Benchmark for Cross-Media Retrieval
Datasets:
Wikipedia Dataset. Wikipedia dataset [1] is the most
widely-used dataset for cross-media retrieval. It is based on
Wikipedia’s "featured articles", a continually updated article
collection. There are totally 29 categories in "featured articles",
but only 10 most populated ones are actually considered.
Each article is split into several sections according to its
section headings, and this dataset is finally generated as a
set of 2,866 image/text pairs. As an important benchmark dataset
for cross-media retrieval, Wikipedia dataset has been widely
used since being publicly available.
PKU XMedia Dataset. PKU XMedia dataset [2] is a new cross-media retrieval dataset built by us.
We choose 20 categories, namely insect, bird, wind,
dog, tiger, explosion, elephant, flute, airplane, drum, train,
laughter, wolf, thunder, horse, autobike, gun, stream, piano and
violin. For each category, we collect the
data of 5 media types: 250 texts, 250 images, 25 videos, 50
audio clips and 25 3D models, so there are 600 media instances
with each category and the total number of media instances
is 12,000. All of the media instances are crawled from the
famous websites on the Internet. PKU XMedia dataset is the first
cross-media retrieval dataset with 5 media types (text, image, video,
audio and 3D model), and it can be used for more comprehensive and
fair evaluation.
NUS-WIDE Dataset. NUS-WIDE dataset [3] is a web image
dataset created by NUS’s Lab for media search, including
images and their associated tags. The images and tags are all
randomly crawled from Flickr through its public API. With the
duplicated images removed, there are 269,648 images in NUS-WIDE
dataset. To further improve the quality of tags, those
tags that do not exist in WordNet are removed. So finally 5,018
unique tags are corresponded with images, and each image is
associated with 6 tags in average. NUS-WIDE is a relatively
large dataset, but it only contains images and their tags.
Pascal VOC 2007 Dataset. The Pascal Visual Object
Classes (VOC) challenge [4] is a benchmark in visual object
category recognition and detection. Pascal VOC 2007 is the
most popular Pascal VOC dataset in cross-media retrieval. It
consists of 9,963 images from Pascal VOC challenge, and the
image annotation serves as the text modality. The annotations
are defined over a vocabulary of 804 keywords, and divided
into 20 categories. This dataset is divided into a collection of
5,011 images as the training set, and a collection of 4,952
images as the test set.
Clickture dataset. Clickture dataset [5] is a large-scale
click-based image dataset, which is collected from one-year
click-through data of a commercial image search engine. The
full Clickture dataset consists of 40 million images and 73.6
million text queries. It also has a subset Clickture-Lite with 1.0
million images and 11.7 million text queries. Following recent
works as [6], [7], we take Clickture-Lite for experimental
evaluation. The training set consists of 23.1 million query-image-click triads, where "click” is an integer to indicate the
relevance between the image and query, and the test set has
79,926 query-image pairs generated from 1,000 text queries.
Features:
For Wikipedia, PKU XMedia and Clickture datasets, we take the same strategy
as [1] to generate both text and image representations, and
the representations of videos, audio clips and 3D models
are the same as [2]. In detail, each image is represented
by a BoVW histogram of a 128-codeword SIFT codebook
and each text is represented by a histogram of a 10-topic
LDA model. Audio clips are represented by 29-dimensional
MFCC feature. Each video is segmented into several video
shots first, then 128-dimensional BoVW histogram feature
are extracted for each video keyframe. Each 3D model is
represented by the concatenated 4,700-dimensional vector of
a LightField descriptor set as described in [8].
For NUS-WIDE dataset, we use 1,000-dimensional word frequency
based tag feature and 500-dimensional BoVW image
feature provided by the authors of [3].
For Pascal VOC 2007 dataset, we use publicly available feature for
the experiment, which is just the same as [9], where
399-dimensional word frequency feature is used for text, and 512-dimensional
GIST feature is used for images. The above
feature extraction strategy is adopted for all methods in our
experiment except DCMIT [10]. because its architecture contains networks for
taking the original image and text as input. However, DCMIT
doesn’t involve corresponding networks for video, audio and
3D model, so we use extracted feature of these 3 media types,
which keeps the same as other methods.
We also conduct experiments on Wikipedia and PKU XMedia datsets, with BoW feature for text, and CNN feature for image/video, to show the performance about different feature. We use 4,096-dimensional CNN feature extracted by the fc7 layer of AlexNet, and 3,000-dimensional BoW text feature. All the compared methods are included in the experiment of feature change except DCMIT because it takes the original image and text instances as input, and doesn't need extracted image and text feature.
