2024-06-17:北京大学多媒体信息处理研究室在CVPR 2024发表6篇论文

北京大学多媒体信息处理研究室(MIPL)共有6篇论文入选,成果覆盖动作质量评估、3D人体姿态估计、时空动作定位、类增量学习、终身行人再识别等研究方向,其中有1篇被选为Oral,1篇被选为Highlight。
(1)FineParser:基于细粒度时空动作解析的以人为中心的动作质量评价(Oral,录取率3.3%)
FineParser: A Fine-grained Spatio-temporal Action Parser for Human-centric Action Quality Assessment
作者:徐婧林,尹思博(博士生),赵国豪(博士生),王梓烁(硕士生),彭宇新
通讯作者:彭宇新
动作质量评价(Action Quality Assessment,AQA)旨在通过分析视频中人体动作的表现来评估其动作的执行质量,是视频动作理解中重要的研究方向,在运动分析、医疗保健等领域有广泛的应用前景。现有AQA方法缺乏对人体动作的全维度细粒度理解,导致评价过程和输出结果的可靠性不足、视觉可解释性较差。
针对上述问题,本文构建了以人为中心的目标动作标注集FineDiving-HM,并提出了以人为中心的细粒度时空动作解析方法FineParser,在细粒度动作层面同时从时间和空间两个维度对齐人体动作,获取以人为中心的前景动作表征,提升动作质量评价性能。具体地,首先设计空间动作解析器(SAP),用以捕获以人为中心的前景动作的多尺度表征,重点关注每一帧的目标动作区域,保证在空间解析的有效性。其次设计时间动作解析器(TAP),通过学习视频的时空表征将目标动作解析为连续的步骤来建模人体动作的语义一致性和时间相关性。然后设计静态视觉编码器(SVE),通过捕获每一帧详细的上下文信息来增强目标动作表征。最后设计细粒度对比回归器(FineReg)捕获成对目标动作步骤之间的细粒度差异,并评估动作质量。本文方法在动作质量评价数据集FineDiving和MTL-AQA上进行了全面的对比和消融实验,实验结果显示了本文方法的有效性。
