
2024-12-13:MIPL师生参加第二十届中国图象图形学学会青年科学家会议
2024年12月13日至15日,第二十届中国图象图形学学会青年科学家会议在浙江杭州召开,彭宇新教授受邀参加博士生论坛并做特邀报告,题目是《科研工作的一点体会》。彭宇新教授作为CSIG副秘书长、提名与奖励委员会副主任,分别参加了CSIG青托俱乐部第二次全体大会,优博俱乐部第一届会员大会。王选所MIPL博士生杨至文、尹思博、赵国豪,硕士生王梓烁、李鹿敏参加了此次青年科学家会议,并做墙报展示。
中国图象图形学学会青年科学家会议是由中国图象图形学学会青年工作委员会发起的学术会议。会议面向国际学术前沿与国家战略需求,致力于支持图象图形领域的优秀青年学者,为青年学者们提供学术交流与研讨的平台,促进青年学者之间的交流与合作创新。会议同时邀请产业界专家与青年学者深入交流,鼓励图象图形领域的“产学研”深度合作。

彭宇新教授作特邀报告

MIPL师生会场合影(左1:李鹿敏,左2:赵国豪,左3:王梓烁,右3:彭宇新教授,右2:尹思博,右1:杨至文)
本次大会MIPL共有两篇论文被选中进行墙报展示,论文信息如下:
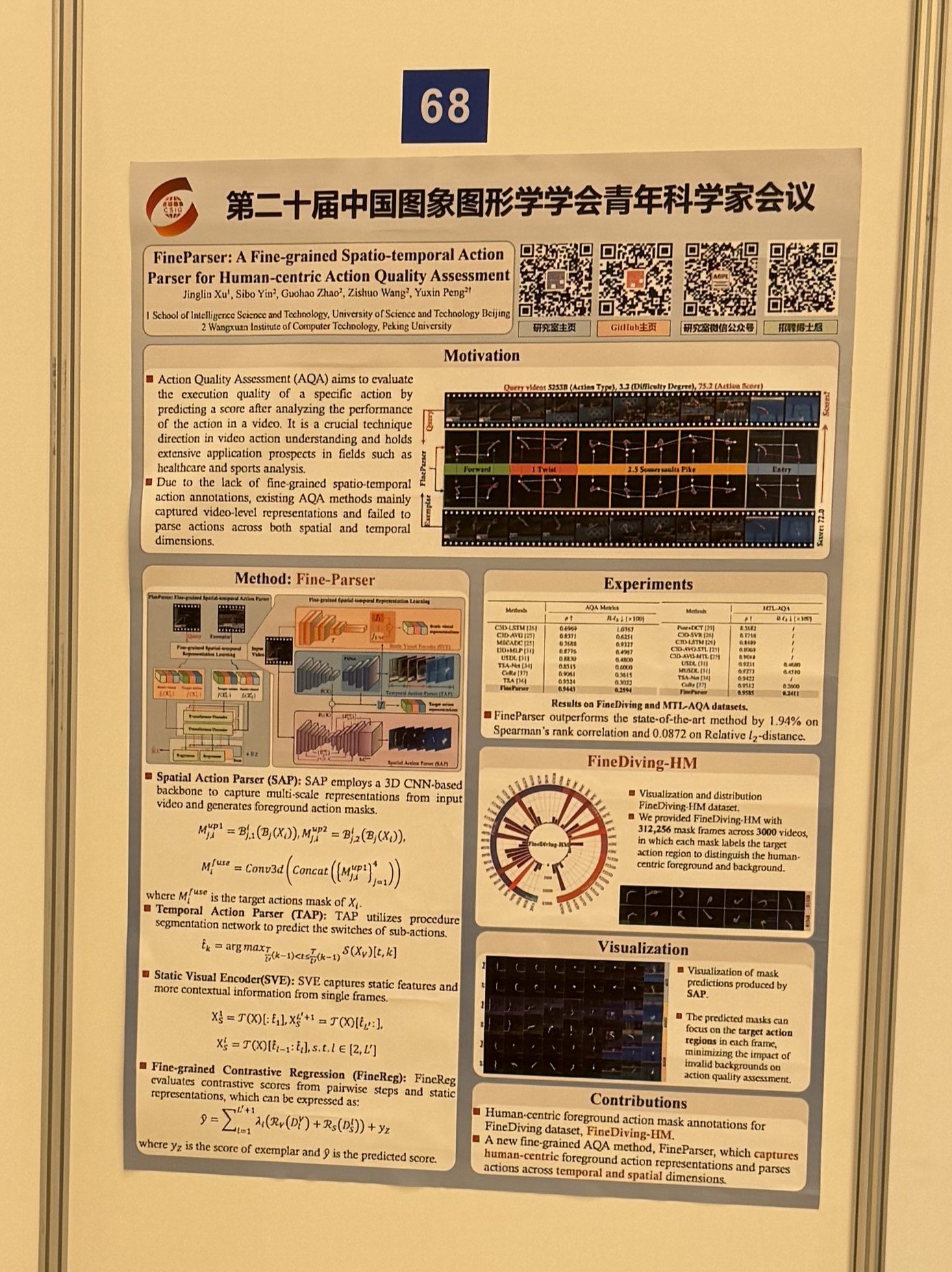
[1] Jinglin Xu, Sibo Yin, Guohao Zhao, Zishuo Wang and Yuxin Peng*, "FineParser: A Fine-grained Spatio-temporal Action Parser for Human-centric Action Quality Assessment", 37th IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle WA, USA, June 17 - 21, 2024, (Oral, 3.3%).
该论文针对动作质量评估任务(Action Quality Assessment,AQA)提出以人为中心的时空动作解析方法:首先设计空间动作解析器(SAP),用以捕获以人为中心的前景动作的多尺度表征,重点关注每一帧的目标动作区域,保证在空间解析的有效性。其次设计时间动作解析器(TAP),通过学习视频的时空表征将目标动作解析为连续的步骤来建模人体动作的语义一致性和时间相关性。然后设计静态视觉编码器(SVE),通过捕获每一帧详细的上下文信息来增强目标动作表征。最后设计细粒度对比回归器(FineReg)捕获成对目标动作步骤之间的细粒度差异,并评估动作质量。
尹思博同学做墙报展示
[2] Zishuo Wang, Wenhao Zhou, Jinglin Xu and Yuxin Peng*, "SIA-OVD: Shape-Invariant Adapter for Bridging the Image-Region Gap in Open-Vocabulary Detection", 32nd ACM International Conference on Multimedia (ACM MM), Melbourne, Australia, Oct. 28 - Nov. 1, 2024.
本论文针对开放词汇目标检测(Open-Vocabulary Detection,OVD)中,图像-区域差异导致目标检测框分类准确率较低的问题,提出形状不变性适配器(Shape-Invariant Adapter,SIA)方法。首先,本论文探讨了图像-区域差异的来源,观察到检测框的形状对分类效果有明显的影响,“刀”、“领带”、“滑雪板”等细长形状的类别的分类效果较差。本论文认为现有方法使用RoIAlign进行特征裁剪后不同形状的特征图均被压缩为正方形,导致目标物体的形状特征被破坏,CLIP无法正确识别。因此,本论文提出形状不变性适配器方法以缓解上述图像-区域差异:维护由多个特征适配器网络组成的集合,其中每一个适配器处理检测框长宽比在一个固定范围内的区域特征,将其映射回CLIP能够识别的未形变特征,从而提高对目标检测框的分类准确率,进而取得了更好的开放词汇目标检测性能。

