
2024-05-24:MIPL师生参加 CCIG 2024
2024年5月24日至26日,中国图象图形大会(Chinese Congress on Image and Graphics, CCIG 2024)在陕西省西安市召开。王选所MIPL彭宇新教授、刘洋助理教授、博士生何胡凌霄、尹思博、赵国豪参加了此次会议。
CCIG每年召开一次,是中国图象图形学学会的年度旗舰会议,涵盖图像图形各专业领域。本次会议吸引了2000余名科研院校师生、一线技术工程师前来参会。会议包括学术论坛、主题报告和墙报展示等环节。

彭宇新教授主持颁奖典礼

MIPL师生会场合影(左1:赵国豪,左2:刘洋助理教授,中:彭宇新教授,右2:何胡凌霄,右1:尹思博)
本次大会MIPL共有三篇论文被选中进行墙报展示,论文信息如下:
[1] Jinglin Xu, Sibo Yin, Guohao Zhao, Zishuo Wang and Yuxin Peng*, "FineParser: A Fine-grained Spatio-temporal Action Parser for Human-centric Action Quality Assessment", 37th IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle WA, USA, June 17 - 21, 2024, (Oral, 3.3%).
该论文针对动作质量评估任务(Action Quality Assessment,AQA)提出以人为中心的时空动作解析方法:首先设计空间动作解析器(SAP),用以捕获以人为中心的前景动作的多尺度表征,重点关注每一帧的目标动作区域,保证在空间解析的有效性。其次设计时间动作解析器(TAP),通过学习视频的时空表征将目标动作解析为连续的步骤来建模人体动作的语义一致性和时间相关性。然后设计静态视觉编码器(SVE),通过捕获每一帧详细的上下文信息来增强目标动作表征。最后设计细粒度对比回归器(FineReg)捕获成对目标动作步骤之间的细粒度差异,并评估动作质量。

尹思博同学做墙报展示
[2] Jinglin Xu, Yijie Guo and Yuxin Peng*, "FinePOSE: Fine-Grained Prompt-Driven 3D Human Pose Estimation via Diffusion Models", 37th IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle WA, USA, June 17 - 21, 2024, (Highlight, 11.9%).
