2025-08-02:MIPL的2篇论文被TPAMI 2025接收
北京大学多媒体信息处理研究室(MIPL)共有2篇论文被接收,成果覆盖终身行人重识别研究方向。
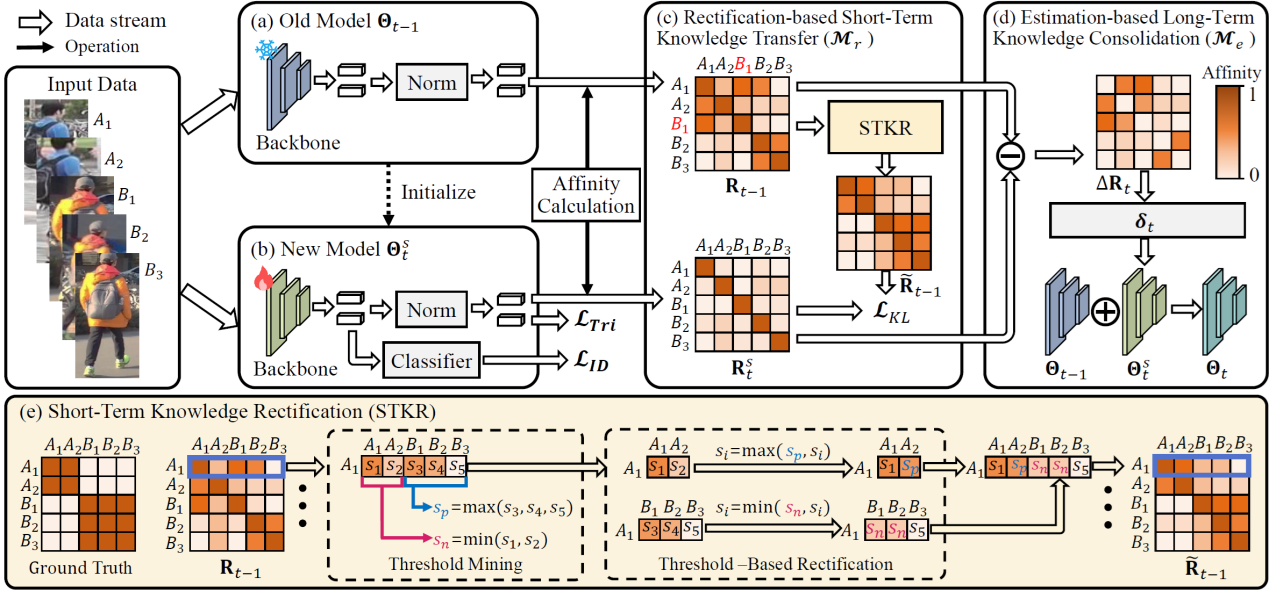
(1)LSTKC++: 长短期知识解耦与巩固驱动的终身行人重识别
Long Short-Term Knowledge Decomposition and Consolidation for Lifelong Person Re-Identification
作者:徐昆仑(博士生),刘子宸,邹旭,彭宇新,周嘉欢
通讯作者:周嘉欢
论文链接:https://ieeexplore.ieee.org/document/11010188
源代码链接:https://github.com/zhoujiahuan1991/LSTKC-Plus-Plus
终身行人重识别任务要求模型能够持续利用新增域数据进行训练,在学习新域知识的同时,维持对旧域数据的识别能力。该任务的核心挑战是灾难性遗忘问题,即模型在学习新域知识后,对旧域数据的识别性能发生退化。现有方法主要依赖知识蒸馏策略将旧模型知识迁移至新模型,然而,此类方法存在三个严重局限:(1)错误知识积累:受数据偏差等因素影响,旧模型中不可避免地包含错误知识。知识蒸馏过程会传递并累积这些错误知识,进而干扰新知识的学习。(2)正确知识遗忘:新旧域间的分布差异导致部分旧知识无法被新数据激活,致使这些知识难以通过知识蒸馏有效迁移至新模型。(3)无法自动权衡学习和遗忘:知识蒸馏约束缺乏与模型性能的直接关联,难以实现学习新知识与保留旧知识之间的最优权衡。
针对上述问题,提出了一种长短期知识解耦与巩固驱动的终身行人重识别方法。具体贡献如下:(1)知识纠正机制:在知识蒸馏过程中,利用新数据的标注信息纠正历史特征中的错误,从而缓解错误知识积累问题。(2)知识解耦权衡机制:将包含长期旧知识的单一模型解耦为长期旧模型与短期旧模型。该机制通过与知识纠正机制协同,不仅能够提取长短期互补特征以指导新知识学习,更支撑了最优权衡搜索算法的实现。该算法以新数据作为无偏基准,自动寻优并指导长短期知识迁移的最优权衡。实验结果表明,本方法在终身行人重识别数据集LReID上取得了性能提升。
该论文的第一作者是北京大学王选计算机研究所2023级博士生徐昆仑,通讯作者是周嘉欢助理教授,与彭宇新教授合作完成。
