
2026-05-08:MIPL师生参加 VALSE 2026
2026年5月8日至10日,视觉与学习青年学者研讨大会(Vision and Learning Seminar, VALSE 2026)在湖北省武汉市召开。MIPL彭宇新教授、博士生杨至文、邓梓焌、何胡凌霄、李耕、尹思博、赵国豪、郑翔天、都天翔、姚宇晗、耿子竣、郑明航、徐铸,硕士生王梓烁、谭智、王宇昊参加了此次会议。
VALSE每年举办一次,自2011年发起以来,始终秉持“学术为先、学生为本、交流为要”的初心使命,致力于为计算机视觉、图像处理、模式识别、多媒体与机器学习研究领域内的中国青年学者提供一个深层次、纯粹学术交流的舞台。
彭宇新教授作为中国图像图形学学会副理事长进行了大会开幕式致辞,并受邀作题为“细粒度多模态大模型”的年度进展报告,系统梳理了该领域的最新动态。报告围绕类别感知、空间推理及时间运动分析等核心维度,深入探讨了多模态大模型如何兼顾开域泛化与细粒度感知能力,并详细介绍了细粒度图像分类、空间理解与占用预测、美学理解及运动分析等前沿方向,剖析了现有技术优势、不足与应用场景,最后展望了该领域的未来发展趋势。
彭宇新教授组织举办多模态大模型研讨会,聚焦细粒度多模态大模型、原生多模态、大模型安全等前沿方向,探讨多模态大模型在视觉感知、图形设计、语音建模等领域的创新与应用,并展望多模态大模型的未来趋势与潜在突破。


彭宇新教授在开幕式上进行致辞

彭宇新教授应邀进行《细粒度多模态大模型》年度进展报告

MIPL师生会场合影
(前排从左到右:赵国豪、耿子竣、姚宇晗、郑翔天、尹思博;后排从左到右:
王梓烁、谭智、李耕、王宇昊、彭宇新教授、都天翔、杨至文、何胡凌霄)
本次大会MIPL共有四篇论文被选中进行墙报展示,论文信息如下:
[1] Hulingxiao He, Zijun Geng and Yuxin Peng*, "Fine-R1: Make Multi-modal LLMs Excel in Fine-Grained Visual Recognition by Chain-of-Thought Reasoning", The Fourteenth International Conference on Learning Representations (ICLR), Rio de Janeiro, Brazil, Apr. 23-27, 2026. 【pdf】【source code】【量子位报道】【极市平台报道】【CVer报道】【宣传海报】【Slides】
该论文针对细粒度视觉识别所需训练数据规模大,且难以泛化到训练集外子类别的问题,提出了思维链推理增强的细粒度视觉识别大模型Fine-R1,通过思维链监督微调与三元组增强策略优化,提升了大模型运用训练集已有细粒度子类别知识进行未见推理未见子类别的能力,在每类仅需4张训练图像的情况下,对训练集内外子类别的识别准确率均超越了CLIP等判别式模型。
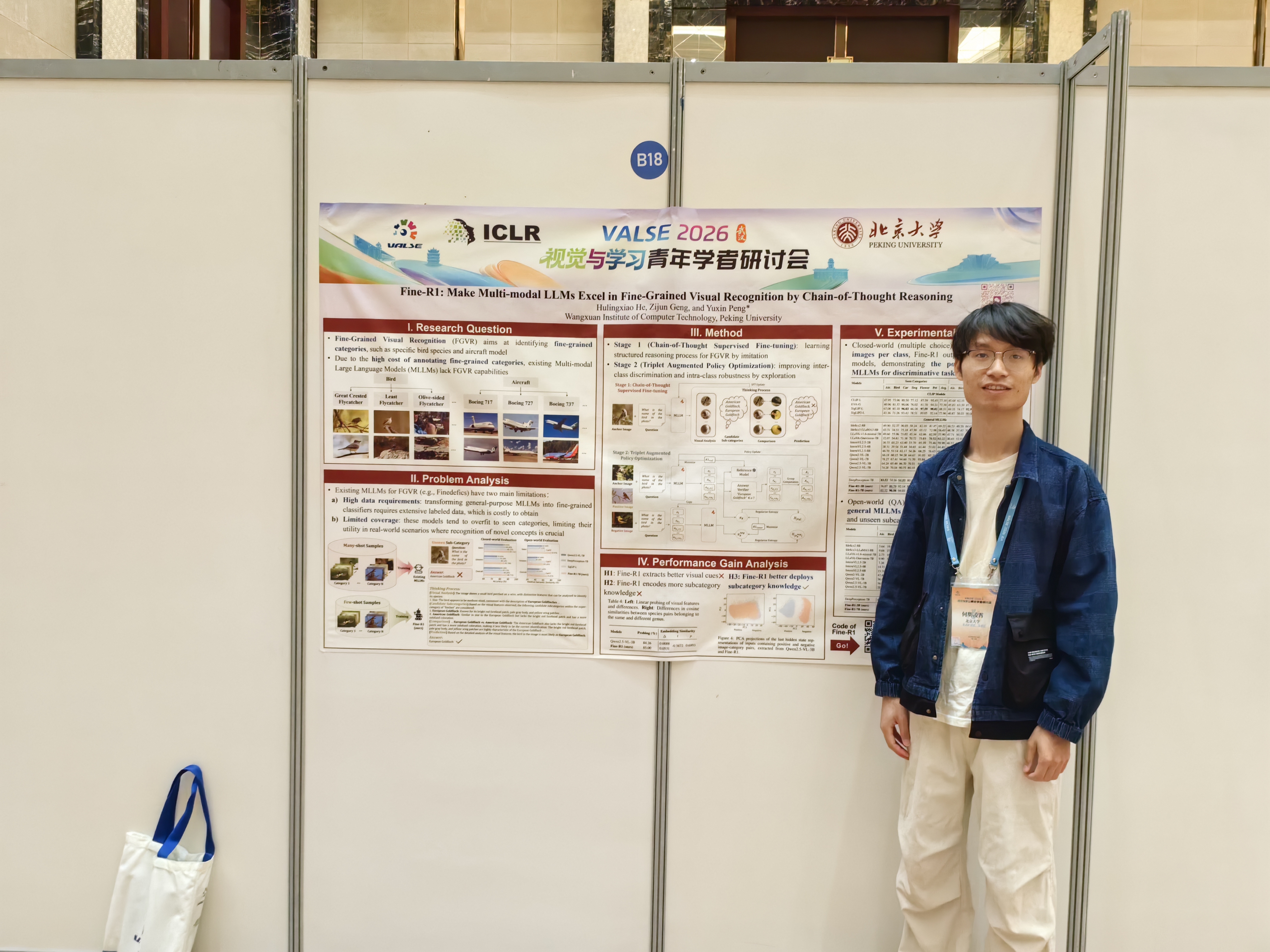

