
2023-07-14:研究室的4篇论文被ICCV 2023接收

北京大学多媒体信息处理研究室共有4篇论文入选,成果覆盖视频语义定位、人物交互检测、跨域目标检测和弱监督视觉定位等研究方向。
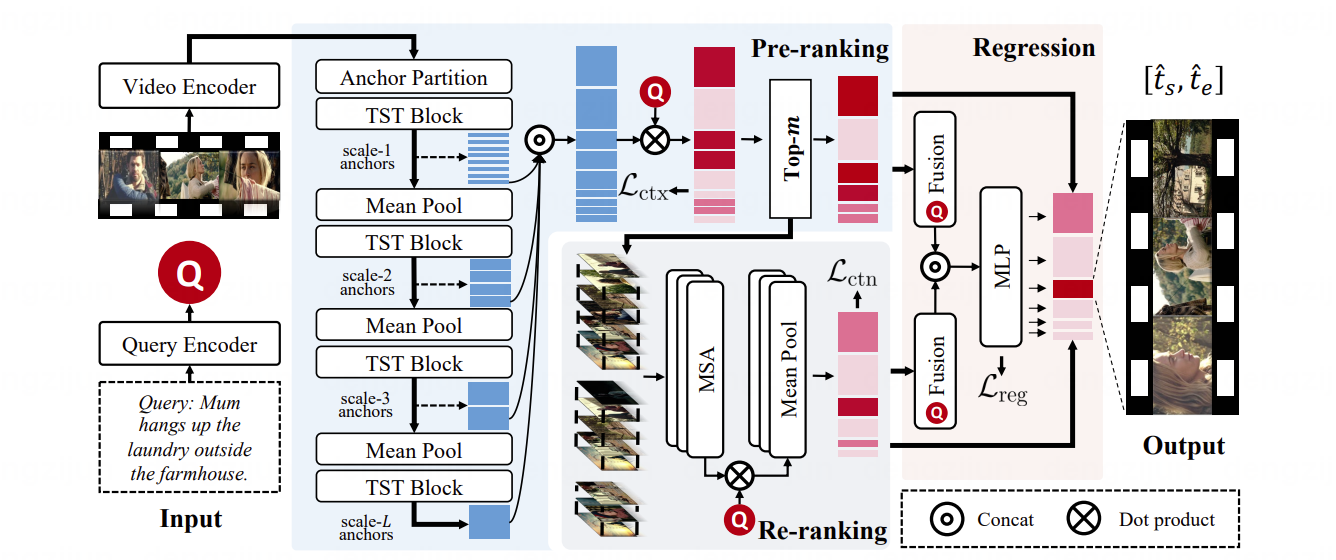
(1)面向长视频的端到端快速语义定位网络
Scanning Only Once: An End-to-end Framework for Fast Temporal Grounding in Long Videos
论文作者:Yulin Pan, Xiangteng He, Biao Gong, Yiliang Lv, Yujun Shen, Yuxin Peng, Deli Zhao
论文链接:https://arxiv.org/abs/2303.08345
视频语义定位旨在精确定位到查询语句在长视频(小时级)中的起止时间。尽管短视频(分钟级)语义定位近期取得了一定进展,但长视频语义定位的研究仍处于初级阶段。现有方法通常采用滑动窗口(如下图上半部分所示)将长视频组织为短视频,并在每个窗口内执行时间定位,存在以下问题:(1)训练不充足:滑动窗口一次只能扫描固定时间范围的视频内容,忽略了长范围的时间相关性;(2)预测不灵活:预测被限制在一个窗口内,难以推广到持续时间长的片段;(3)推理不够快:相邻窗口间的重叠带来了冗余计算。
