视频描述生成
视频描述生成(Video Captioning)是指计算机根据输入视频,自动生成描述其内容的自然语言文本语句,是一个视觉内容向自然语言转化的跨模态生成任务。课题组围绕时空关联分析的视频描述生成展开研究,针对视频内容理解和视觉-语言跨模态映射两个关键问题,提出了对象感知双向图、层次化视觉-语言对齐等方法,旨在生成语义一致、通顺流畅的自然语言文本语句。视频描述生成可应用于视频检索、视频解说、自动生成商品描述等,具有重要的研究和应用价值。

|
组内相关论文
1.针对视频细粒度时空信息建模问题,提出对象感知双向图方法,从正时序和逆时序方向建立互补的双向时序图,通过建模多个对象动态时序轨迹,生成描述对象时序演化的自然语言文本[1][2]。

方法流程图

实验效果图
2.针对视频和文本语句语义一致性建模问题,提出层次化视觉-语言对齐方法,通过二元记忆循环网络利用视觉内容与本文语句之间不同粒度的隐含对齐关系,指导生成准确的视频文本描述[3]。
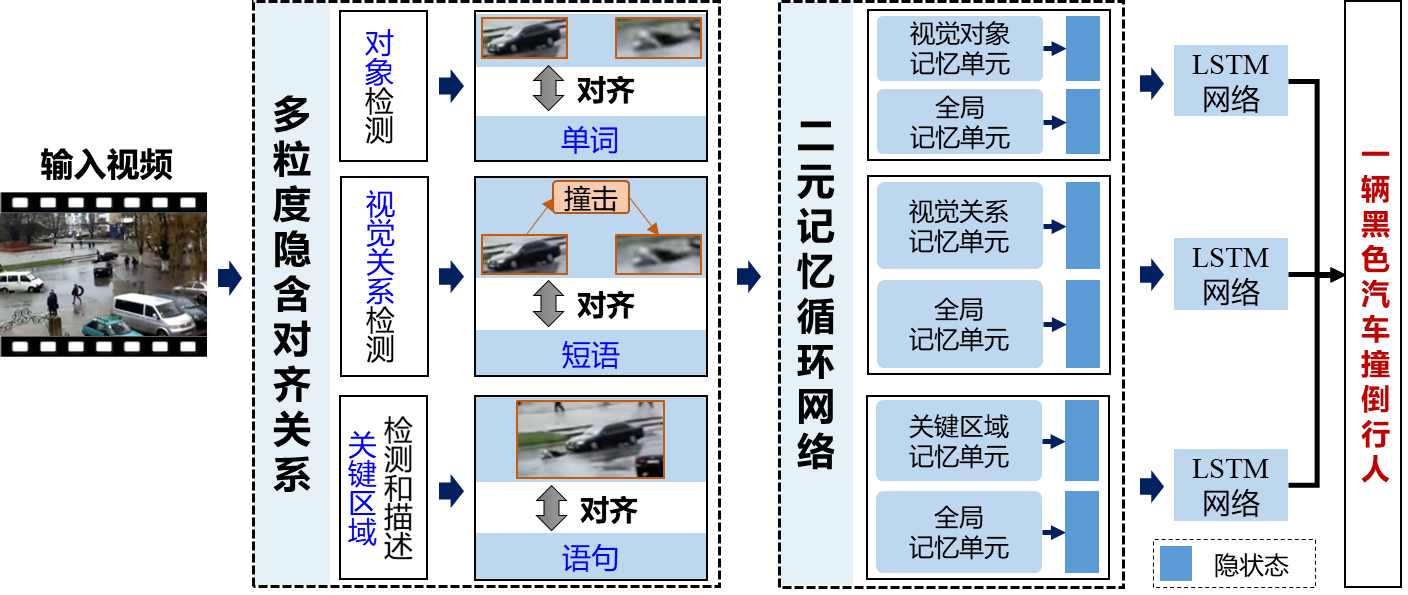
方法流程图

对比实验结果
[1] Junchao Zhang and Yuxin Peng, "Video Captioning with Object-Aware Spatio-Temporal Correlation and Aggregation", IEEE Transactions on Image Processing (TIP), Vol. 29, pp. 6209-6222, 2020.
[2] Junchao Zhang and Yuxin Peng, "Object-aware Aggregation with Bidirectional Temporal Graph for Video Captioning", 32nd IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pp. 8327–8336, Long Beach, California, USA, Jun. 16-20, 2019.
[3] Junchao Zhang and Yuxin Peng, "Hierarchical Vision-Language Alignment for Video Captioning", 25th International Conference on MultiMedia Modeling (MMM), pp. 42-54, Thessaloniki, Greece, Jan. 8-11, 2019. (Best Paper)