王梓烁同学做墙报展示
中国图象图形学学会青年科学家会议是由中国图象图形学学会青年工作委员会发起的学术会议。会议面向国际学术前沿与国家战略需求,致力于支持图象图形领域的优秀青年学者,为青年学者们提供学术交流与研讨的平台,促进青年学者之间的交流与合作创新。会议同时邀请产业界专家与青年学者深入交流,鼓励图象图形领域的“产学研”深度合作。
[1] Jinglin Xu, Sibo Yin, Guohao Zhao, Zishuo Wang and Yuxin Peng*, "FineParser: A Fine-grained Spatio-temporal Action Parser for Human-centric Action Quality Assessment", 37th IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle WA, USA, June 17 - 21, 2024, (Oral, 3.3%).
该论文针对动作质量评估任务(Action Quality Assessment,AQA)提出以人为中心的时空动作解析方法:首先设计空间动作解析器(SAP),用以捕获以人为中心的前景动作的多尺度表征,重点关注每一帧的目标动作区域,保证在空间解析的有效性。其次设计时间动作解析器(TAP),通过学习视频的时空表征将目标动作解析为连续的步骤来建模人体动作的语义一致性和时间相关性。然后设计静态视觉编码器(SVE),通过捕获每一帧详细的上下文信息来增强目标动作表征。最后设计细粒度对比回归器(FineReg)捕获成对目标动作步骤之间的细粒度差异,并评估动作质量。
本论文针对开放词汇目标检测(Open-Vocabulary Detection,OVD)中,图像-区域差异导致目标检测框分类准确率较低的问题,提出形状不变性适配器(Shape-Invariant Adapter,SIA)方法。首先,本论文探讨了图像-区域差异的来源,观察到检测框的形状对分类效果有明显的影响,“刀”、“领带”、“滑雪板”等细长形状的类别的分类效果较差。本论文认为现有方法使用RoIAlign进行特征裁剪后不同形状的特征图均被压缩为正方形,导致目标物体的形状特征被破坏,CLIP无法正确识别。因此,本论文提出形状不变性适配器方法以缓解上述图像-区域差异:维护由多个特征适配器网络组成的集合,其中每一个适配器处理检测框长宽比在一个固定范围内的区域特征,将其映射回CLIP能够识别的未形变特征,从而提高对目标检测框的分类准确率,进而取得了更好的开放词汇目标检测性能。