2025-01-23:研究室的2篇论文被ICLR 2025接收
(1)分析与提升多模态大模型的细粒度视觉识别能力
Analyzing and Boosting the Power of Fine-Grained Visual Recognition for Multi-modal Large Language Models
作者:何胡凌霄(博士生),李耕(博士生),耿子竣(本科生),徐婧林,彭宇新
通讯作者:彭宇新
论文链接:https://openreview.net/pdf?id=p3NKpom1VL
源代码链接:https://github.com/PKU-ICST-MIPL/Finedefics_ICLR2025
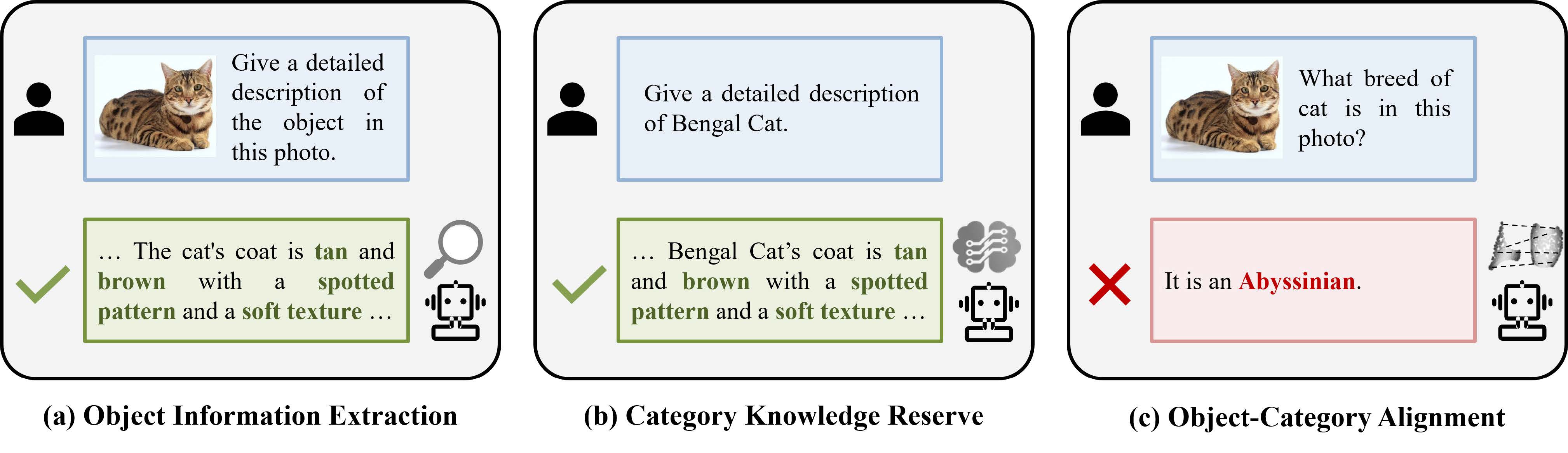
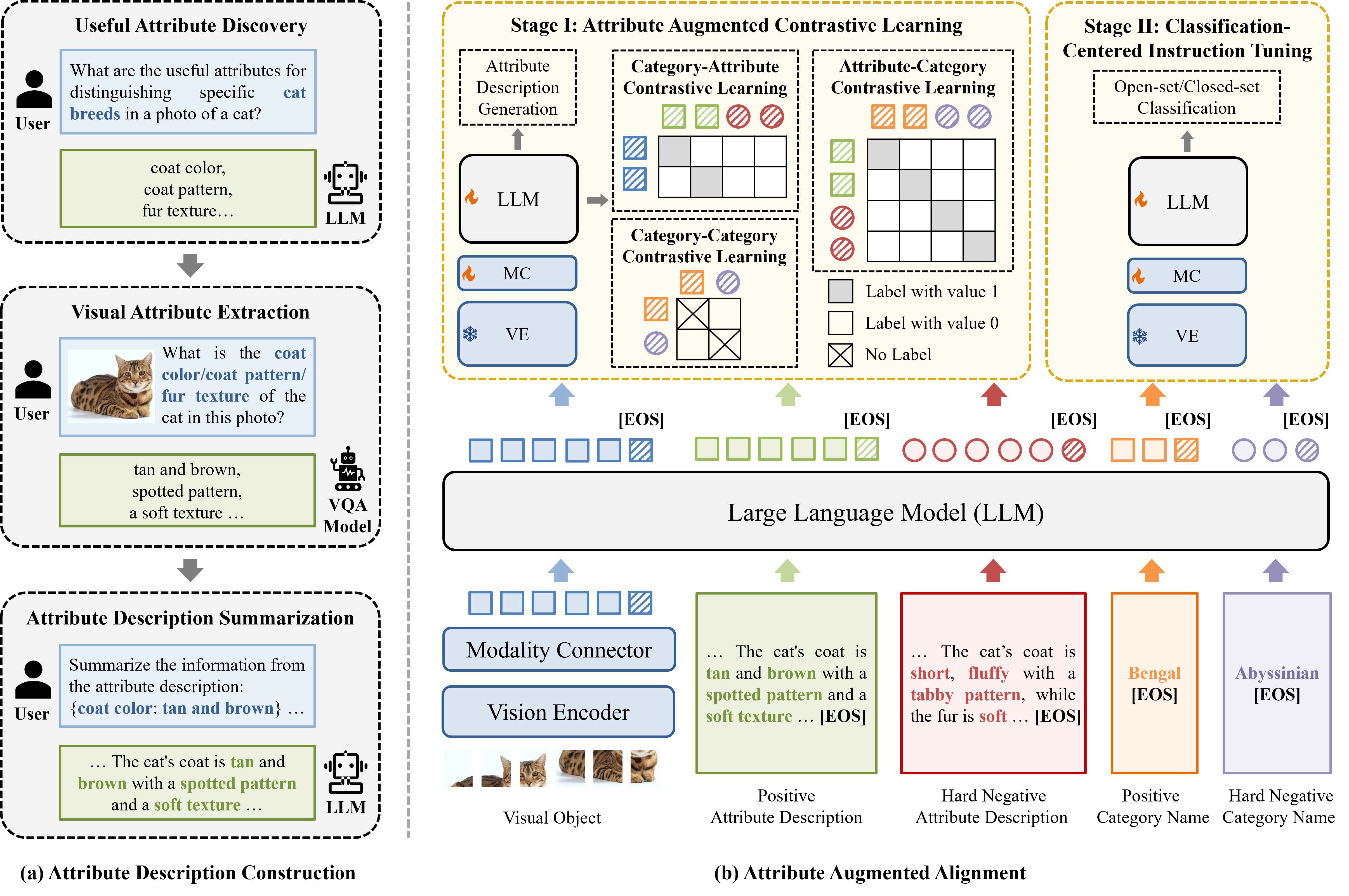
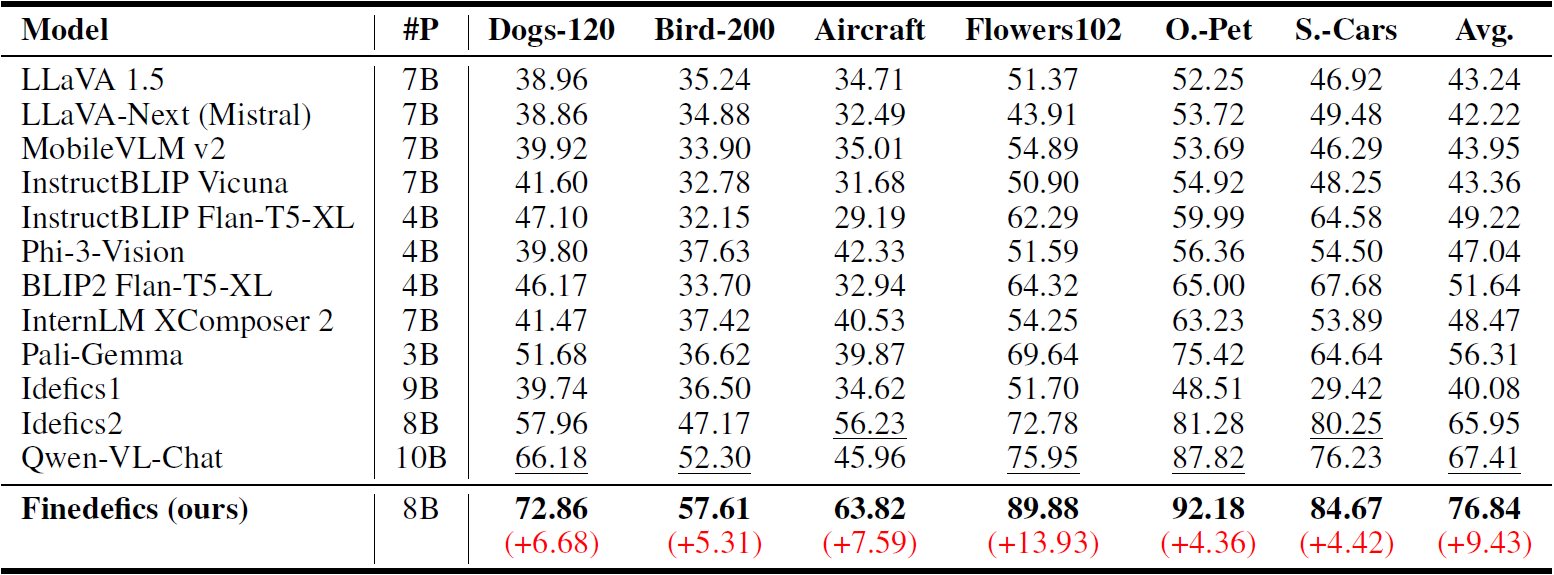
细粒度视觉识别旨在区分同一粗粒度大类下的不同细粒度子类别,如将鸟类(粗粒度大类)图像划分为西美鸥、灰背鸥、银鸥等(细粒度子类别),实现对视觉对象的精确识别,在现实生产和生活中具有重要的研究和应用价值。多模态大模型是指提取并融合文本、图像、视频等多模态数据表征,通过大语言模型进行推理,经过微调后适配到多种下游任务的基础模型。尽管现有多模态大模型在粗粒度视觉识别、问答、推理等多种任务上表现出色,但存在感知粒度粗的局限性:多模态大