On Wikipedia dataset, we take 2,173 image/text pairs for training and 693 image/text pairs for testing, and PKU XMedia dataet is randomly split into a training set of 9,600 media objects and a test set of 2,400 media objects. As for NUS-WIDE, some of the URLs provided by the dataset are invalid. So we select image/text pairs that exclusively belong to one of the 10 largest categories from valid URLs, as a result the size of training set is 58,620 and the test set has a total size of 38,955. Pascal VOC 2007 dataset is split into a training set with 5,011 image/text pairs and a test set with 4,952 image/text pairs. The images containing only one object are selected in the experiment, and finally there are 2,808 image/text pairs in training set and 2,841 image/text pairs in test set.
Experimental Results:
3 retrieval tasks are conducted for the objective evaluations on cross-media retrieval:
- Multi-modality cross-media retrieval. By submitting a query example of any media type, the results of all media types will be retrieved.
- Bi-modality cross-media retrieval. By submitting a query example of any media type, the results of another media type will be retrieved.
- MMD retrieval. By submitting a query example of MMD
(A MMD consists of data with two or more media
types), the results of MMD will be retrieved. Experiments
of MMD retrieval will be conducted on the Wikipedia
dataset, which is organized as MMDs.
The compared methods of task 1) and 2) are as follows.
- BITR. Bilateral image-text retrieval [11].
- CCA. Canonical correlation analysis [12].
- CCA+SMN. Correlation match + Semantic match [1].
- CFA. Cross-modal factor analysis [13].
- CMCP. Cross modality correlation propagation [14].
- DCMIT. Deep correlation for matching images and text [10].
- HSNN. Heterogeneous similarity measure with nearest neighbors [15].
- JGRHML. Joint graph regularized heterogeneous metric learning [16].
- JRL. Joint representation learning [2].
- LGCFL. Local group based consistent feature learning [9].
- ml-CCA. Multi-label canonical correlation analysis [17].
- mv-CCA. Multi-view canonical correlation analysis [18].
- S2UPG. Semi-supervised cross-media feature learning algorithm with unified patch graph regularization [19].
The compared methods of task 3) are as follows.
- UCCG.
Uniform cross-media correlation graph
[20].
- MMDSG.
MMD semantic graph
[21].
- LRGA.
local regression and global alignment
[22].
We evaluate the retrieval results on Wikipedia, PKU XMedia, NUS-WIDE and Pascal VOC 2007 Datasets with the mean average precision (MAP) scores and precision-recall (PR) curves, which are widely used in information retrieval. Clickture dataset has
no category labels for evaluation with MAP and PR curves.
Instead, it consists of many text queries, and for each text
query there are multiple images along with the relevance
between images and query, which is uni-directional relevance
groundtruth. Following [6], [7], we conduct the text-based
image retrieval task for each text query, and take Discounted
Cumulative Gain for top 25 results (DCG@25) as evaluation
metric.
Because Clickture dataset has no category labels for supervised training,
so we conduct un-supervised methods (BITR, CCA, CFA,
DCMIT), while all the methods are conducted on the other
datasets Wikipedia, PKU XMedia, NUS-WIDE, and Pascal VOC.
Experimental results of these compared methods are reported in Table 1-Table 4 as below.
Click to show ↓
Table 1: The MAP scores of multi-modality cross-media retrieval
Table 2: The MAP scores of bi-modality cross-media retrieval
Table 3: The DCG@25 scores on Clickture dataset
| Dataset |
BITR |
CCA |
CFA |
DCMIT |
| Clickture |
0.474 |
0.484 |
0.486 |
0.492 |
Table 4: The MAP scores of cross-media MMD retrieval
| Dataset |
Task |
UCCG |
MMDSS |
LRGA |
| Wikipedia Dataset |
MMD->MMD |
0.316 |
0.441 |
0.596 |
Experimental results of these compared methods with other feature are reported in Table 5-Table 11 as below.
Click to show ↓
Table 5: The MAP scores of multi-modality cross-media retrieval with CNN image feature
Table 6: The MAP scores of bi-modality cross-media retrieval with CNN image feature
Table 7: The MAP scores of multi-modality cross-media retrieval with BOW text feature
Table 8: The MAP scores of bi-modality cross-media retrieval with BOW text feature
Table 9: The MAP scores of multi-modality cross-media retrieval with CNN video feature
Table 10: The MAP scores of bi-modality cross-media retrieval with CNN video feature
Table 11: The DCG@25 scores on Clickture dataset with different feature
| Dataset |
Image |
Text |
BITR |
CCA |
CFA |
| Clickture |
BoVW |
LDA |
0.474 |
0.486 |
0.486 |
| BoVW |
BoW |
0.471 |
0.489 |
0.483 |
| CNN |
LDA |
0.485 |
0.492 |
0.479 |
| CNN |
BoW |
0.489 |
0.497 |
0.473 |
PR curves of these compared methods are reported as below.
