视觉内容识别
视觉内容识别旨在使计算机能够“看懂”图像视频等视觉内容,从视觉内容中自动识别过滤有害信息,是计算机视觉领域最具有挑战和应用价值的技术之一,该技术对于维护网络内容安全具有重要意义。涉及多个领域研究,包括图像视频中关键目标的检测与识别、复杂场景的识别与理解等。在特殊标志识别与过滤、视频违规内容审核、监控异常场景检测等领域具有广阔应用前景。具体的应用场景如:
1. 特殊标志识别与过滤:视觉内容识别技术可以自动审查图片视频中的特殊标识,滤除违法违规标识,有助于防止违规标识的传播。
2. 视频违规内容审核:视觉内容识别技术可以针对网络直播、短视频等平台中的视频进行实时审核,检测违法违规内容,有助于遏制有害内容传播蔓延,营造清朗网络空间。
3. 监控异常场景检测:视觉内容识别技术可以针对家庭、校园、道路等场景的监控视频进行审查,监测异常场景或者潜在威胁事件,通知安防人员快速做出反应,提高社会安全水平,提升公民安全感,降低安防人员的劳动强度。
组内相关论文
1.针对如何有效提取视频中的静态和动态信息问题,提出空间-时间注意力机制的双流协同学习方法,使用空间级注意力网络来强调帧的显着区域,并使用时间级注意力网络来利用视频中的判别帧,两者联合优化
并相互增强以利用区分特征;同时利用时空注意力模型提取的有判别性的静动特征,相互增强表示学习,优化视频分类的帧和光流的组合权重。[1]。
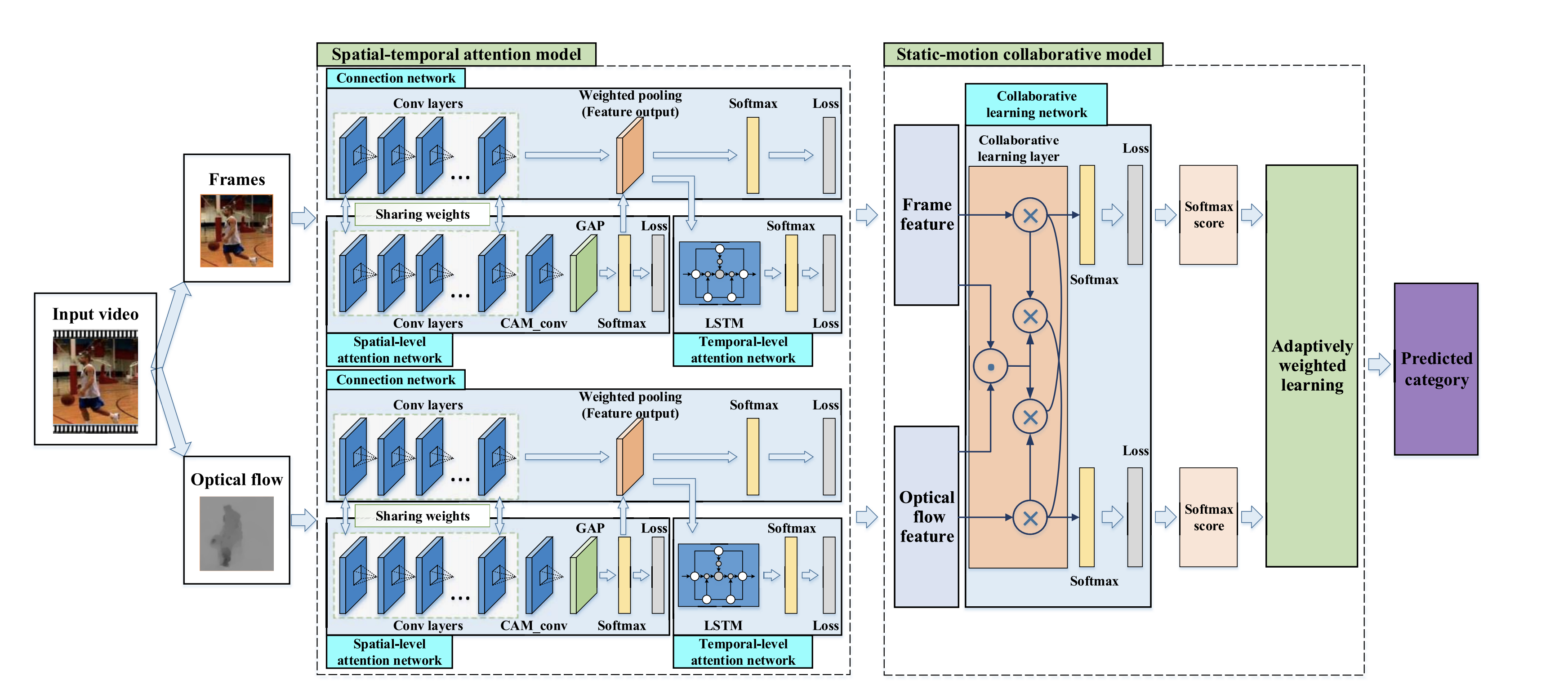
方法流程图
2.针对行人检测中判别式特征提取问题,提出判别式潜在语义特征学习方法,将潜在语义特征学习表述为特定的稀疏编码问题,将图像的特征表示的字典和稀疏系数进行优化,然后提出在特征学习阶段通过将最大边际标准纳入上述潜在语义学习问题中,获取具有更丰富的语义信息和鲁棒性的判别式行人特征.[2]