何胡凌霄同学墙报展示
[2] Guohao Zhao and Yuxin Peng*, "PG-VTON: Single-Pass Training-Free Virtual Try-On via Patch-Guided Reference Alignment", The IEEE/CVF Conference on Computer Vision and Pattern Recognition 2026 (CVPR), Denver CO, USA, Jun. 3-7, 2026. (Accept)【pdf】【source code】
该论文针对现有虚拟换装方法依赖特定数据集训练、跨域泛化不足,以及免训练方法推理流程复杂、计算开销较高等问题,提出单阶段免训练虚拟换装方法 PG-VTON。该方法通过图像块锚定身份引导和参考感知注意力机制,实现参考服装的高质量对齐与纹理保持,提升免训练的换装效果。
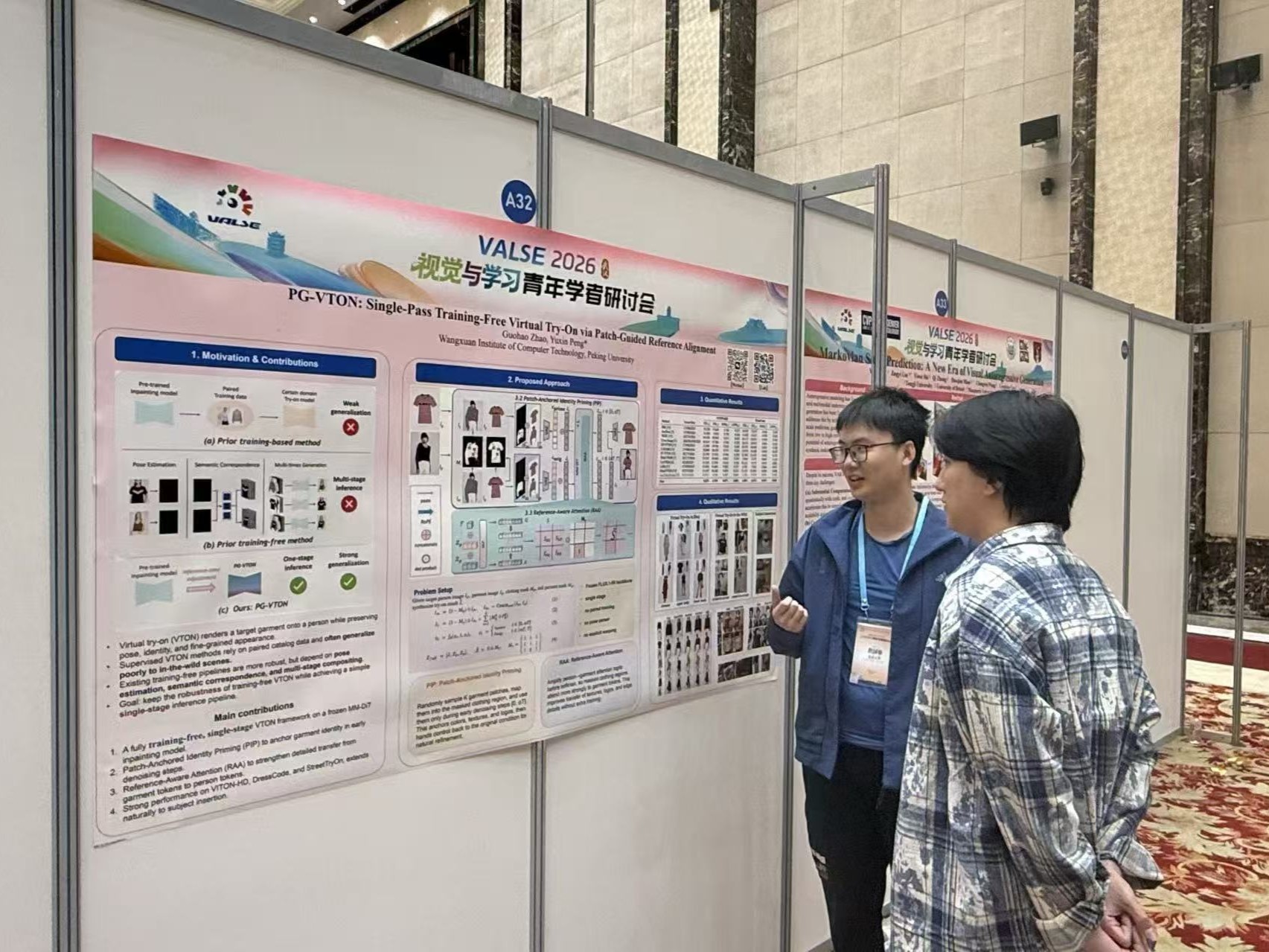