该论文针对三维人体姿态估计任务提出了基于扩散模型的细粒度提示驱动的三维人体姿态估计方法,首先对文本信息和人体自然先验知识进行编码,其次将编码特征与可学习提示相结合,构建基于细粒度姿态感知的可学习提示,然后在所学的提示与带噪的三维人体姿态表征之间建立细粒度的通信,以增强扩散模型的去噪能力。
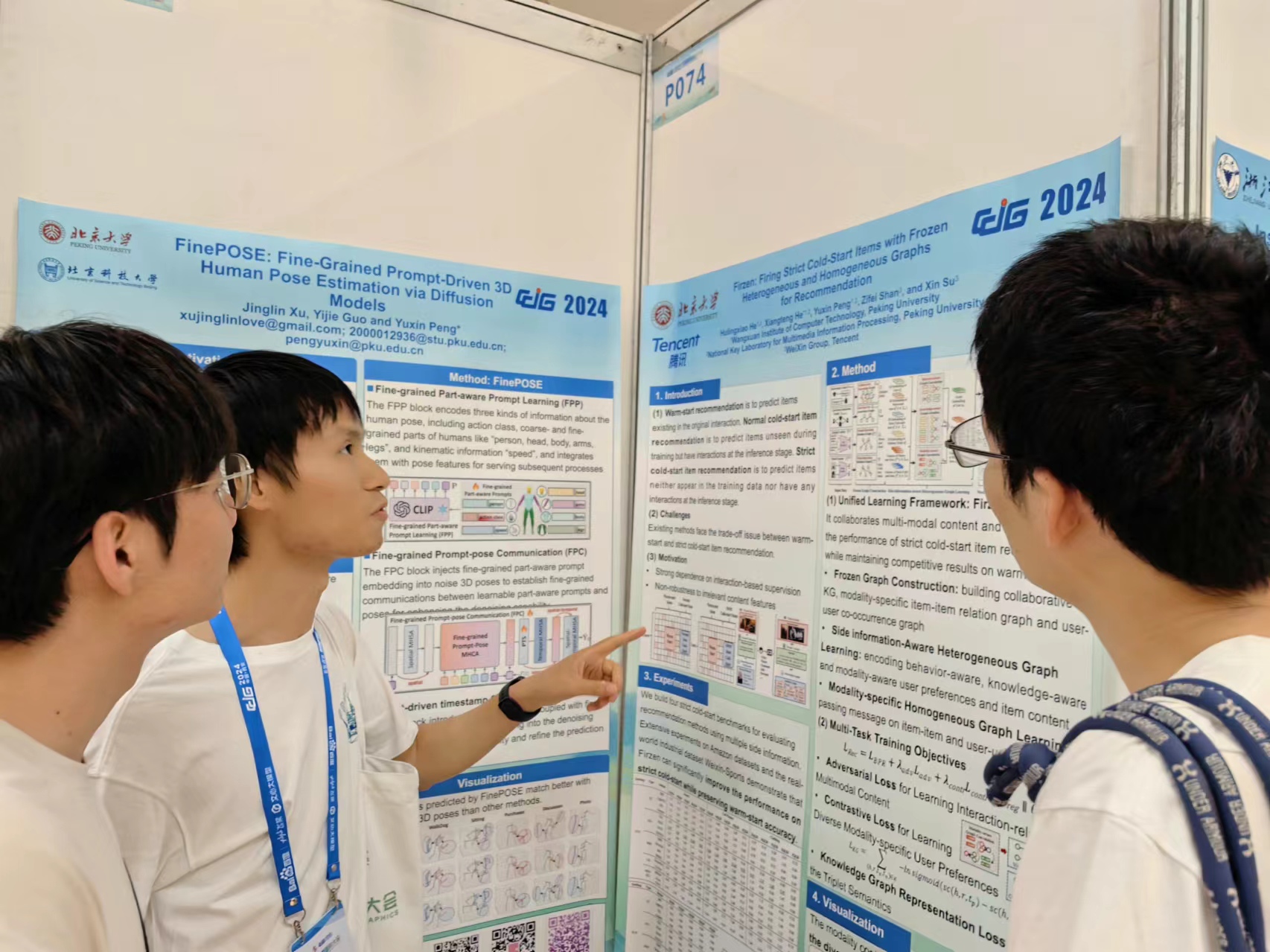
何胡凌霄同学做墙报展示
[3] Jinglin Xu, Guohao Zhao, Sibo Yin, Wenhao Zhou and Yuxin Peng*, "FineSports: A Multi-person Hierarchical Sports Video Dataset for Fine-grained Action Understanding", 37th IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle WA, USA, June 17 - 21, 2024.
该论文针对时空定位任务中缺少细粒度标注数据集的问题,提出了一个新的多人场景的体育运动视频数据集FineSports,该数据集包含12个粗粒度和52个细粒度动作类别,以及密集标注的球员空间边界和动作时间边界。论文还提出了时空动作定位方法PoSTAL,由提示驱动的目标动作编码器PTA和目标动作时空检测器ATD组成;首先利用PTA模块在描述性提示的引导下提取目标动作特征,然后将其送入ATD模块同时获得目标动作tube和相应的细粒度动作类型,无需进行候选区域的生成,提高了时空定位的准确性。
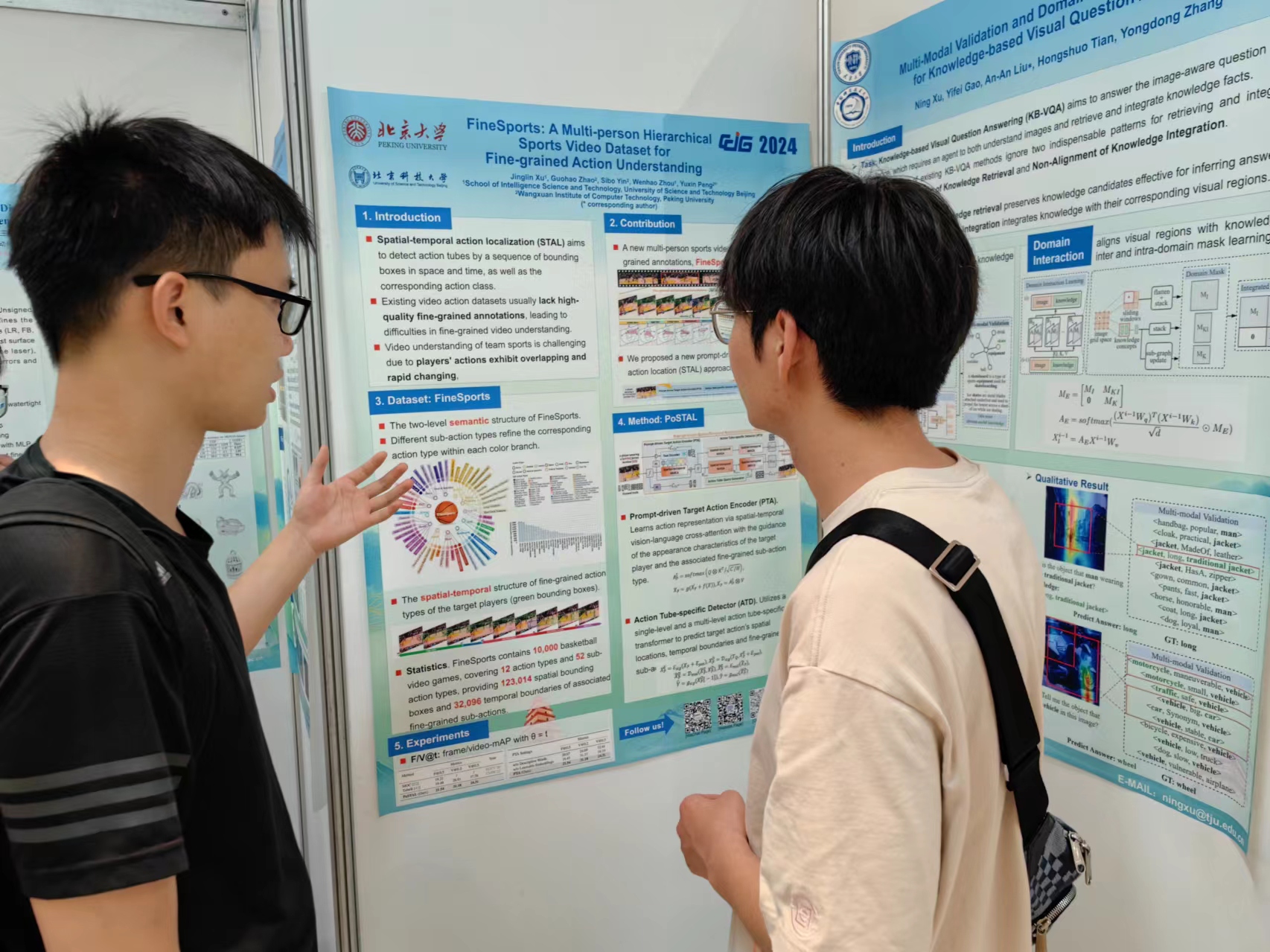
赵国豪同学做墙报展示
CCIG每年召开一次,是中国图象图形学学会的年度旗舰会议,涵盖图像图形各专业领域。本次会议吸引了2000余名科研院校师生、一线技术工程师前来参会。会议包括学术论坛、主题报告和墙报展示等环节。
[1] Jinglin Xu, Sibo Yin, Guohao Zhao, Zishuo Wang and Yuxin Peng*, "FineParser: A Fine-grained Spatio-temporal Action Parser for Human-centric Action Quality Assessment", 37th IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle WA, USA, June 17 - 21, 2024, (Oral, 3.3%).
