
文本到视觉生成
文本到视觉生成旨在使计算机能够根据给定文本进行“联想”与“创造”,自动生成语义一致、内容真实且符合逻辑的图像、视频、3D图形等视觉内容,是从“感知智能”迈向“认知智能”的一项里程碑式任务。课题组围绕跨媒体知识驱动的文本生成视觉内容开展研究,包括跨媒体知识库构建、知识驱动的视觉表征与推理、多层实体映射的细粒度图像生成、基于时空场景图建模的视频生成等理论与方法,旨在建立文本到视觉内容的跨媒体映射与生成框架,生成语义一致、内容真实、符合逻辑的视觉内容。在教育、数字阅读、短视频等领域具有广阔应用前景。具体的应用场景包括:
1. 儿童教育:文本生成视觉内容技术能够自动生成故事视频,帮助儿童直观形象地理解故事内容,有助于儿童启蒙教育。

|

|

|
2. 可视化阅读:文本生成视觉内容技术能够为中小学课本中的散文、诗歌等自动生成图像或者视频,例如给荷塘月色这样的散文自动生成生动的图像或视频,有助于提升教学效果。

3. 家装设计:文本生成视觉内容技术能够根据家装设计方案,自动生成设计效果图,将抽象的设计与创意可视化,提高用户体验效果。

4. 影视创作:文本生成视觉内容技术能够根据故事或剧本生成对应的动画或电影片段,降低视频创作门槛,实现人人都能当导演。

|

|

|
组内相关论文
1.针对如何利用通用判别模型学习到的底层像素和高层语义知识,指导文本生成图像模型的学习问题,提出对称蒸馏网络方法,通过蒸馏学习机制,将知识从通用判别网络迁移到具有对称结构的图像生成网络中,建立文本空间到图像空间的映射,生成与文本内容相符的图像[1]。
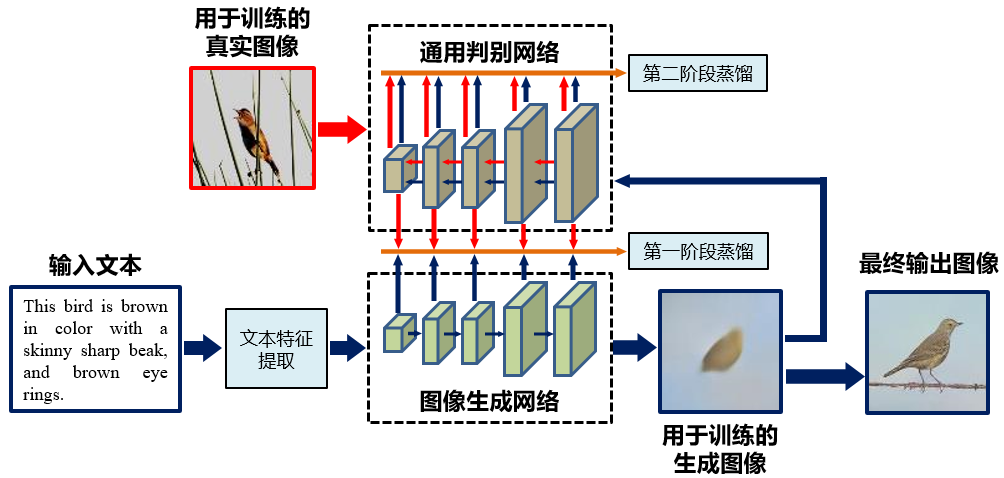
方法流程图

对比实验结果
2.针对生成过程可解释性的问题,提出可解释特征学习机制,设计过渡映射网络增强特征的可解释性,提高特征对于生成图像细节的控制能力,进而利用生成式对抗网络生成与文本内容相符的图像[2]。
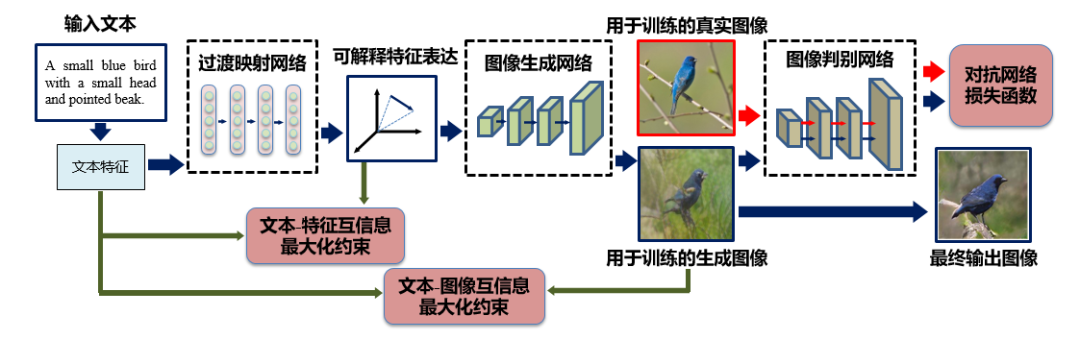
方法流程图

对比实验结果
3.针对文本到视频生成中如何保证视频的时序一致性和与文本描述的语义一致性问题,提出递归反卷积对抗网络,通过建模已有帧的时序信息增强生成视频的时序一致性,提升生成视频的流畅度,并通过互信息约束指导生成与文本语义一致的视频[3]。
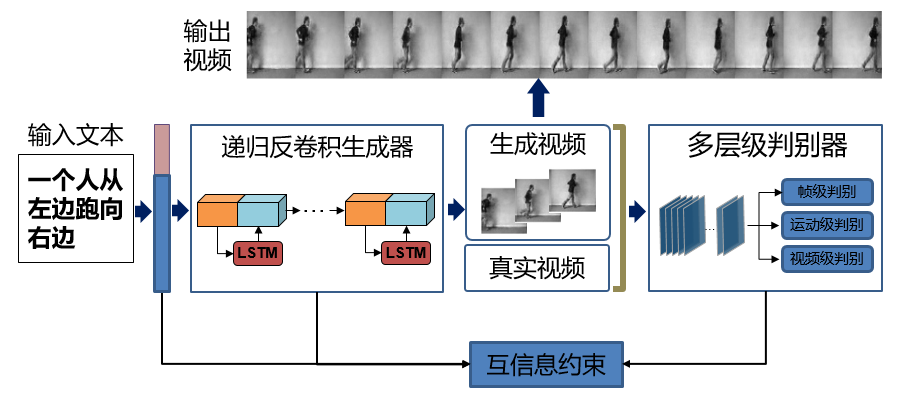
方法流程图
[1] Mingkuan Yuan and Yuxin Peng, "Text-to-image Synthesis via Symmetrical Distillation Networks", 26th ACM Multimedia Conference (ACM MM), pp. 1407-1415, Seoul, Korea, Oct. 22-26, 2018.
[2] Mingkuan Yuan and Yuxin Peng, "Bridge-GAN: Interpretable Representation Learning for Text-to-image Synthesis", IEEE Transactions on Circuits and Systems for Video Technology (TCSVT), Vol. 30, No. 11, pp. 4258-4268, Nov. 2020.
[3] Kangle Deng, Tianyi Fei, Xin Huang and Yuxin Peng, "IRC-GAN: Introspective Recurrent Convolutional GAN for Text-to-video Generation", 28th International Joint Conference on Artificial Intelligence (IJCAI), pp. 2216-2222, Macao, China, Aug. 10-16, 2019. (该论文发表时,第一作者邓康乐与费天一均为北大大三学生)