2023-07-26:研究室的4篇论文被ACM MM 2023接收

北京大学多媒体信息处理研究室共有4篇论文入选,成果覆盖细粒度视觉分析、电商跨模态检索、图像生成视频、扩散模型加速等研究方向。
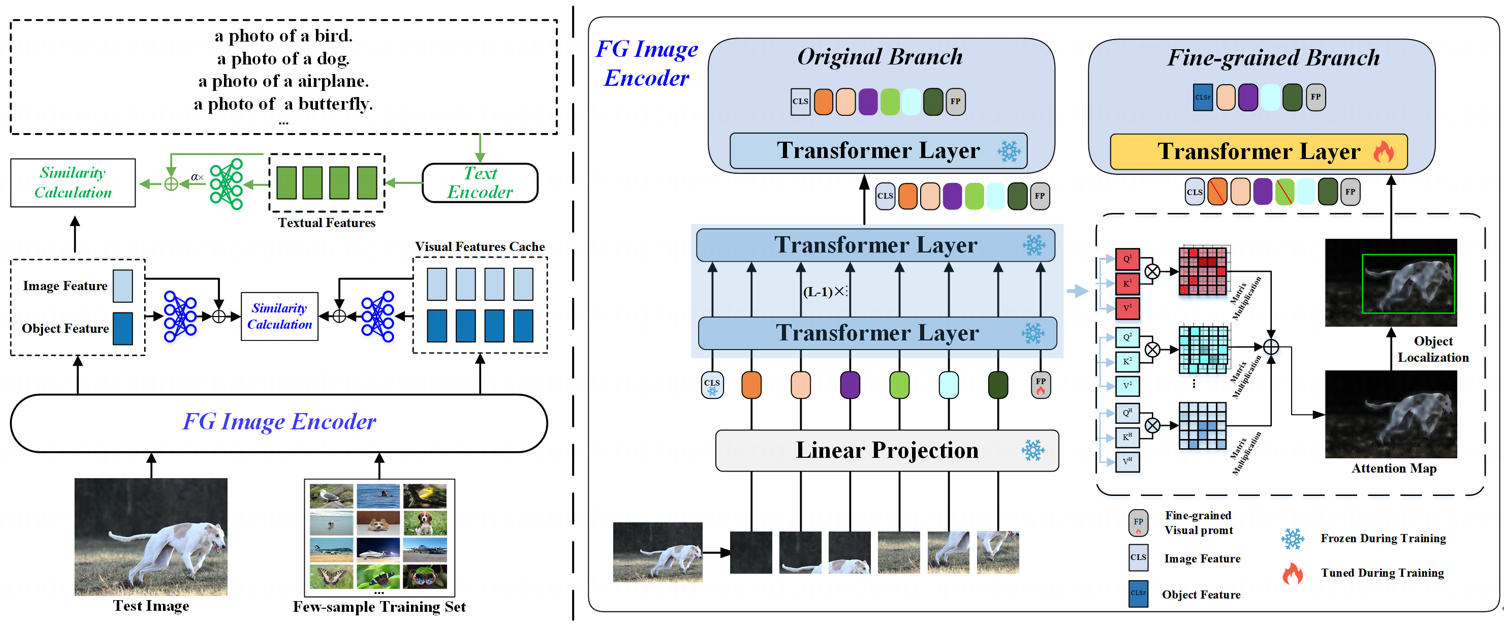
(1)基于细粒度视觉提示学习的图像分类方法
Fine-Grained Visual Prompt Learning of Vision-Language Models for Image Recognition
作者:孙宏博(博士生),何相腾,周嘉欢,彭宇新
通讯作者:彭宇新
视觉-语言预训练模型(例如CLIP)近期展现了强大的视觉表征迁移能力,在仅使用少量训练数据的情况下,在多项下游视觉任务如图像识别上取得了较好效果。为进一步增强视觉-语言预训练模型在下游视觉任务上的性能,现有方法通常在文本端引入可学习向量生成适配下游数据的模型分类层实现图像识别。然而,上述方法通常忽视了在图像端对下游数据的辨识性视觉特征学习,因此导致模型的识别性能受限。
针对上述问题,本文提出了一种细粒度视觉提示学习方法:首先在图像端引入细粒度视觉提示嵌入向量,引导模型自动寻找视觉对象并进行对象内图像块的信息交互和辨识性视觉特征提取;进一步提出双路自适应匹配机制,构建适配网络并分别使用视觉-语言预训练模型的跨模态匹配知识和下游小样本训练数据的视觉信息进行相似性计算,减小下游任务数据与预训练数据间的域间差异,最终提高模型的识别准确率。实验结果表明,在小样本设置下,本文方法在11个常用图像识别数据集(包括普通图像分类数据集ImageNet,细粒度图像分类数据集FGVCAircraft等)上均达到了领域最佳水平。