赵国豪同学墙报展示
[3] Minghang Zheng, ZihaoYin, Yi Yang, Yuxin Peng and Yang Liu*, "OmniVTG: A Large-Scale Dataset and Training Paradigm for Open-World Video Temporal Grounding", The IEEE/CVF Conference on Computer Vision and Pattern Recognition 2026 (CVPR), Denver CO, USA, Jun. 3-7, 2026. (Accept)【pdf】【source code】
该论文针对现有视频时序定位方法在开放世界场景下受限于数据集规模和语义多样性,导致在处理罕见概念时性能显著下降,以及常规监督微调难以有效弥合此差距等问题,提出了大规模开放世界数据集 OmniVTG 和一种全新的自我纠错思维链训练范式 。该方法通过自动化数据管道构建了一个大规模、语义覆盖丰富的数据集,并利用多模态大语言模型强大的视频理解能力,引导模型对初始定位预测进行反思与修正,从而大幅提升了模型处理罕见概念的能力,并在多个现有基准测试上达到了最先进的零样本定位效果。
[4] Zhu Xu, Ting Lei, Zhimin Li, Guan Wang, Qingchao Chen, Yuxin Peng and Yang Liu*, "TRKT: Weakly Supervised Dynamic Scene Graph Generation with Temporal-enhanced Relation-aware Knowledge Transferring", International Conference on Computer Vision 2025 (ICCV), Honolulu, Hawai'i, Oct. 19-23, 2025. 【pdf】【source code】
该论文针对现有弱监督动态场景图生成方法中目标检测不准确、检测置信度过低导致场景图伪标签质量过低的问题,提出时序增强的关系敏感知识迁移方法TRKT。该方法通过帧间注意力增强的知识挖掘模块,通过物体和关系解码器准确定位场景中人物和交互关系,并通过双流融合模块将注意力图与检测结果结合。实现物体定位精度和置信度的有效提升,从而获得更准确的场景图伪标签,最终有效提升弱监督场景图生成质量。

