
2025-06-06:MIPL师生参加 VALSE 2025
2025年6月6日至8日,视觉与学习青年学者研讨大会(Vision and Learning Seminar, VALSE 2025)在广东省珠海市召开。MIPL彭宇新教授、博士生邓梓焌、李耕,硕士生崔逸翔参加了此次会议。
VALSE每年举办一次,自2011年发起以来,始终秉持“学术为先、学生为本、交流为要”的初心使命,致力于为计算机视觉、图像处理、模式识别、多媒体与机器学习研究领域内的中国青年学者提供一个深层次、纯粹学术交流的舞台。

彭宇新教授应邀做《基于多模态大模型的视觉内容理解与生成》专题报告

MIPL师生会场合影(从左到右:邓梓焌、崔逸翔、彭宇新教授、李耕)
本次大会MIPL共有三篇论文被选中进行墙报展示,论文信息如下:
[1] Hulingxiao He, Geng Li, Zijun Geng, Jinglin Xu and Yuxin Peng*, "Analyzing and Boosting the Power of Fine-Grained Visual Recognition for Multi-modal Large Language Models", The Thirteenth International Conference on Learning Representations (ICLR), Singapore, Apr. 24-28, 2025.【相关论文信息】
该论文针对多模态大模型识别粒度粗的问题,提出细粒度知识对比增强方法:通过细粒度属性知识构建,获得大语言模型中的细粒度子类别知识;再利用属性知识增强的对比学习,对齐子类别知识与多模态数据;最后进行识别为中心的指令微调,以提升细粒度多模态大模型的识别准确率。
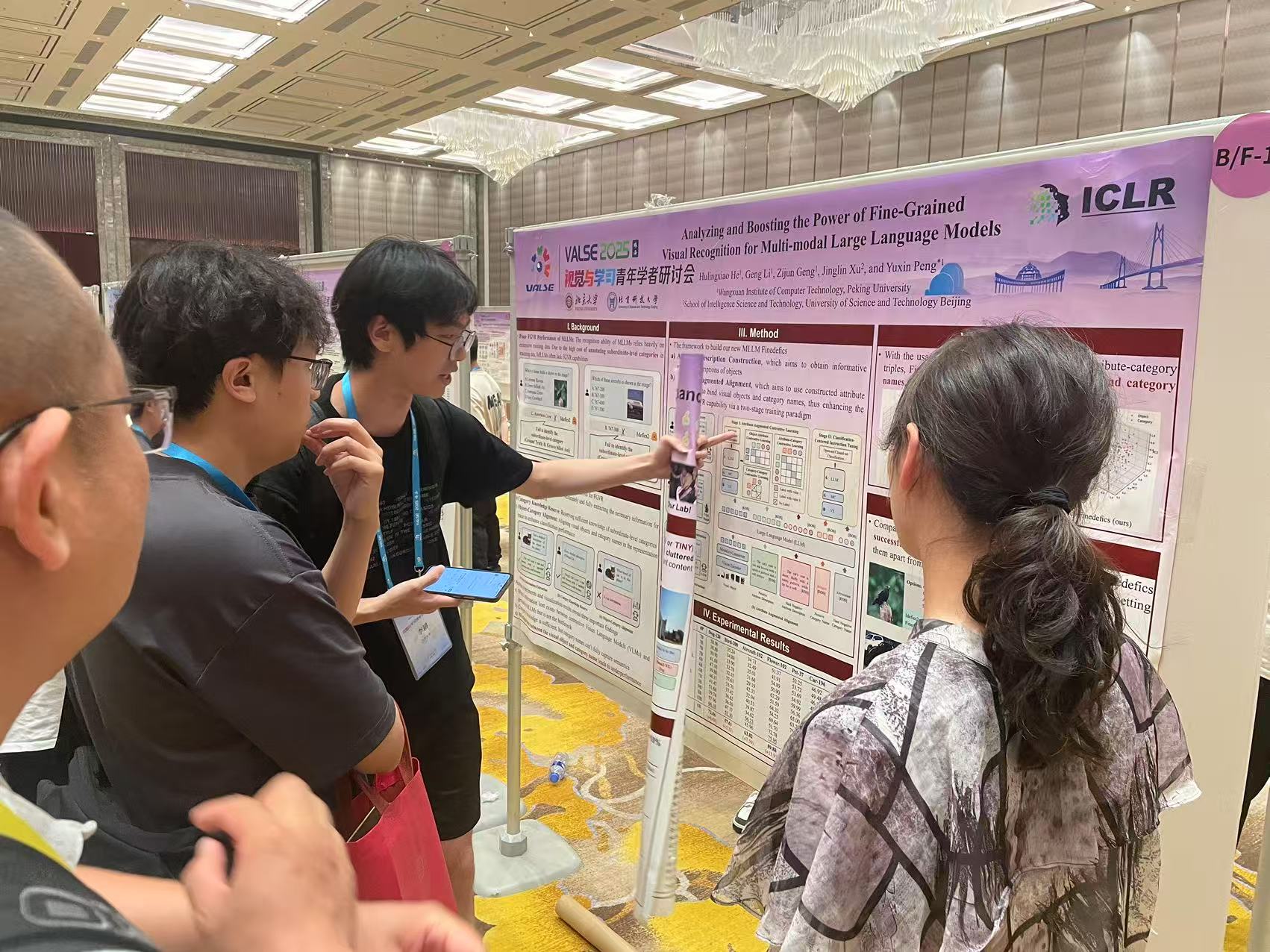
何胡凌霄同学墙报展示