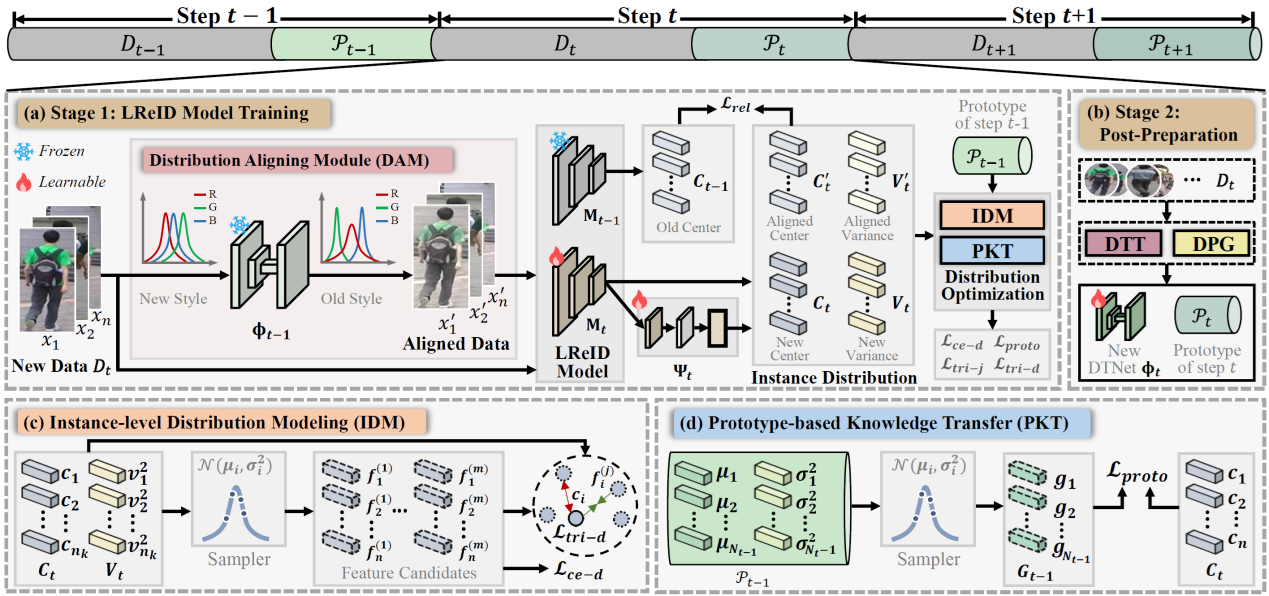
(2)DKP++: 基于分布知识对齐与原型建模的终身行人重识别
Distribution-aware Knowledge Aligning and Prototyping for Non-exemplar Lifelong Person Re-Identification
作者:周嘉欢(助理教授),徐昆仑,卓凡,邹旭,彭宇新
通讯作者:彭宇新
论文链接:https://ieeexplore.ieee.org/document/10655052
源代码链接:https://github.com/zhoujiahuan1991/TPAMI-DKP_Plus_Plus
终身行人重识别旨在使模型能够持续学习不断涌现的新行人数据中的鉴别性信息。该任务面临的核心挑战是灾难性遗忘-模型在学习新知识时,对旧数据的识别能力严重退化。现有方法主要通过保留历史样本或采用知识蒸馏策略来缓解遗忘。然而,(1)保留历史样本的方法存在数据隐私风险和持续增长的存储开销问题;(2)知识蒸馏方法因强制新旧模型输出一致性,往往限制了模型学习新知识的能力;(3)尽管原型学习在类增量学习中表现良好,但现有方法仅为每个类别保留单一特征中心,忽略了类内分布差异,导致行人的细粒度知识丢失,难以适用于依赖细粒度匹配的终身行人重识别任务。
针对上述挑战,本文提出一种无样本保留的终身行人重识别方法DKP++,其核心在于分布知识对齐与原型建模。具体贡献如下:(1)实例级细粒度建模:提出实例分布建模网络,动态捕捉行人实例的局部细节信息,为细粒度匹配奠定基础;(2)分布感知的原型生成:设计分布原型生成算法,将学习到的实例级分布信息聚合为更鲁棒的类别级分布原型,克服了单一特征中心的局限性,保留类内差异知识。(3)分布鸿沟弥合:引入输入端分布建模机制,对齐新旧数据的特征分布,提升了模型对历史知识的利用能力;(4)基于原型的知识迁移:提出基于原型的知识迁移模块,利用生成的分布原型和有标注的新数据协同指导模型学习,在促进新知识吸收的同时,实现了对旧知识的记忆。实验结果表明,本方法在终身行人重识别数据集LReID上取得了性能提升。
该论文的第一作者是北京大学王选计算机研究所助理教授周嘉欢,通讯作者是彭宇新教授。
相关报道链接:【机器之心报道】