[Code] [Paper] [Dataset]
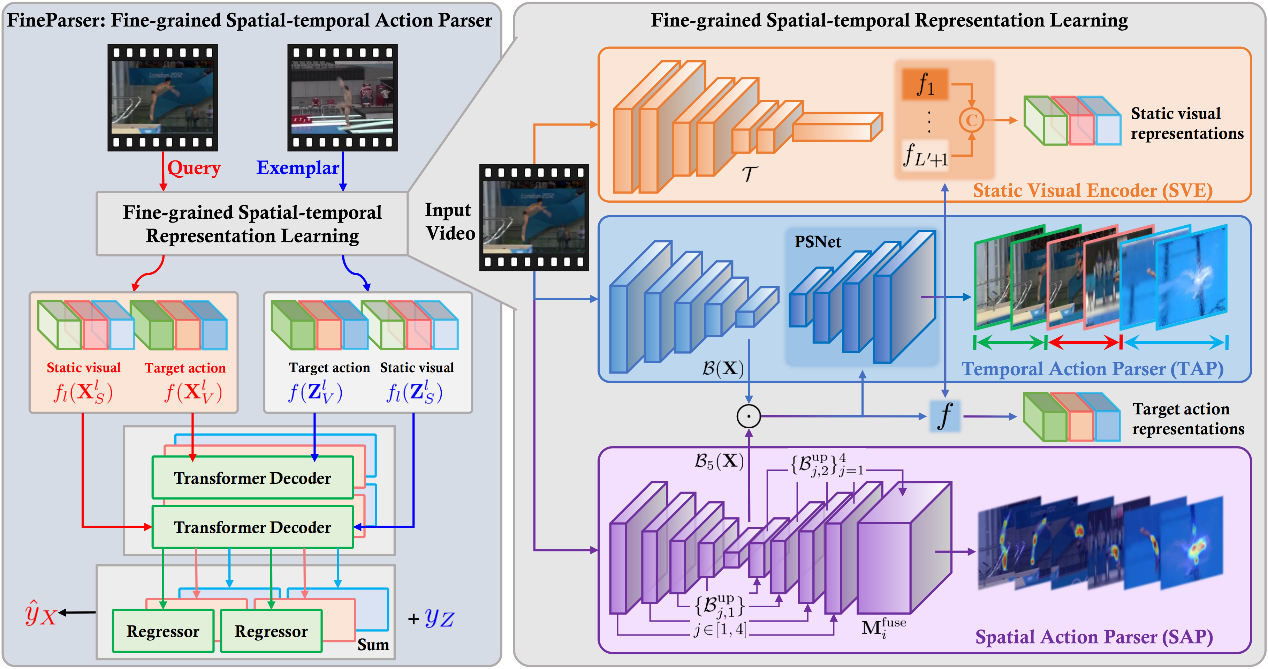
图1:基于细粒度时空动作解析的动作质量评价方法框架图
(2)FinePOSE:基于扩散模型的细粒度提示驱动三维人体姿态估计(Highlight,录取率11.9%)
FinePOSE: Fine-Grained Prompt-Driven 3D Human Pose Estimation via Diffusion Models
作者:徐婧林,郭奕杰(本科实习生),彭宇新
通讯作者:彭宇新
三维人体姿态估计旨在根据二维图像或视频来预测人体关节在三维空间中的坐标。在该任务中,从二维关节点到三维关节点的映射中存在深度模糊的问题,同时人体肢体的高自由度以及关节间复杂性使得模型难以在三维空间中准确地预测出人体关节坐标。现有的方法在解决上述问题时忽视了隐藏在不同人体部位的细粒度指导,导致三维人体姿态估计性能受限。
因此,本文基于扩散模型提出了一种细粒度提示驱动的三维人体姿态估计方法,在细粒度可学习提示的驱动下利用可获得的文本信息和人体自然先验知识增强模型对人体姿态的理解。具体地,首先对可获得的文本信息和人体自然先验知识进行编码,包括与人体姿态相关的三种信息,即动作类别、人体的粗粒度和细粒度部位(“人、头、躯干、手臂、腿”),以及人体运动学信息“速度”。其次将编码特征与可学习提示相结合,构建基于细粒度姿态感知的可学习提示。然后在所学得的提示与带噪的三维人体姿态表征之间建立细粒度的通信,以增强扩散模型的去噪能力。此外,为了能够处理带有不同噪声水平的三维人体姿态,将时间信息与人体部位的细粒度可学习提示相结合并引入到去噪过程中,以增强模型在不同噪声水平下预测三维人体姿态的能力。实验结果表明,本文方法在Human3.6M和MPI-INF-3DHP数据集上均取得了当前最好效果。