Click to show ↓
( The data of PR curves can be downloaded in Download Section. )
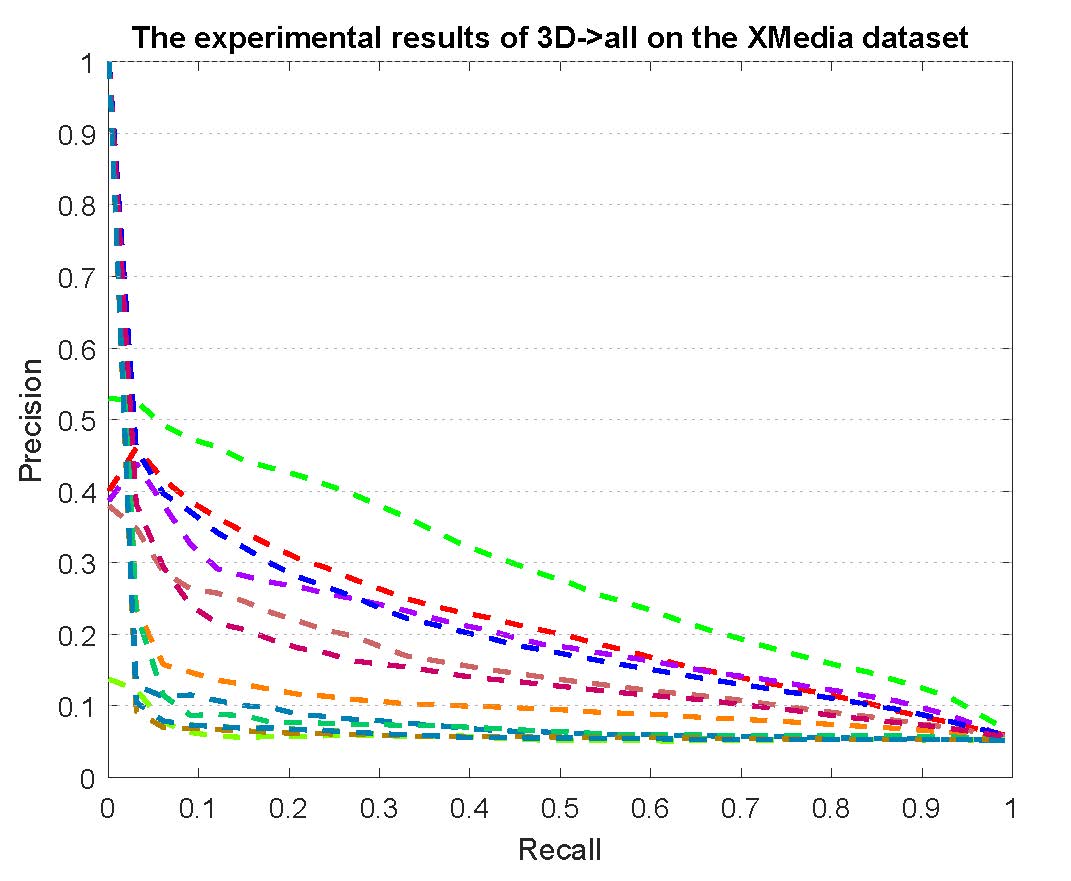
PR curves of multi-modality cross-media retrieval on the PKU XMedia dataset are reported as below.
Figure 1: The experimental results of multi-modality cross-media retrieval on the PKU XMedia dataset.