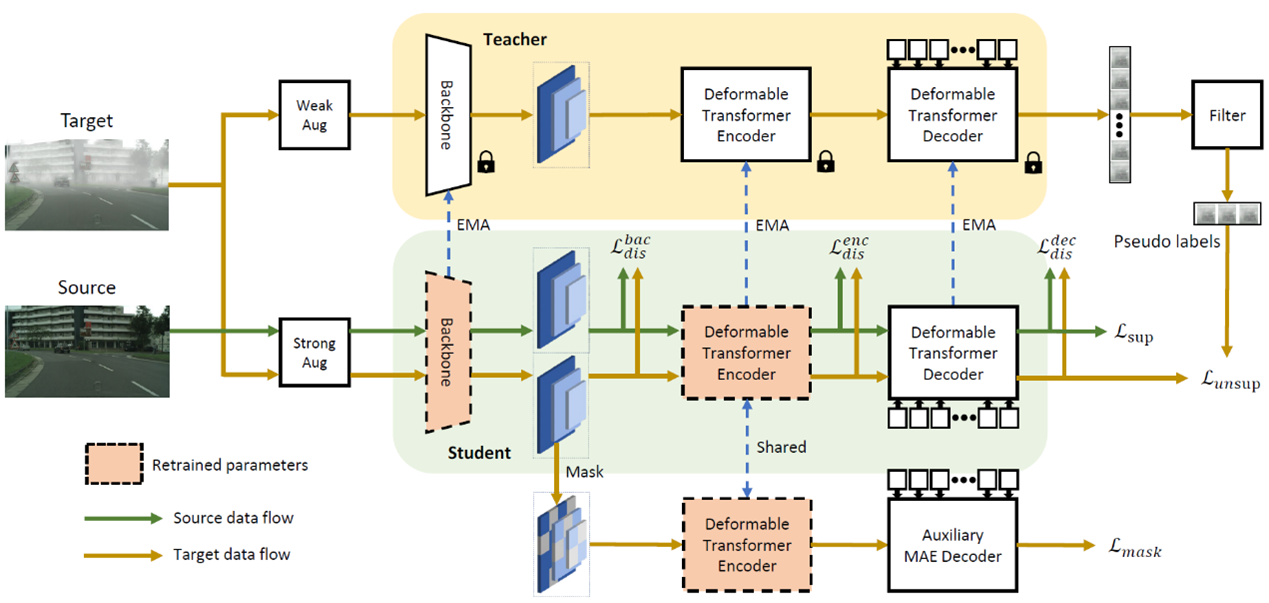
(2)基于遮蔽与重训练教师-学生框架的跨域目标检测方法
Masked Retraining Teacher-Student Framework for Domain Adaptive Object Detection
论文作者:Zijing Zhao, Sitong Wei, Qingchao Chen, Dehui Li, Yifan Yang, Yuxin Peng, Yang Liu
使用有标签数据(源域)训练的目标检测器在实际部署环境中可能遇到数据分布漂移的情况,从而影响检测性能。无监督跨域目标检任务测旨在将检测器泛化到新的数据分布(目标域)而无需额外数据标注。目前最先进的跨域方法大多采用教师-学生框架,即使用教师模型为目标域图像生成伪标签以供学生模型训练,但这些方法在目标检测任务中面临两大问题,一是生成的伪标签(检测框)数量不足,二是伪标签中存在噪声,这两大问题影响了学生模型适应目标域的能力。
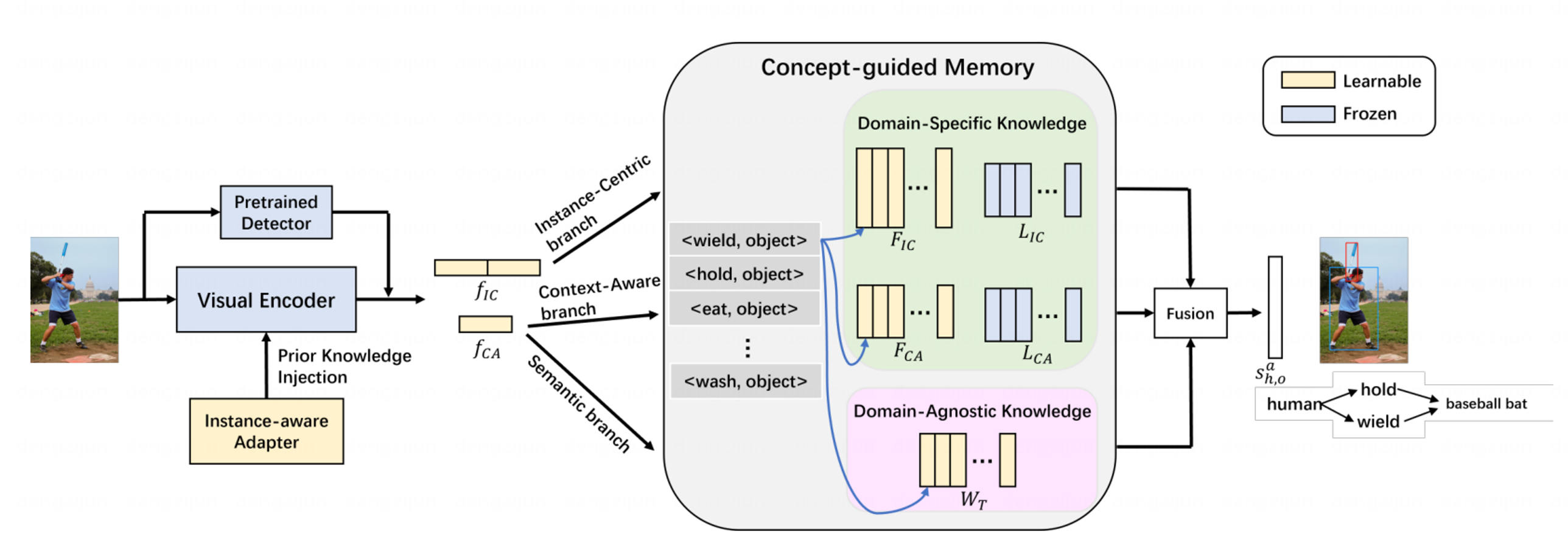
(3)基于概念引导记忆的高效自适应人物交互检测
Efficient Adaptive Human-Object Interaction Detection with Concept-guided Memory