[2] Geng Li, Jinglin Xu, Yunzhen Zhao and Yuxin Peng*, "DyFo: A Training-Free Dynamic Focus Visual Search for Enhancing LMMs in Fine-Grained Visual Understanding", 38th IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , Music City Center, Nashville TN, USA, Jun. 11-15, 2025. (Highlight, 13.5%) 【相关论文信息】
该论文针对多模态大模型在高分辨率图像与复杂场景中细粒度理解能力不足的问题,提出训练无关的动态聚焦视觉搜索方法DyFo:通过模拟人类视觉搜索行为,引入蒙特卡洛树搜索实现多模态模型与视觉专家的协同聚焦,逐步定位关键区域,有效提升细粒度理解性能,且具备即插即用与异步推理等优点。
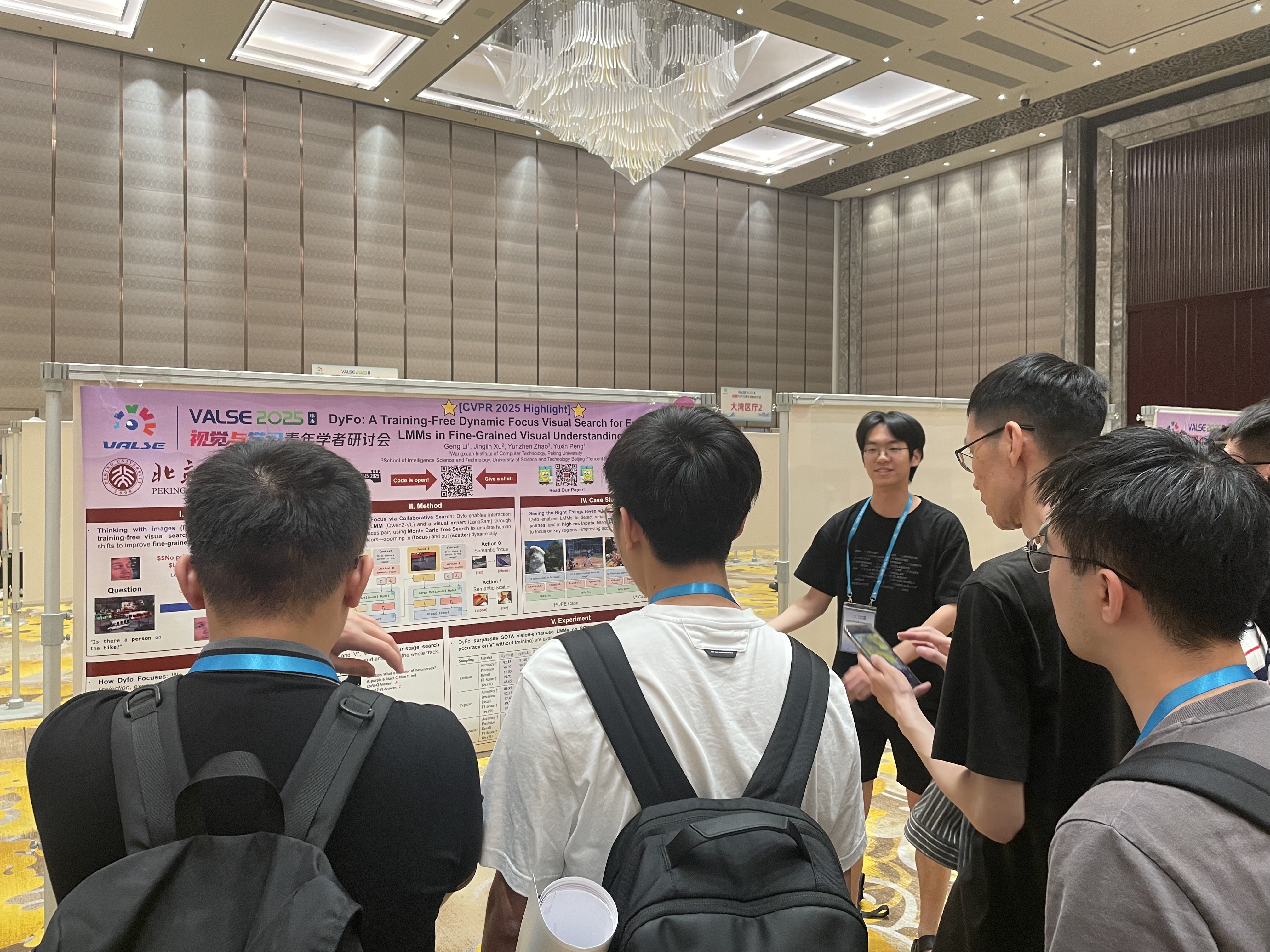
李耕同学做墙报展示
[3] Zhenyu Cui, Jiahuan Zhou and Yuxin Peng*, "DKC: Differentiated Knowledge Consolidation for Cloth-Hybrid Lifelong Person Re-identification", 38th IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Music City Center, Nashville TN, USA, Jun. 11-15, 2025.【相关论文信息】
该论文针对换装终身行人重识别中新旧知识冲突导致的旧知识灾难性遗忘问题,提出差异化知识巩固方法:通过自适应细粒度聚类,选择性地将新知识与旧知识融合;再利用更新后的特征对旧特征重构,避免学习冲突新知识导致的旧知识灾难性遗忘;最后在不同特征分布风集中对齐差异化新旧知识,以提升终身行人重识别方法的识别准确率。