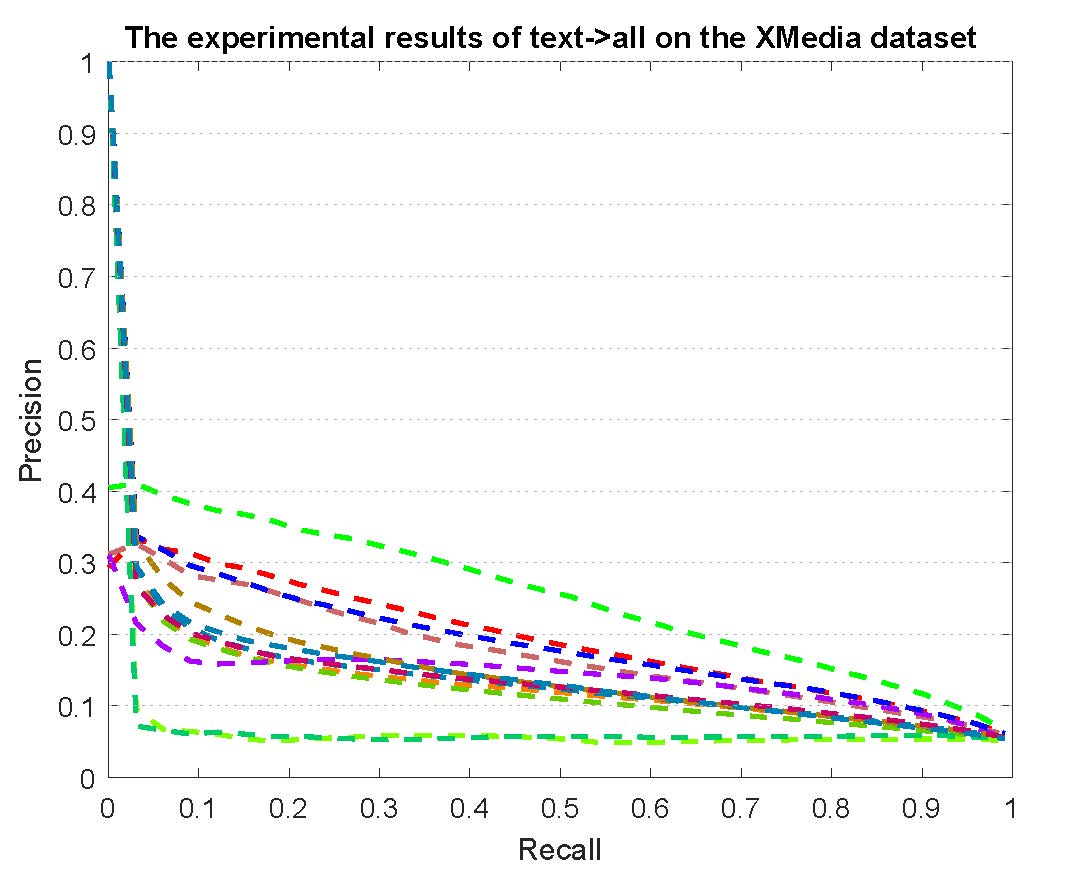
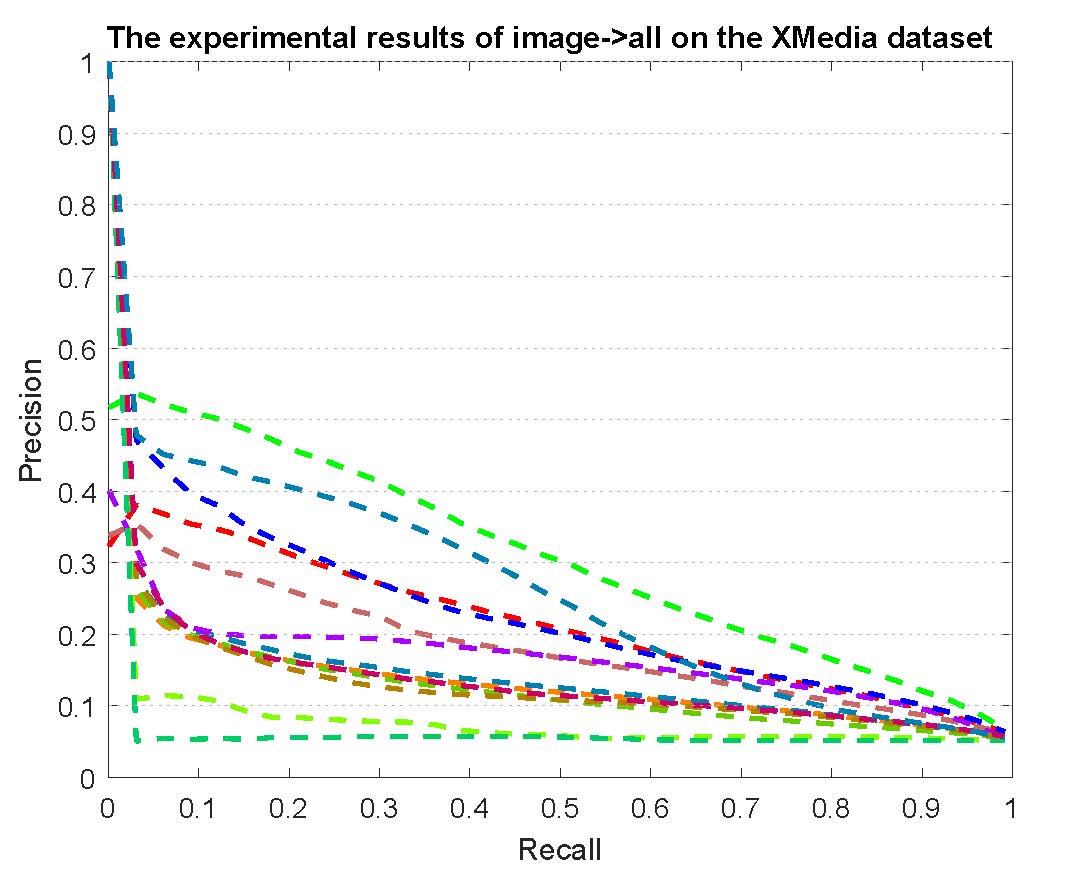