[Code] [Paper]
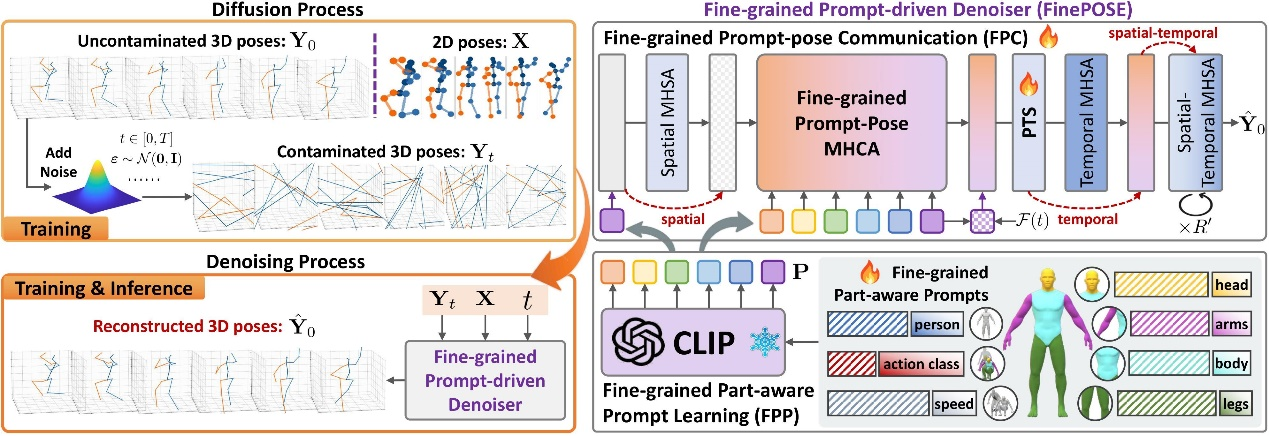
图2:基于扩散模型的细粒度提示驱动三维人体姿态估计方法框架图
(3)FineSports: 用于细粒度动作理解的多人场景运动视频数据集
FineSports: A Multi-person Hierarchical Sports Video Dataset for Fine-grained Action Understanding
作者:徐婧林,赵国豪(博士生),尹思博(博士生),周汶昊(硕士生),彭宇新
通讯作者:彭宇新
对多人场景的体育运动视频进行细粒度动作分析是复杂困难的,因为运动员快速移动、身体对抗激烈,导致大多数场景中的视觉障碍严重,并且现有的多人场景体育运动视频数据集缺乏细粒度注释,例如在空间、时间、目标属性上。
针对上述问题,本文构建了一个新的多人场景的体育运动视频数据集FineSports,包含1万个多人场景比赛视频,涵盖52个细粒度动作类型、1.6万个目标动作实例、12.3万个目标动作时空边界框等细粒度标注。基于FineSports数据集,本文进一步提出了一种基于提示驱动的时空动作定位方法PoSTAL,由提示驱动的目标动作编码器PTA和目标动作时空检测器ATD组成。具体地,首先利用PTA模块在描述性提示的引导下提取目标动作表征,然后将其送入ATD模块同时获得目标动作tube和相应的细粒度动作类型,同时在时间和空间上完成目标动作定位。在FineSports数据集上的实验表明,PoSTAL在帧级平均精度(frame-mAP)和视频级平均精度(video-mAP)上的表现均优于当前最先进的方法。