该论文针对动作质量评估任务(Action Quality Assessment,AQA)提出以人为中心的时空动作解析方法:首先设计空间动作解析器(SAP),用以捕获以人为中心的前景动作的多尺度表征,重点关注每一帧的目标动作区域,保证在空间解析的有效性。其次设计时间动作解析器(TAP),通过学习视频的时空表征将目标动作解析为连续的步骤来建模人体动作的语义一致性和时间相关性。然后设计静态视觉编码器(SVE),通过捕获每一帧详细的上下文信息来增强目标动作表征。最后设计细粒度对比回归器(FineReg)捕获成对目标动作步骤之间的细粒度差异,并评估动作质量。
[2] Jinglin Xu, Yijie Guo and Yuxin Peng*, "FinePOSE: Fine-Grained Prompt-Driven 3D Human Pose Estimation via Diffusion Models", 37th IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle WA, USA, June 17 - 21, 2024, (Highlight, 11.9%).
该论文针对三维人体姿态估计任务提出了基于扩散模型的细粒度提示驱动的三维人体姿态估计方法,首先对文本信息和人体自然先验知识进行编码,其次将编码特征与可学习提示相结合,构建基于细粒度姿态感知的可学习提示,然后在所学的提示与带噪的三维人体姿态表征之间建立细粒度的通信,以增强扩散模型的去噪能力。
[3] Jinglin Xu, Guohao Zhao, Sibo Yin, Wenhao Zhou and Yuxin Peng*, "FineSports: A Multi-person Hierarchical Sports Video Dataset for Fine-grained Action Understanding", 37th IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle WA, USA, June 17 - 21, 2024.
该论文针对时空定位任务中缺少细粒度标注数据集的问题,提出了一个新的多人场景的体育运动视频数据集FineSports,该数据集包含12个粗粒度和52个细粒度动作类别,以及密集标注的球员空间边界和动作时间边界。论文还提出了时空动作定位方法PoSTAL,由提示驱动的目标动作编码器PTA和目标动作时空检测器ATD组成;首先利用PTA模块在描述性提示的引导下提取目标动作特征,然后将其送入ATD模块同时获得目标动作tube和相应的细粒度动作类型,无需进行候选区域的生成,提高了时空定位的准确性。