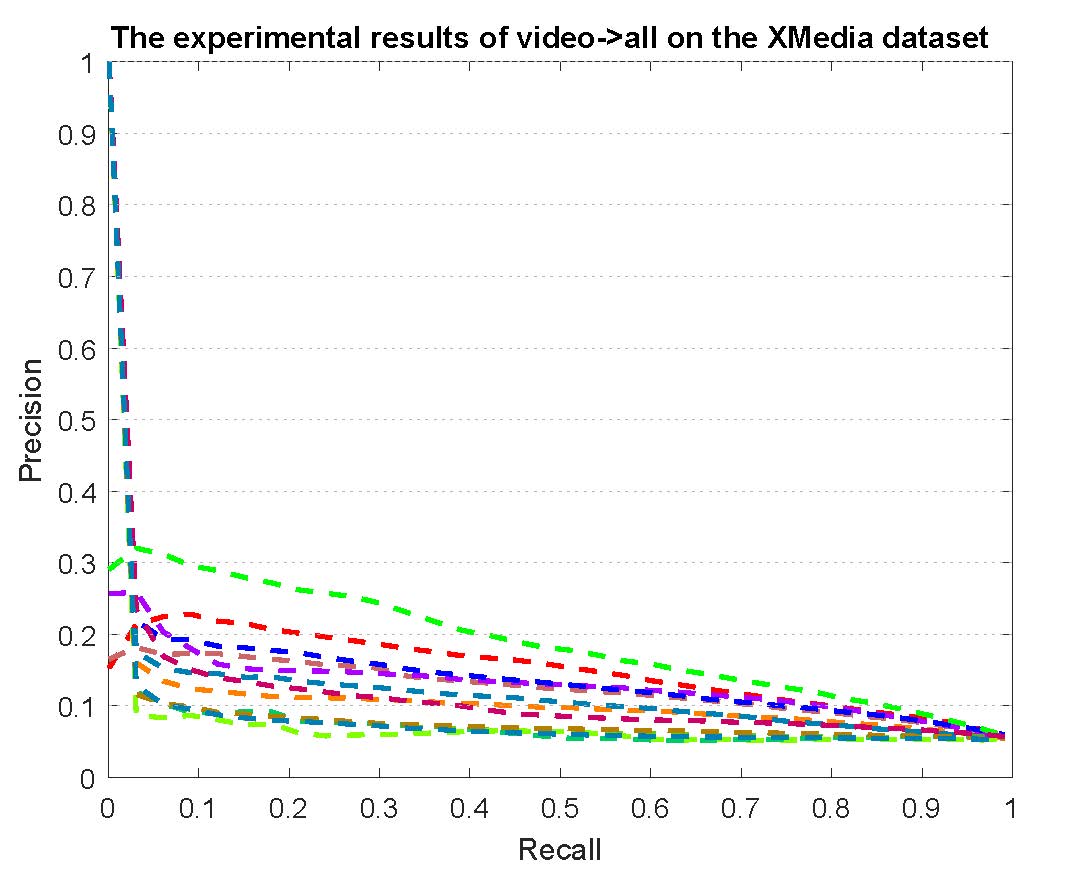