论文作者:Ting Lei,Fabian Caba,Qingchao Chen,Hailin Jin,Yuxin Peng,Yang Liu
人与物体交互检测任务在分别检测人和物体的基础上进一步理解人与物体的关系。基于Transformer的方法在该任务上取得了显著的进展,但这类方法普遍有如下两方面问题:(1)由于训练数据呈现长尾分布,模型在少量样本的类别上性能严重受限;(2)Transformer模型计算复杂度较高,其训练和微调均需要较高的计算和时间成本。
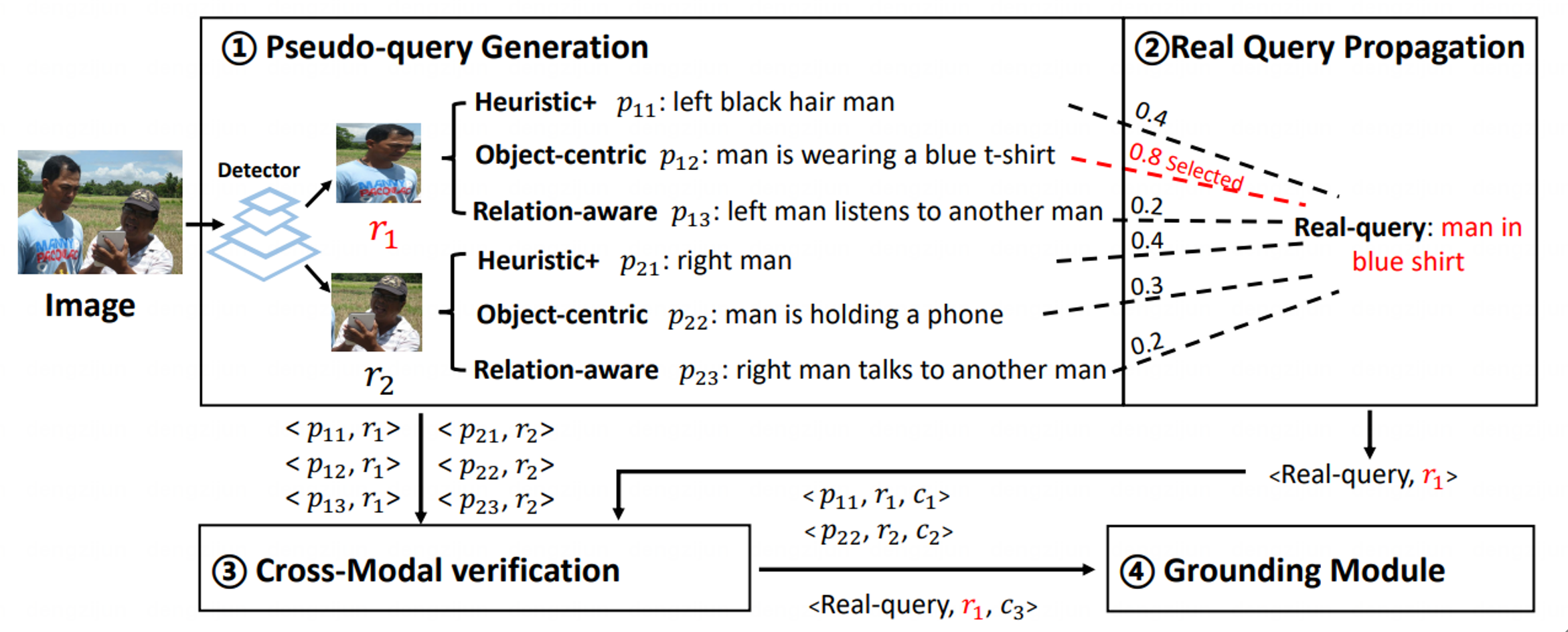
(4)基于置信度感知的弱监督视觉定位伪标签学习
Confidence-aware Pseudo-label Learning for Weakly Supervised Visual Grounding
论文作者:Jiahua Zhang, Qingchao Chen, Yuxin Peng, Yang Liu
弱监督视觉定位旨在仅有图像-文本对而没有目标物体位置标注的条件下,定位到与自然语言查询最相关的目标物体。现有的弱监督学习方法主要使用预先训练的目标检测器生成候选框,然后采用跨模态相似度得分或语言查询重建损失作为标准挑选候选框。然而,由于文本和图像间的跨模态异构差距,这些方法经常遭遇到错误跨模态关联和误差传播的问题。
相关链接: 北京大学多媒体信息处理研究室的4篇论文被ICCV 2023录用