郑明航同学墙报展示

徐铸同学墙报展示
VALSE每年举办一次,自2011年发起以来,始终秉持“学术为先、学生为本、交流为要”的初心使命,致力于为计算机视觉、图像处理、模式识别、多媒体与机器学习研究领域内的中国青年学者提供一个深层次、纯粹学术交流的舞台。
彭宇新教授作为中国图像图形学学会副理事长进行了大会开幕式致辞,并受邀作题为“细粒度多模态大模型”的年度进展报告,系统梳理了该领域的最新动态。报告围绕类别感知、空间推理及时间运动分析等核心维度,深入探讨了多模态大模型如何兼顾开域泛化与细粒度感知能力,并详细介绍了细粒度图像分类、空间理解与占用预测、美学理解及运动分析等前沿方向,剖析了现有技术优势、不足与应用场景,最后展望了该领域的未来发展趋势。
彭宇新教授组织举办多模态大模型研讨会,聚焦细粒度多模态大模型、原生多模态、大模型安全等前沿方向,探讨多模态大模型在视觉感知、图形设计、语音建模等领域的创新与应用,并展望多模态大模型的未来趋势与潜在突破。
(前排从左到右:赵国豪、耿子竣、姚宇晗、郑翔天、尹思博;后排从左到右:
王梓烁、谭智、李耕、王宇昊、彭宇新教授、都天翔、杨至文、何胡凌霄)
[1] Hulingxiao He, Zijun Geng and Yuxin Peng*, "Fine-R1: Make Multi-modal LLMs Excel in Fine-Grained Visual Recognition by Chain-of-Thought Reasoning", The Fourteenth International Conference on Learning Representations (ICLR), Rio de Janeiro, Brazil, Apr. 23-27, 2026. 【pdf】【source code】【量子位报道】【极市平台报道】【CVer报道】【宣传海报】【Slides】
{kind=link}
该论文针对细粒度视觉识别所需训练数据规模大,且难以泛化到训练集外子类别的问题,提出了思维链推理增强的细粒度视觉识别大模型Fine-R1,通过思维链监督微调与三元组增强策略优化,提升了大模型运用训练集已有细粒度子类别知识进行未见推理未见子类别的能力,在每类仅需4张训练图像的情况下,对训练集内外子类别的识别准确率均超越了CLIP等判别式模型。
该论文针对现有虚拟换装方法依赖特定数据集训练、跨域泛化不足,以及免训练方法推理流程复杂、计算开销较高等问题,提出单阶段免训练虚拟换装方法 PG-VTON。该方法通过图像块锚定身份引导和参考感知注意力机制,实现参考服装的高质量对齐与纹理保持,提升免训练的换装效果。
该论文针对现有视频时序定位方法在开放世界场景下受限于数据集规模和语义多样性,导致在处理罕见概念时性能显著下降,以及常规监督微调难以有效弥合此差距等问题,提出了大规模开放世界数据集 OmniVTG 和一种全新的自我纠错思维链训练范式 。该方法通过自动化数据管道构建了一个大规模、语义覆盖丰富的数据集,并利用多模态大语言模型强大的视频理解能力,引导模型对初始定位预测进行反思与修正,从而大幅提升了模型处理罕见概念的能力,并在多个现有基准测试上达到了最先进的零样本定位效果。
[4] Zhu Xu, Ting Lei, Zhimin Li, Guan Wang, Qingchao Chen, Yuxin Peng and Yang Liu*, "TRKT: Weakly Supervised Dynamic Scene Graph Generation with Temporal-enhanced Relation-aware Knowledge Transferring", International Conference on Computer Vision 2025 (ICCV), Honolulu, Hawai'i, Oct. 19-23, 2025. 【pdf】【source code】
该论文针对现有弱监督动态场景图生成方法中目标检测不准确、检测置信度过低导致场景图伪标签质量过低的问题,提出时序增强的关系敏感知识迁移方法TRKT。该方法通过帧间注意力增强的知识挖掘模块,通过物体和关系解码器准确定位场景中人物和交互关系,并通过双流融合模块将注意力图与检测结果结合。实现物体定位精度和置信度的有效提升,从而获得更准确的场景图伪标签,最终有效提升弱监督场景图生成质量。