该论文的第一作者是北京大学王选计算机研究所2019级博士生孙宏博,通讯作者是彭宇新教授,由何相腾助理研究员、周嘉欢助理教授共同合作完成。
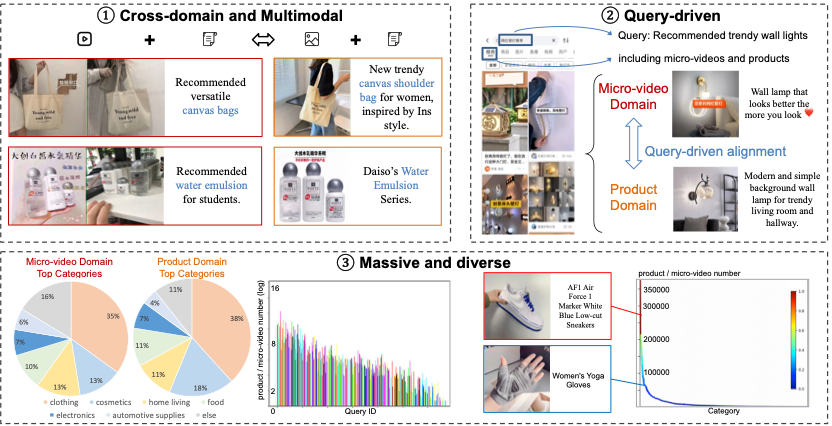
(2)Real20M:面向跨模态检索任务的大型电子商务数据集
Real20M: A Large-scale E-commerce Dataset for Cross-domain Retrieval
作者:陈彦哲(硕士生),钟华松,何相腾,彭宇新,成乐乐
通讯作者:彭宇新
跨模态检索旨在根据输入的商品视频/商品图像/商品介绍文本检索最相关的商品,实现对商品的精准检索和个性化推荐,是智能电商平台的关键技术。现有针对商品的检索研究多聚焦在以图搜图和以文搜图,忽略了商品视频这一重要载体,以及商品图片的相关文本。同时,现有研究仍缺乏大型的公开数据集和评测基准的支持。
针对上述问题,本文提出了面向商品视频和商品图片检索任务的大型电子商务数据集Real20M。该数据集是首个同时包含商品视频、商品图片以及商品相关文本的多模态电商数据集。其贡献主要体现在以下三个方面:(1)模态多样性:Real20M提供商品视频、商品图片以及商品相关文本内容,验证方法在现实应用场景中的泛化能力;(2)用户查询驱动:Real20M通过收集自用户的查询将视频和图片对齐,高效地将海量电商数据进行关联;(3)样本丰富性:Real20M包含超过2千万个样本数以及1714个类别,足以支持复杂的检索任务。