[Code] [Paper] [Dataset]
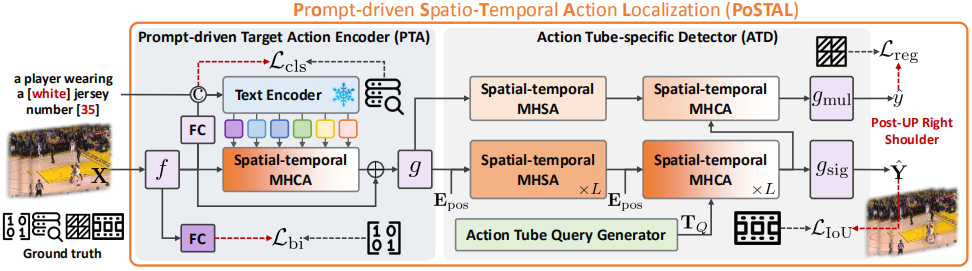
图3:基于提示驱动的时空动作定位方法框架图
(4)基于连续兼容表示的免重新索引终身行人再识别方法
Learning Continual Compatible Representation for Re-indexing Free Lifelong Person Re-identification
作者:崔振宇(博士生),周嘉欢,王珣,朱曼瑜,彭宇新
通讯作者:彭宇新
终身行人再识别(L-ReID)的目标是通过从连续收集的数据中学习跨越不同场景匹配同一个人。当使用新数据更新L-ReID模型后,需要重新计算图库中所有历史图像以获得新的特征进行测试,这被称为“重新索引”。然而,当图库中的原始图像由于数据隐私问题无法获取时,重新索引变得不可行,导致不同模型计算的查询和图库特征之间的不兼容,从而导致显著的性能下降。
本文聚焦于一个新的任务,即免重新索引的终身行人再识别(RFL-ReID),要求在不重新索引图库中原始图像的情况下实现有效的L-ReID。为此,本文提出了一种连续兼容表示(C2R)方法,可以使由不断更新的模型计算的查询特征有效地检索由旧模型计算的图库特征,从而实现兼容性。具体而言,首先设计了一个连续兼容转移(CCT)网络,用于不断将旧图库特征转移并整合到新的特征空间。此外,引入了一个平衡兼容蒸馏模块,通过对齐转移的特征空间和新特征空间来实现兼容性。最后,提出了一个平衡抗遗忘蒸馏模块,以消除在连续兼容转移过程中累积的旧知识遗忘。大量基准L-ReID数据集上的实验结果验证了该方法在RFL-ReID和L-ReID任务上的有效性。
[Code] [Paper]
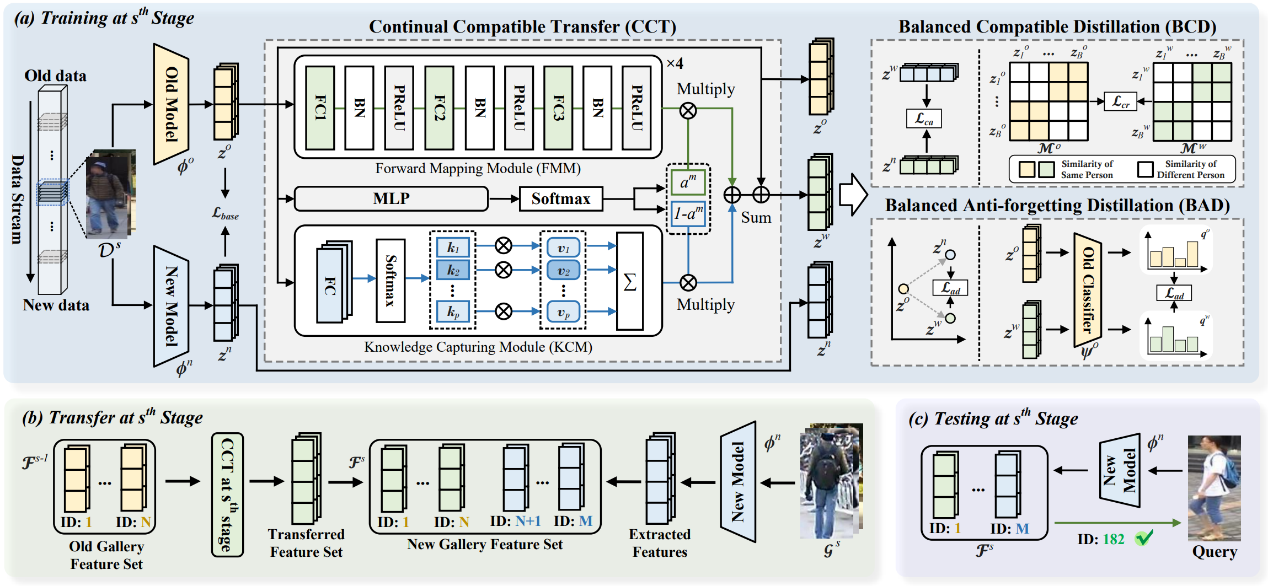
