并回归事件起始时间,解决事件起始预测延迟问题。实验结果表明,本方法在TACOS、ActivityNet Captions和MAD等主流数据集上取得了当前最佳性能。
该论文的第一作者是北京大学王选计算机研究所2022级博士生郑明航,通讯作者是刘洋助理教授,与彭宇新教授合作完成。
(3)基于交互感知提示和概念校准的开放词汇人物交互检测模型
Open-Vocabulary HOI Detection with Interaction-aware Prompt and Concept Calibration
作者:雷廷(博士生),殷绍峰,陈庆超,彭宇新,刘洋
通讯作者:刘洋
论文链接:https://arxiv.org/abs/2508.03207
源代码链接:https://github.com/ltttpku/INP-CC
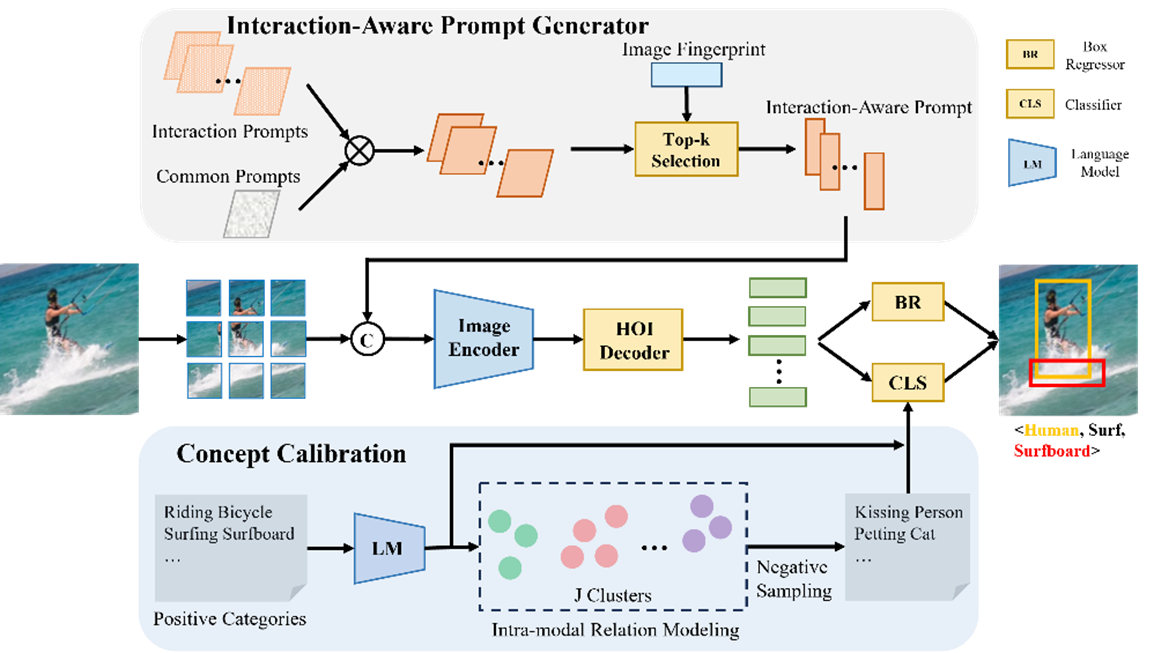
开放词汇人物检测旨在实现对任意已知和未知的人物交互的识别与理解。但不同于传统封闭词表下的人物交互检测,该任务要求模型具备识别未见交互类型的能力,并对细粒度语义差异做出准确判断。由于现实中的交互种类复杂多样,类别不断变化,依赖固定类别标签进行建模的方法难以适应开放场景的需求。现有方法虽引入CLIP等预训练视觉语言模型缓解该问题,但仍存在以下局限性:(1) 缺乏对关键交互区域的精细建模,导致对局部空间理解不足;(2) 文本编码能力有限,难以表达复杂细粒度交互语义,易混淆相似概念。
针对上述挑战,本文提出一种基于交互感知提示与概念校准的开放词汇人物交互检测方法,通过构建结构化提示和语义增强嵌入空间,有效提升模型对复杂交互的识别能力。具体贡献如下:(1) 交互感知提示生成机制:提出一种交互感知提示生成框架,结合通用提示与交互特定提示,引导视觉编码器聚焦关键交互区域,提升模型对局部空间交互的感知能力;(2) 交互概念校准机制:构建细粒度语义嵌入空间,通过语言模型生成交互描述并进行结构化聚类,同时在训练阶段引入困难负类别采样策略以增强模型区分相似交互的能力。实验结果表明,本方法在HICO-DET和SWIG-HOI等主流数据集上取得了当前最佳性能。
该论文的第一作者是北京大学王选计算机研究所2023级博士生雷廷,通讯作者是刘洋助理教授,与彭宇新教授合作完成。
(4)基于时序增强交互感知知识迁移的弱监督动态场景图生成模型
TRKT: Weakly Supervised Dynamic Scene Graph Generation with Temporal-enhanced Relation-aware Knowledge Transferring
作者:徐铸(博士生),雷廷,李智敏,王冠,陈庆超,彭宇新,刘洋
通讯作者:刘洋
论文链接:https://arxiv.org/abs/2508.04943
源代码链接:https://github.com/XZPKU/TRKT
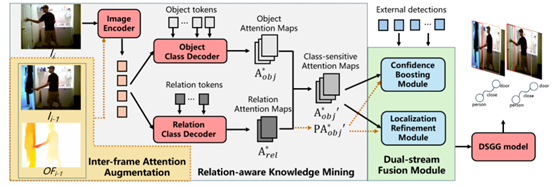
弱监督动态场景图生成任务旨在通过检测物体并预测它们之间的关系,为视频的每一帧生成对应场景图,并且只使用来自视频单帧的无物体位置信息的场景图标签作为监督进行训练。现有的弱监督动态场景图生成方法依赖于预训练的外部目标检测器生成物体标签,进而构造伪场景图标签用于后续场景图生成模型的训练。然而,在动态、关系感知的动态场景图生成场景中,训练于静态、以物体为中心图像上的目标检测器会出现物体定位不准确以及对部分物体置信度过低的问题,进而影响伪标签的质量和最终动态场景图的生成性能。
为了解决外部目标检测器带来的挑战,本文提出一种时序增强交互感知知识迁移方法,通过挖掘时序增强且交互感知的知识来增强在关系感知的动态场景中的目标检测性能。具体贡献如下:(1)交互感知知识挖掘模块:通过物体和关系类别解码器生成类别特定的注意力图,以突出物体区域和交互区域,从而使注意力图具备关系感知能力;(2)帧间注意力增强策略:利用邻近帧和光流信息增强注意力图,使其具备时序感知能力,并对运动模糊具有较强的鲁棒性;(3)双流融合模块:将类别特定的注意力图与外部检测结果相结合,提升物体定位精度和部分物体的置信度分数。实验结果表明,本方法在常用动态场景图生成数据集Action-Genome上取得了性能提升。
该论文的第一作者是北京大学王选计算机研究所2024级博士生徐铸,通讯作者是刘洋助理教授,与彭宇新教授合作完成。