基于上述提出的数据集,本文提出三级实体词预训练算法,通过自适应调节不同粒度实体词的权重,提高模型对商品视频及商品细节的建模能力;进一步提出基于查询的跨域对比学习算法,将商品视频和商品图片围绕查询关联并对齐,实现视频与图片之间的精准检索。实验结果验证了新基准和新方法的有效性。
该论文的第一作者是北京大学王选计算机研究所2022级硕士生陈彦哲,通讯作者是彭宇新教授,由何相腾助理研究员、钟华松(快手公司)、成乐乐(快手公司)共同合作完成。
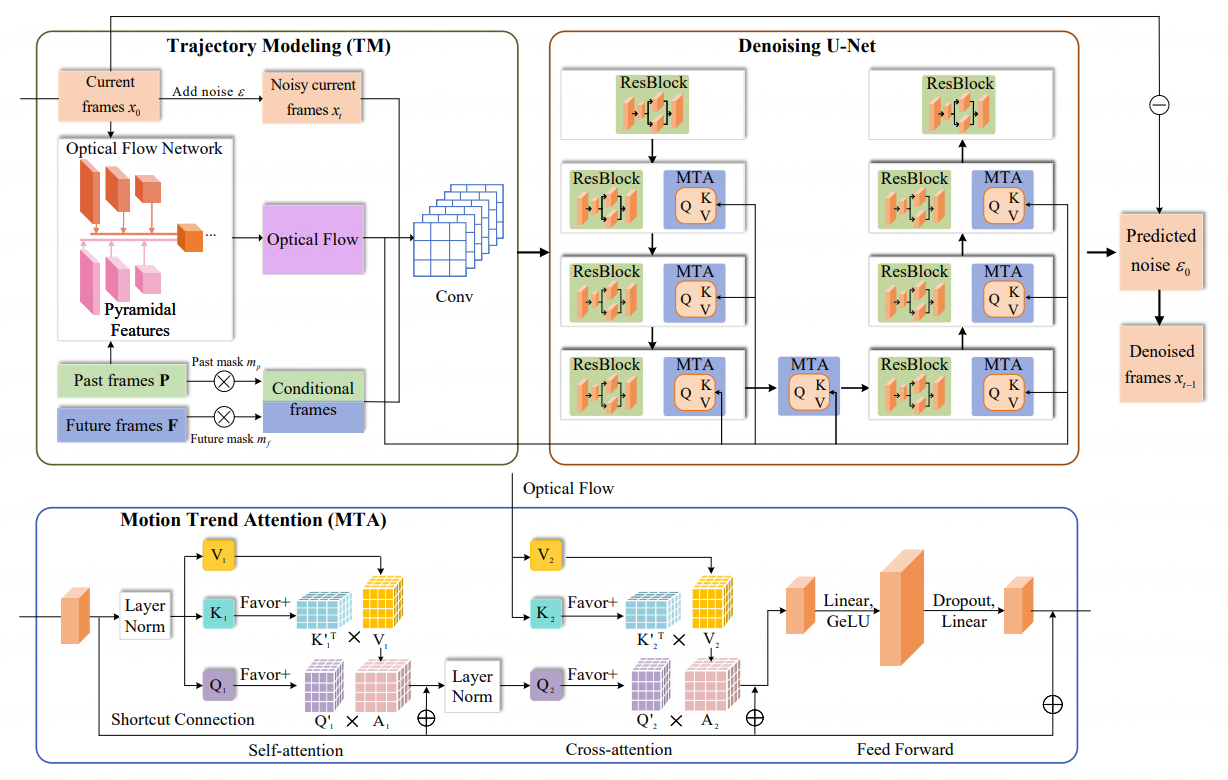
(3)运动感知的视频扩散模型
MV-Diffusion: Motion-aware Video Diffusion Model
作者:邓梓焌(直博生),何相腾,彭宇新,朱雄威,成乐乐
通讯作者:彭宇新
根据图像或条件帧生成连贯、流畅的视频是一个具有挑战性的问题,需要对视频中的运动进行建模。现有方法主要在视频局部的RGB帧窗口内提取隐式的运动特征,而不是显式地对运动进行建模,导致生成的视频中动作幅度偏小,且出现无规则的抖动。
针对上述问题,本文提出了运动感知的视频扩散模型,通过利用全局上下文中的轨迹信息并显式建模局部运动趋势,增强生成的视频的连贯性。本文的主要贡献包括:(1)轨迹建模模块,通过提取全局的运动轨迹来增强模型接收到的时间维度信息;(2)运动趋势注意力,利用交叉注意机制显式地从光流中推断运动趋势,而不是隐式地从RGB输入中学习。本文在视频预测、视频插帧和无条件视频生成三个任务上进行了广泛实验,实验结果显示了方法的有效性。