模型的感知能力依赖大量训练数据,但大量训练数据的细粒度类别标注成本巨大,导致现有多模态大模型无法像人一样进行细粒度视觉识别。

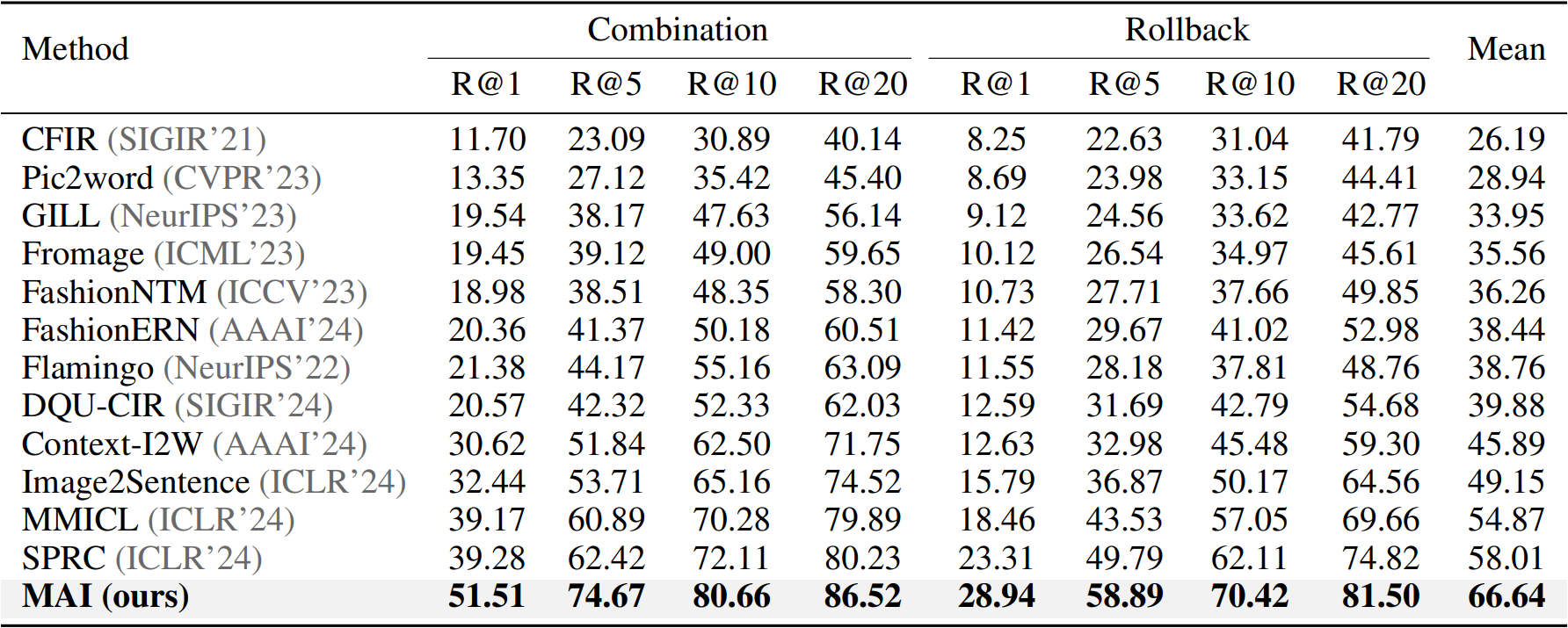
(2)面向多轮组合图像检索的聚合-迭代模型
MAI: A Multi-turn Aggregation-Iteration Model for Composed Image Retrieval
作者:陈彦哲(硕士生),杨至文(博士生),徐婧林,彭宇新
通讯作者:彭宇新
论文链接:https://openreview.net/pdf?id=gXyWbl71n1
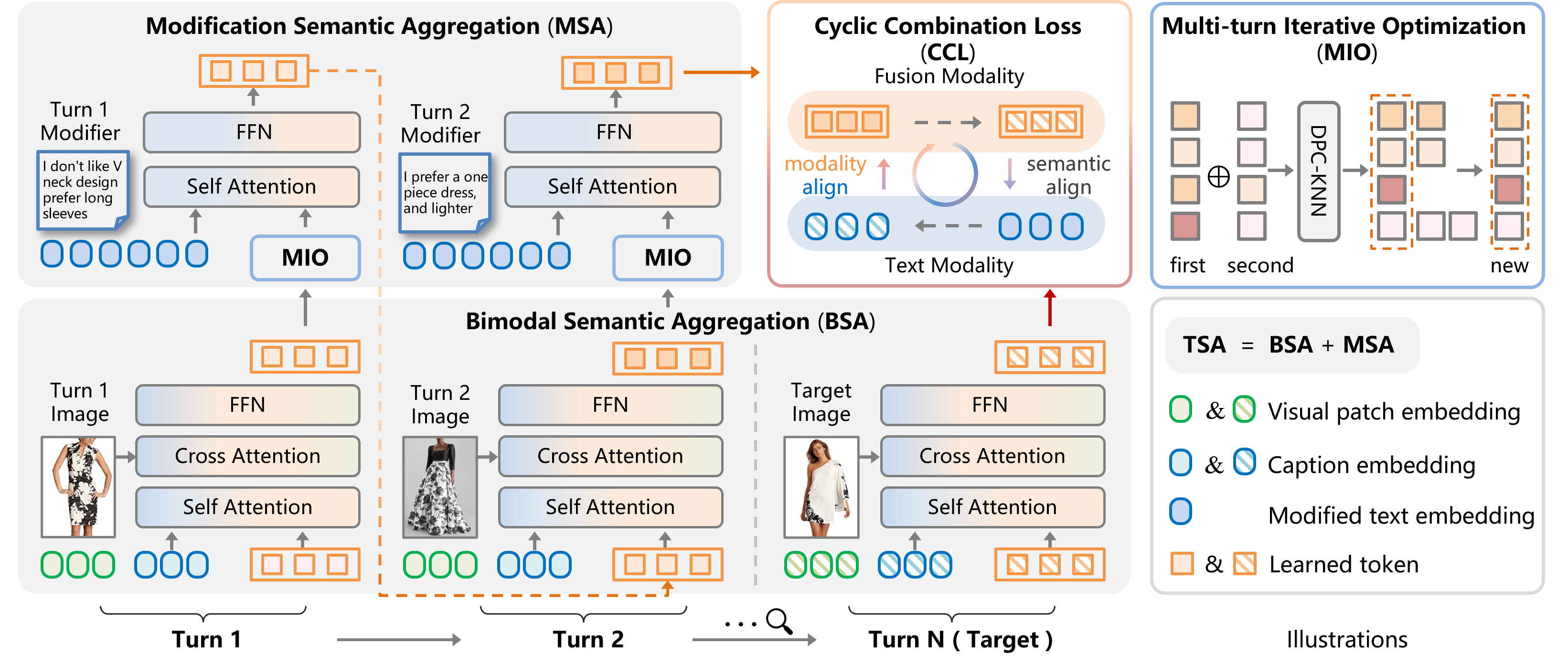
图像检索是计算机视觉的基本任务,近年来在电商等场景中广泛应用。然而,单一图像难以满足用户需求,用户通常需要修改图像以适配特定场景。为此,组合图像检索(CIR)通过结合参考图像和修改文本定位目标图像,多轮组合图像检索(MTCIR)利用用户迭代反馈,逐渐成为研究热点。然而,现有MTCIR方法通常通过串联单轮CIR数据集构建多轮数据集,存在两个不足:(1)历史上下文缺失:修改文本缺乏对历史图像的关联,导致检索偏离实际场景;(2)数据规模受限:单轮数据集规模有限,串联方式进一步压缩了多轮数据集的规模,难以满足需求。

相关链接:
北京大学多媒体信息处理研究室的2篇论文被ICLR 2025录用
北大彭宇新教授团队开源细粒度多模态大模型Finedefics