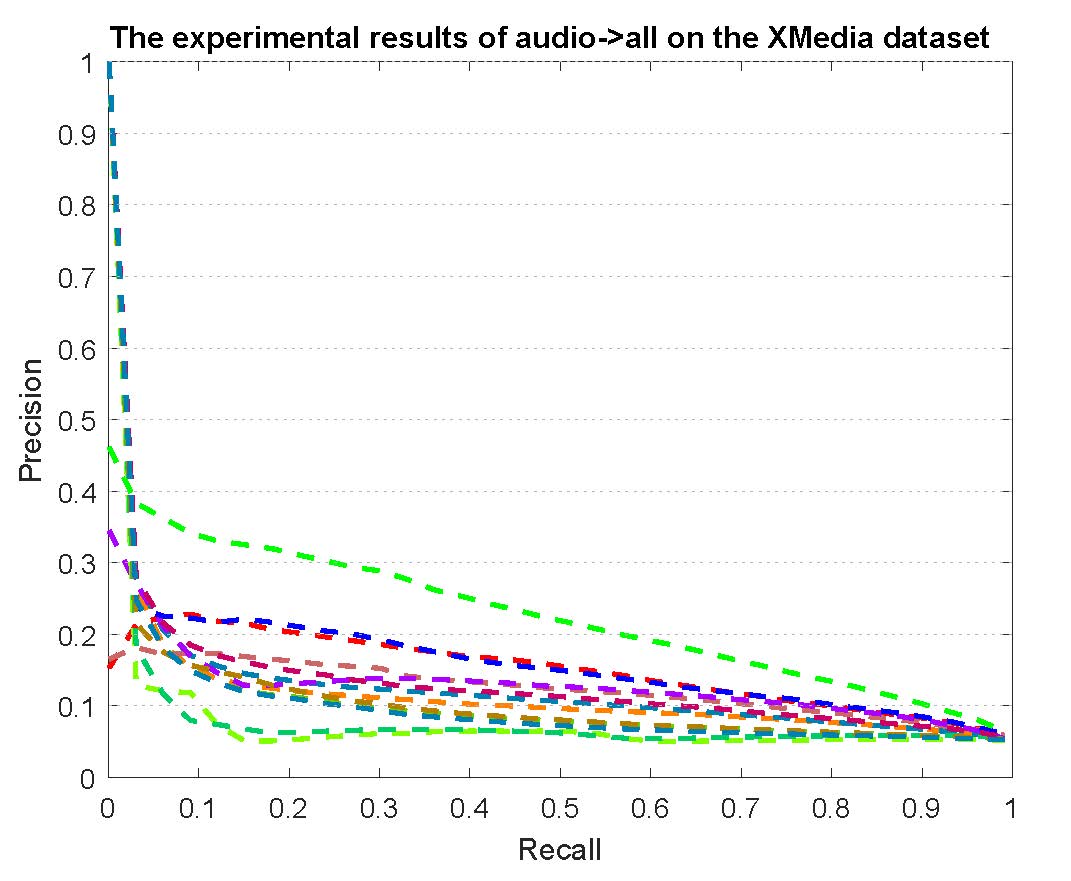
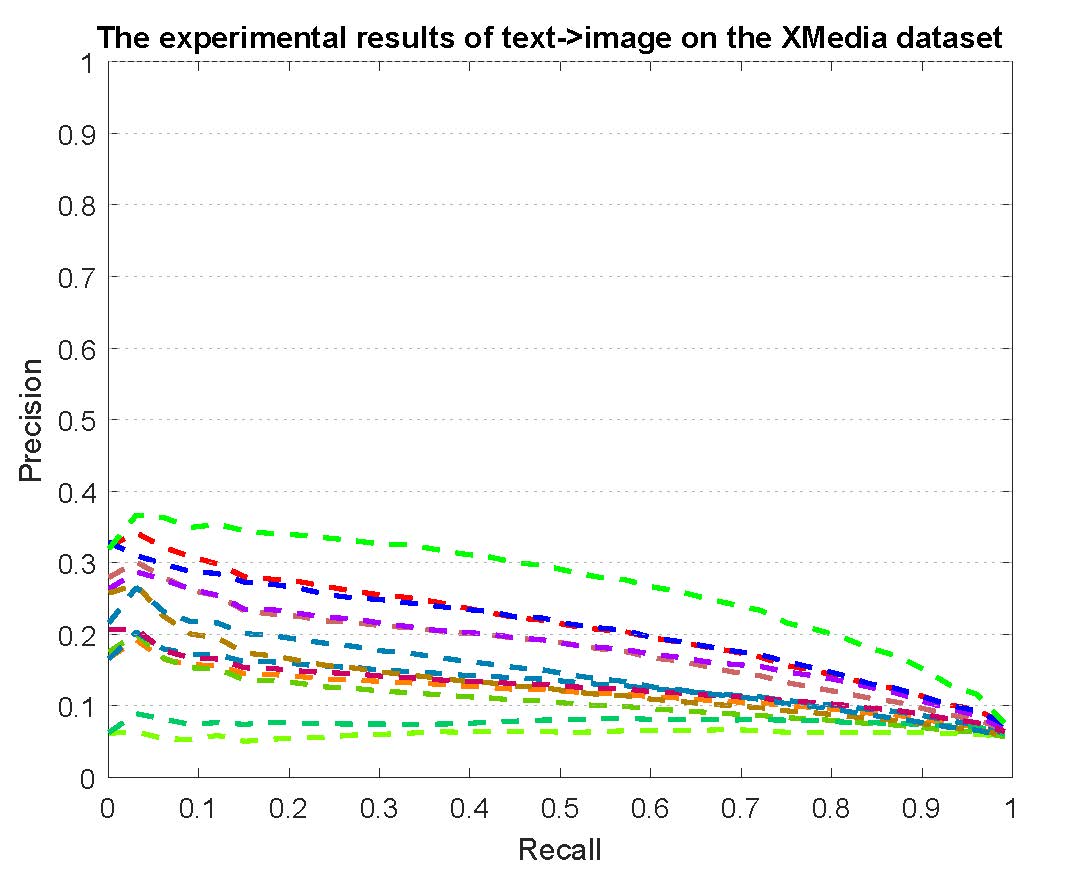