该论文的第一作者是北京大学王选计算机研究所2022级直博生邓梓焌,通讯作者是彭宇新教授,由何相腾助理研究员、朱雄威(快手公司)、成乐乐(快手公司)共同合作完成。
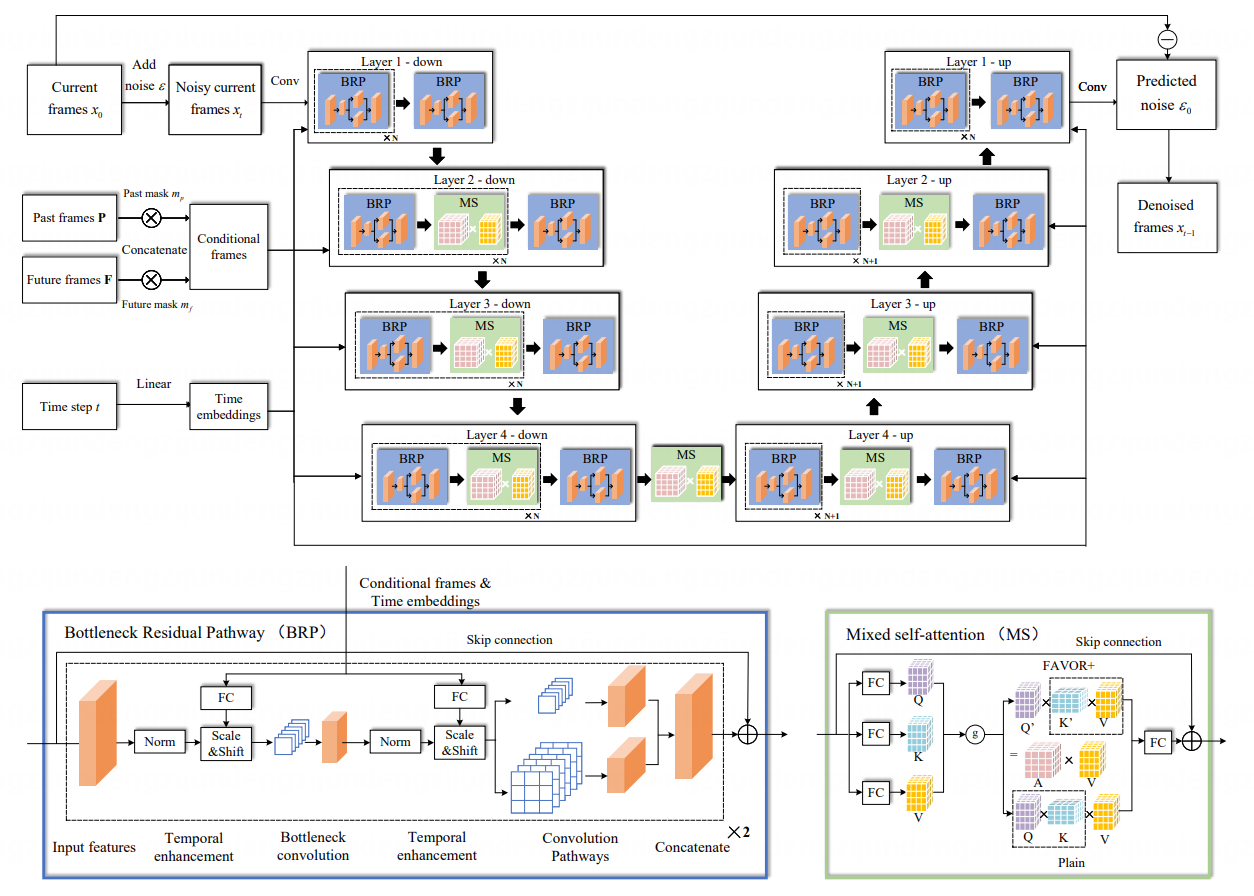
Efficiency-optimized Video Diffusion Models
作者:邓梓焌(直博生),何相腾,彭宇新
通讯作者:彭宇新
视频扩散模型在生成高保真度视频方面展现出强大能力,在视频预测、视频插帧和无条件视频生成等多个下游任务上取得了当前最佳性能。然而,视频扩散模型的生成能力很大程度上归功于利用大型去噪模型来逆转漫长的加噪过程,这也带来了极高的采样和训练成本。
针对上述问题,本文提出了效率优化的视频扩散模型,通过减少卷积操作的冗余性来降低网络的计算成本。首先,本文提出了瓶颈残差通路,通过对卷积路径进行逐通道降采样,从输入中提取关键信息并降低计算成本。其次,本文提出了三通道拆分策略,通过使用更高效的逐点卷积和残差连接路径来处理部分输入通道,从而减少通道冗余。最后,本文提出了一种混合自注意机制,根据输入向量维度自适应地选择具有较低时间复杂度的算法,来优化网络中自注意力的计算成本。本文方法在视频预测、视频插帧和无条件视频生成三个下游任务上进行了大量实验,在4个数据集上的结果显示本文方法比现有方法生成视频的质量更好,并且计算量减小了10倍。
该论文的第一作者是北京大学王选计算机研究所2022级直博生邓梓焌,通讯作者是彭宇新教授,由何相腾助理研究员共同合作完成。
相关链接: 北京大学多媒体信息处理研究室的4篇论文被ACM MM 2023录用