图4:基于连续兼容表示的免重新索引终身行人再识别方法框架图
(5)DKP:基于分布感知知识原型的无样本保留终身行人再识别方法
Distribution-aware Knowledge Prototyping for Non-exemplar Lifelong Person Re-identification
作者:徐昆仑(博士生),邹旭,彭宇新,周嘉欢
通讯作者:周嘉欢
终身行人再识别(L-ReID)在从动态变化的行人数据中进行学习时面临灾难性遗忘问题。现有基于样本和知识蒸馏的L-ReID方法分别存在违反数据隐私和新知识获取能力受限的问题。本文利用L-ReID领域尚未关注的原型学习策略以更好地平衡知识遗忘和获取。现有的原型方法主要关注在分类任务,其中原型被设定为类别特征中心点或统计分布。然而,上述原型设计要么丢弃了分布信息,要么忽略了实例级别的多样性,而这些信息是LReID中实现行人匹配的关键细粒度线索。
为了解决上述问题,本文提出了一种基于分布感知知识原型学习(DKP)的方法,通过建模每个样本的实例级别多样性来更加全面地表征数据中的细粒度知识,以促进LReID的鉴别性知识获取和记忆。具体而言,提出了一个实例级分布建模网络,用于建模每个实例的多样性,提升模型的细粒度知识挖掘能力。然后,提出分布引导的原型生成算法,将实例级别的多样性转换为身份级别的分布,并将身份级别分布作为原型。进而设计了基于原型的知识转移模块,利用原型知识指导模型对新数据的学习,提升LReID模型的知识抗遗忘能力。大量实验验证了该方法对促进新知识学习和提升抗遗忘性能的优越性,通过在多个公开数据集上的测试,DKP方法展示了其在处理大规模、多样化行人数据时的出色性能,相比于现有方法中取得了8.1%/9.1%的平均mAP/R@1提升。
[Code] [Paper]
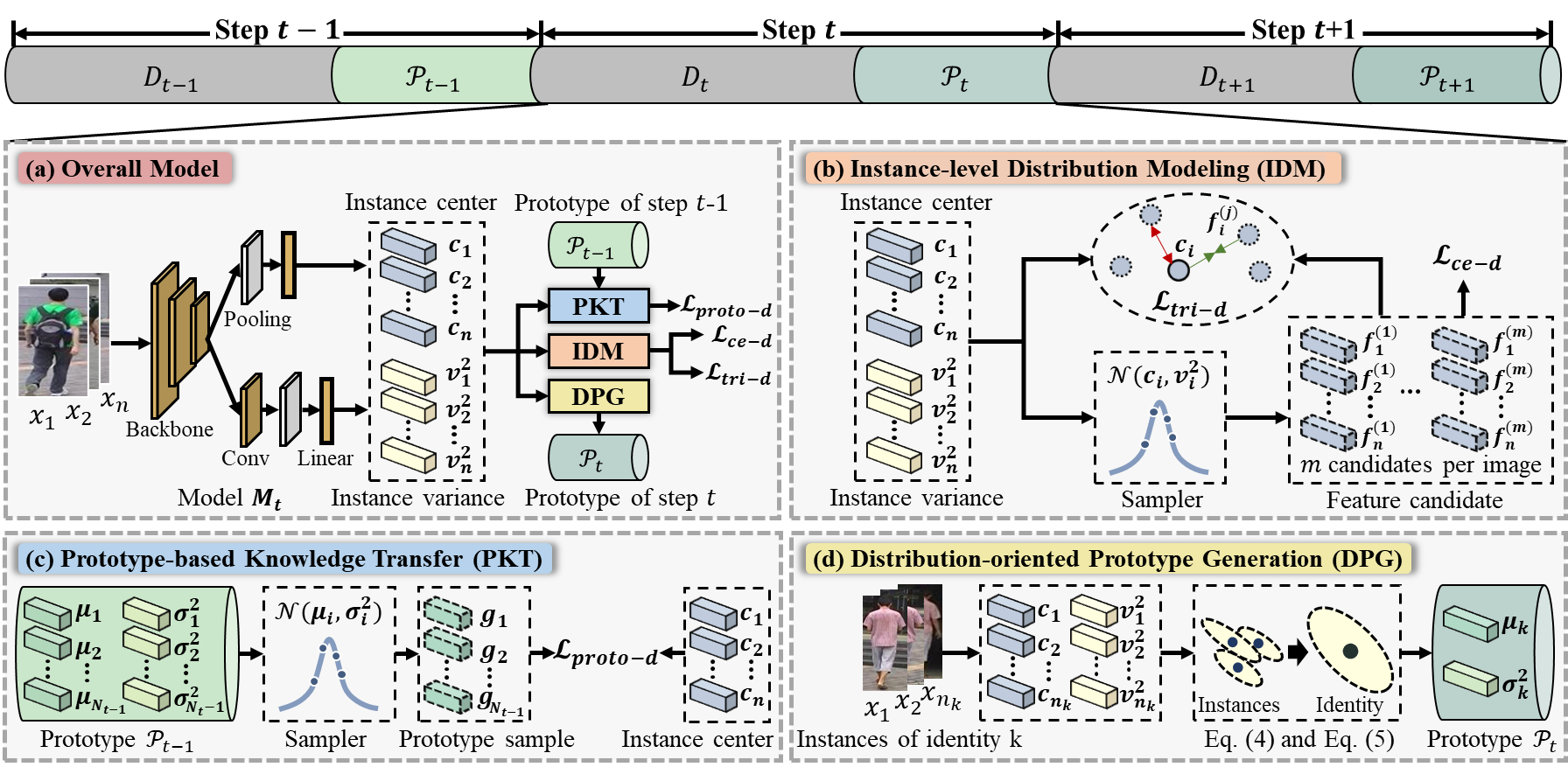