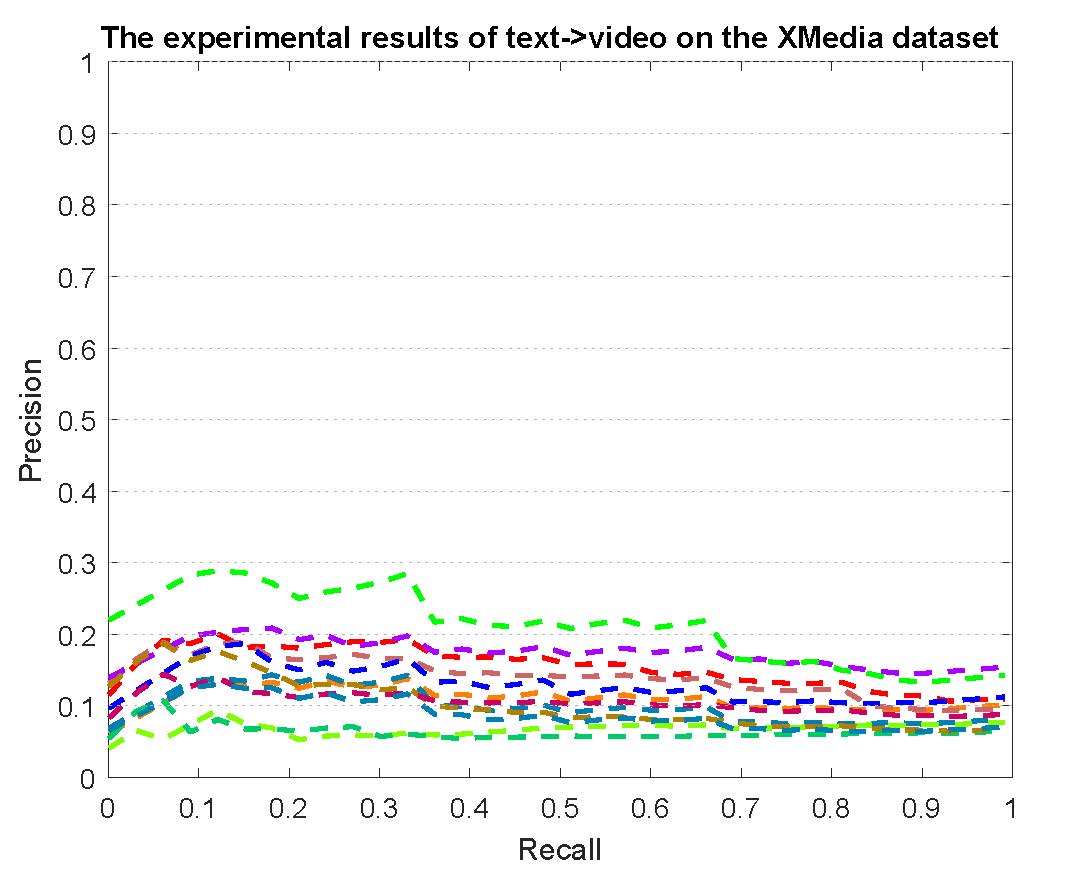
