2025-07-05:MIPL的2篇论文被ACM MM 2025接收
北京大学多媒体信息处理研究室(MIPL)共有2篇论文入选,成果覆盖三维占用预测、定制化人物交互图像生成等研究方向。
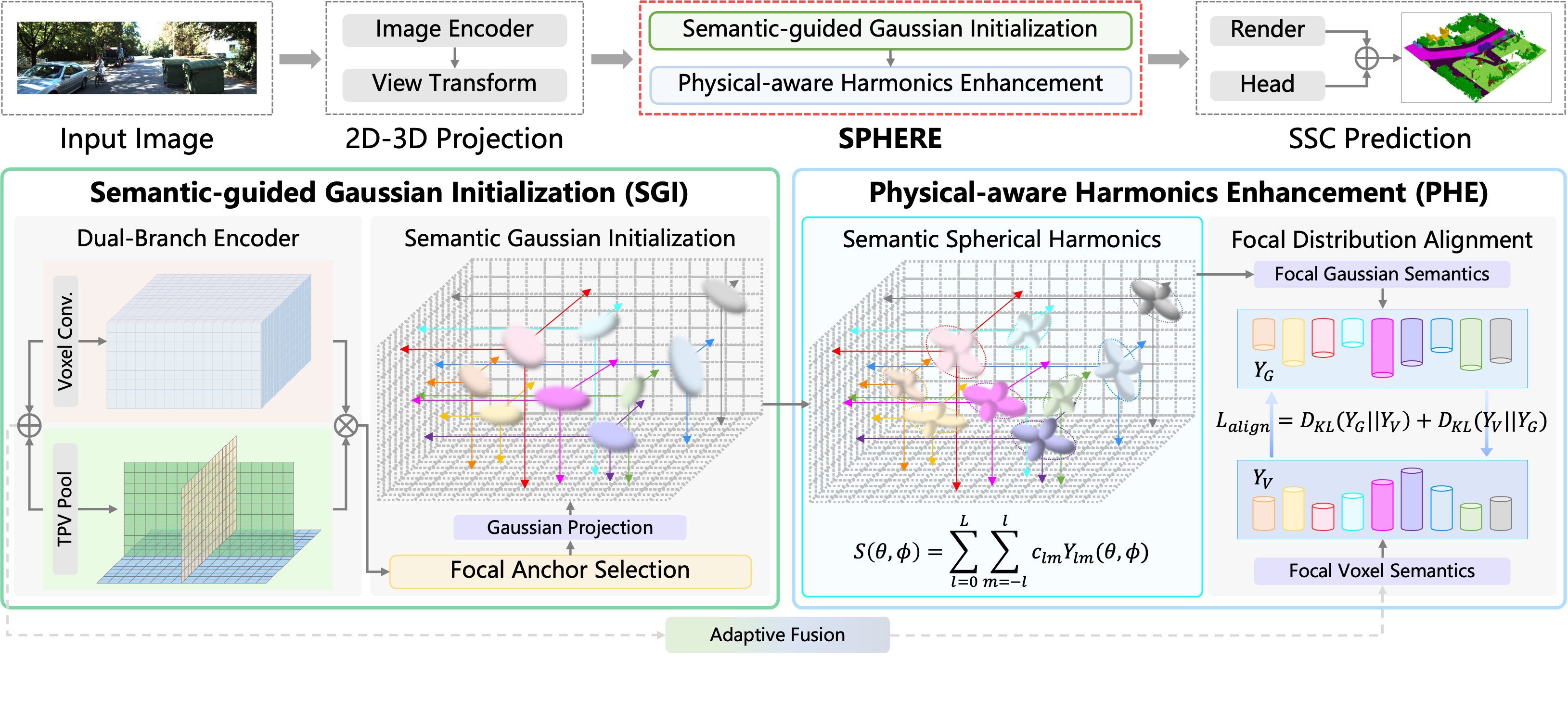
(1)SPHERE: 语义-物理联合表征三维占用预测
SPHERE: Semantic-PHysical Engaged REpresentation for 3D Semantic Scene Completion
作者:杨至文(博士生),彭宇新
通讯作者:彭宇新
论文链接:https://arxiv.org/abs/2509.11171
源代码链接:https://github.com/PKU-ICST-MIPL/SPHERE_ACMMM2025
视觉三维占用预测旨在从多视角图像中重建完整的三维语义场景,即预测空间中每个体素的几何占用状态与语义类别,实现对复杂环境的精细感知与重建,在自动驾驶、机器人导航等场景中具有重要的研究和应用价值。然而,现有视觉三维占用预测方法通常采用单一表征方法,面临如下挑战:(1)基于体素的表征方法虽然具备高效的逐体素分类能力,但往往难以建模潜在的物理规律,导致语义占用预测结果几何细节缺失、不够真实;(2)基于高斯的表征方法在建模真实几何细节方面表现出色,但是在处理自动驾驶等大规模、复杂场景时存在计算开销高、收敛速度慢的问题,难以准确学习每个高斯表征的上下文语义信息,导致占用预测结果中出现语义混淆。
针对上述问题,本文提出了语义-物理联合表征三维占用预测方法SPHERE,主要包含两个阶段:(1)语义引导的高斯初始化,首先通过体素分支和三视图分支分别提取局部与全局语义特征,并根据两者的语义一致性筛选具有辨识性语义特征的关键锚点,引导高斯表征在关键区域的高效初始化;(2)物理感知的球谐增强,进一步将高斯语义表征投影到正交球谐空间,增强局部上下文几何结构信息建模,最后通过关键体素分布对齐促进语义-几何一致性,从而实现精度与效率兼顾的三维占用预测。实验结果表明,本方法在常用自动驾驶数据集SemanticKITT和SSCBench-KITTI-360上均取得了性能提升。
该论文的第一作者是北京大学王选计算机研究所2022级博士生杨至文,通讯作者是彭宇新教授。