崔振宇同学墙报展示
VALSE每年举办一次,自2011年发起以来,始终秉持“学术为先、学生为本、交流为要”的初心使命,致力于为计算机视觉、图像处理、模式识别、多媒体与机器学习研究领域内的中国青年学者提供一个深层次、纯粹学术交流的舞台。
[1] Hulingxiao He, Geng Li, Zijun Geng, Jinglin Xu and Yuxin Peng*, "Analyzing and Boosting the Power of Fine-Grained Visual Recognition for Multi-modal Large Language Models", The Thirteenth International Conference on Learning Representations (ICLR), Singapore, Apr. 24-28, 2025.【相关论文信息】
该论文针对多模态大模型识别粒度粗的问题,提出细粒度知识对比增强方法:通过细粒度属性知识构建,获得大语言模型中的细粒度子类别知识;再利用属性知识增强的对比学习,对齐子类别知识与多模态数据;最后进行识别为中心的指令微调,以提升细粒度多模态大模型的识别准确率。
该论文针对多模态大模型在高分辨率图像与复杂场景中细粒度理解能力不足的问题,提出训练无关的动态聚焦视觉搜索方法DyFo:通过模拟人类视觉搜索行为,引入蒙特卡洛树搜索实现多模态模型与视觉专家的协同聚焦,逐步定位关键区域,有效提升细粒度理解性能,且具备即插即用与异步推理等优点。
该论文针对换装终身行人重识别中新旧知识冲突导致的旧知识灾难性遗忘问题,提出差异化知识巩固方法:通过自适应细粒度聚类,选择性地将新知识与旧知识融合;再利用更新后的特征对旧特征重构,避免学习冲突新知识导致的旧知识灾难性遗忘;最后在不同特征分布风集中对齐差异化新旧知识,以提升终身行人重识别方法的识别准确率。