图5:基于分布感知知识原型的无样本保留终身行人再识别方法框架图
(6)FCS: 基于特征纠正和分离的无样本保留增量学习方法
FCS: Feature Calibration and Separation for Non-Exemplar Class Incremental Learning
作者:李其威(博士生),彭宇新,周嘉欢
通讯作者:周嘉欢
无样本保留的增量学习的目标是在不保留历史样本的情况下,根据一系列分批到达的数据学习一个统一的分类模型。该任务的难点是在学习新数据的同时克服对旧数据知识的遗忘。现有的方法采用知识蒸馏技术或者保留类别原型特征实现对历史知识保留。然而,这些方法存在两个重要缺陷。一方面,由于模型在持续更新,保留的类别原型特征必然会偏离其在新模型的特征空间中的正确位置,导致原型特征失效。另一方面,由于缺少历史样本信息,新类别特征难免与旧类别特征发生重叠,从而破坏模型的分类边界。
针对上述问题,本文提出了一种基于特征纠正和分离的无样本保留增量学习方法,核心思想是纠正保留的原型特征以及分离新旧类别的特征。具体而言,首先,我们设计了一个特征纠正网络,基于最优传输理论将保存的旧类别的原型调整到新模型的特征空间中,缓解由于模型更新导致的原型特征偏离问题。其次为减少新旧类别特征之间的重叠,我们设计了一个基于原型的对比损失函数,将原型特征看作与当前阶段样本类别不同的负样本,利用对比损失显式地扩大特征间距离,实现新旧类别特征之间的分离。实验结果表明,本文方法在三个常用数据集以及不同的增量学习场景下均达到了领域先进水平。
[Code] [Paper]
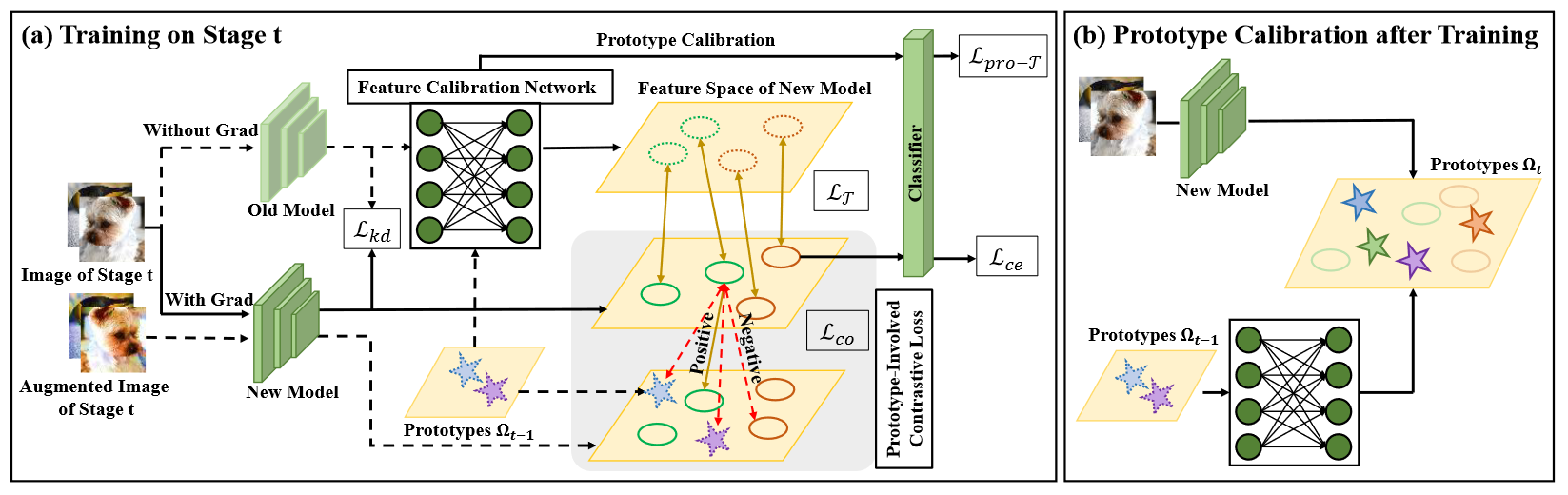
图6:基于特征纠正和分离的无样本保留增量学习方法框架图
相关链接: 北京大学多媒体信息处理研究室在CVPR 2024发表6篇论文