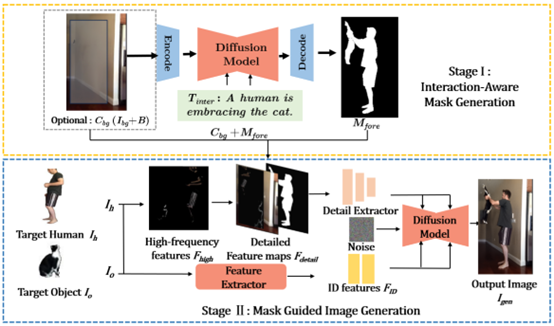
(2)Interact-Custom:定制化人物交互图像生成
Interact-Custom: Customized Human Object Interaction Image Generation
作者:徐铸(博士生),王兆闻,彭宇新,刘洋
通讯作者:刘洋
论文链接:https://arxiv.org/abs/2508.19575
源代码链接:https://github.com/XZPKU/Inter-custom
定制化图像生成旨在在生成图像中定制多个目标概念,这一技术因其广泛的应用而引起了关注。然而现有的方法主要集中在目标实体的外观定制,而忽略了目标实体之间的精细交互控制。为了使模型同时具备交互控制能力,本文专注于人类与物体的交互场景,提出了定制化人类物体交互图像生成(CHOI)任务,同时要求保留目标人类物体的身份特征,并控制它们之间的交互语义。本文发现,CHOI任务主要面临如下挑战:同时进行身份保留和交互控制的需求要求模型能够解耦人物的身份特征和交互特征,而现有的人物交互图像数据集无法提供支持此类特征分解学习的理想样本;此外,人类与物体之间不合理的空间位置关系可能导致交互语义的缺失,影响生成图像的交互语义表达。
为了解决上述问题,本文首先收集一个针对CHOI任务定制的大规模数据集,其中每个样本包含不同姿势的同一交互人物对,用于引导模型学习解耦人物的身份特征和交互特征。然后,为了提供合理的空间位置信息表达交互语义,本文设计了一个两阶段的模型Interact-Custom,首先通过生成前景交互掩码显式建模人物空间位置关系,随后在掩码引导下,根据目标人和物体的参考图像提取身份特征,生成对应定制化的人物交互图像。此外,Interact-Custom还提供了指定背景内容以及目标人物出现在图像具体位置的可选功能,提供更高的生成内容可控性。本文在收集的CHOI数据集上通过实验验证了本文方法在人和物体定制化身份保持能力和目标交互语义表达能力上的有效性。
该论文的第一作者是北京大学王选计算机研究所2024级博士生徐铸,通讯作者是刘洋助理教授,由王兆闻研究员、彭宇新教授共同合作完成。