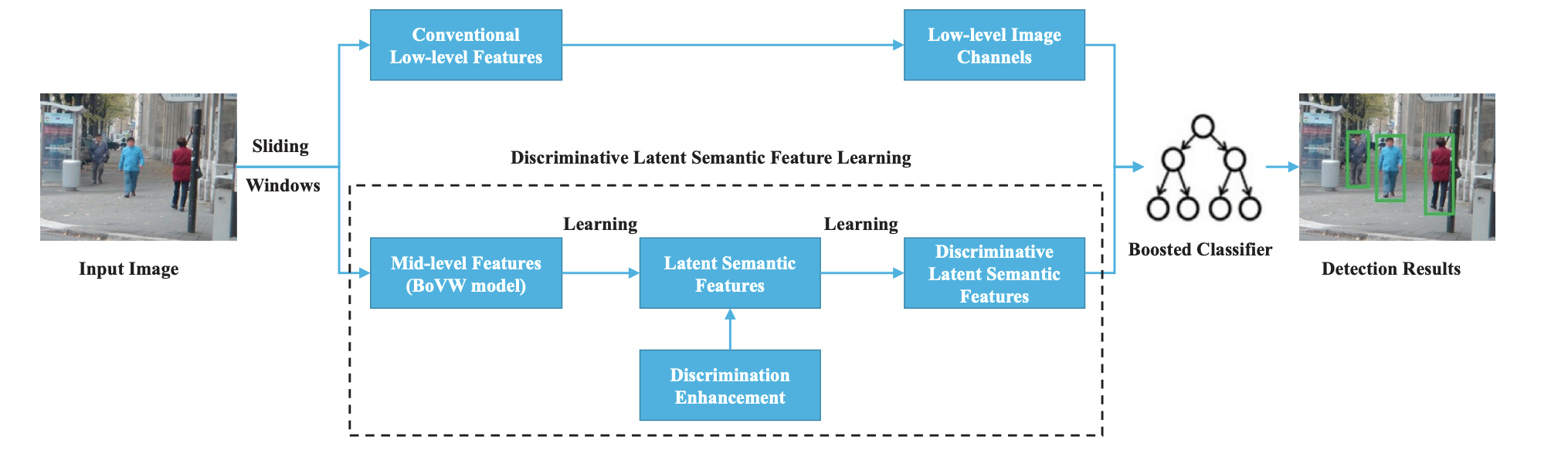
方法流程图
3.针对行人检测中图像分辨率降低带来性能下降的问题,提出基于组成本敏感的Boosting方法,探索了在Boosting过程中不同分辨率组的不同成本来扩展AdaBoost的性能,并更加强调硬低分辨率样本,可更好地处理多分辨率检测。[3]

方法流程图
[1] Yuxin Peng, Yunzhen Zhao and Junchao Zhang, "Two-Stream Collaborative Learning With Spatial-Temporal Attention for Video Classification", IEEE Transactions on Circuits and Systems for Video Technology (TCSVT), Vol. 29, No. 3, pp. 773-786, Mar. 2019.
[2] Chao Zhu and Yuxin Peng, "Discriminative Latent Semantic Feature Learning for Pedestrian Detection", Neurocomputing, Vol. 238, pp. 126-138, May. 2017.
[3] Chao Zhu and Yuxin Peng, "Group Cost-Sensitive Boosting for Multi-Resolution Pedestrian Detection", 30th AAAI Conference on Artificial Intelligence (AAAI), pp. 3676-3682 , Phoenix, Arizona, USA, Feb. 12–17, 2016.(Oral, Full Paper)