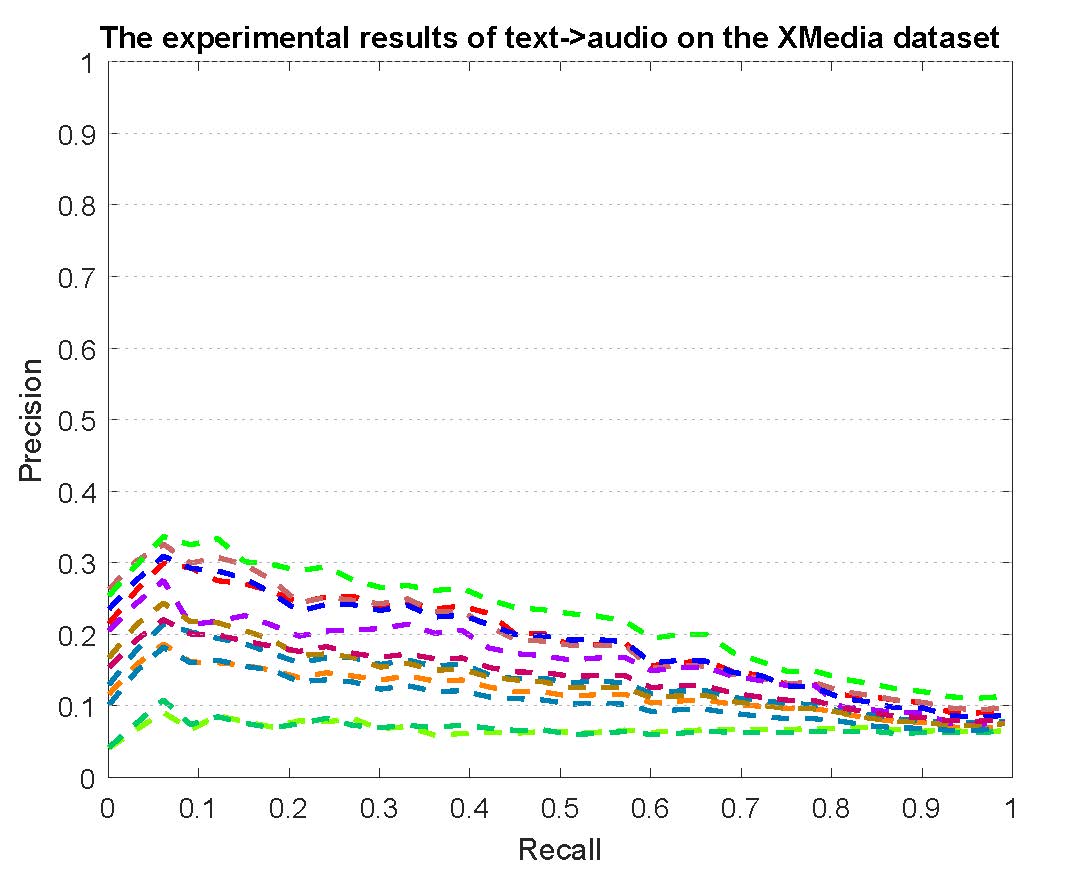
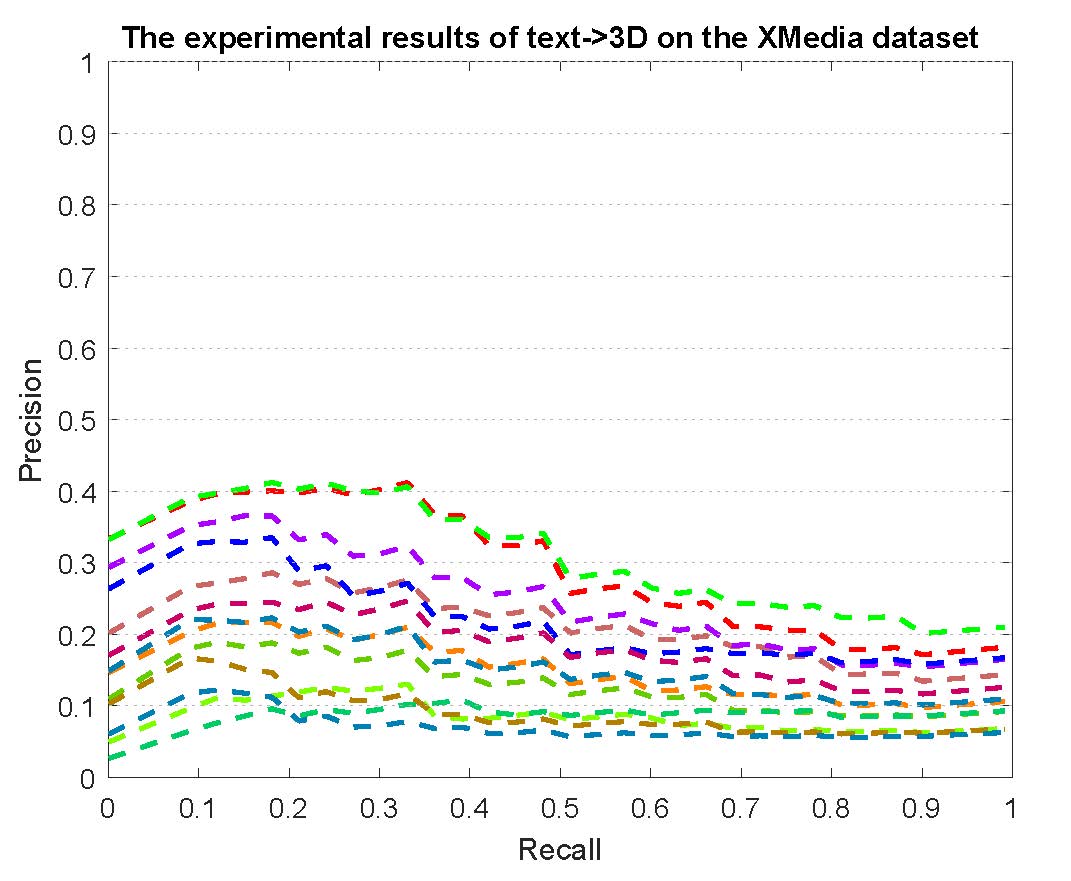
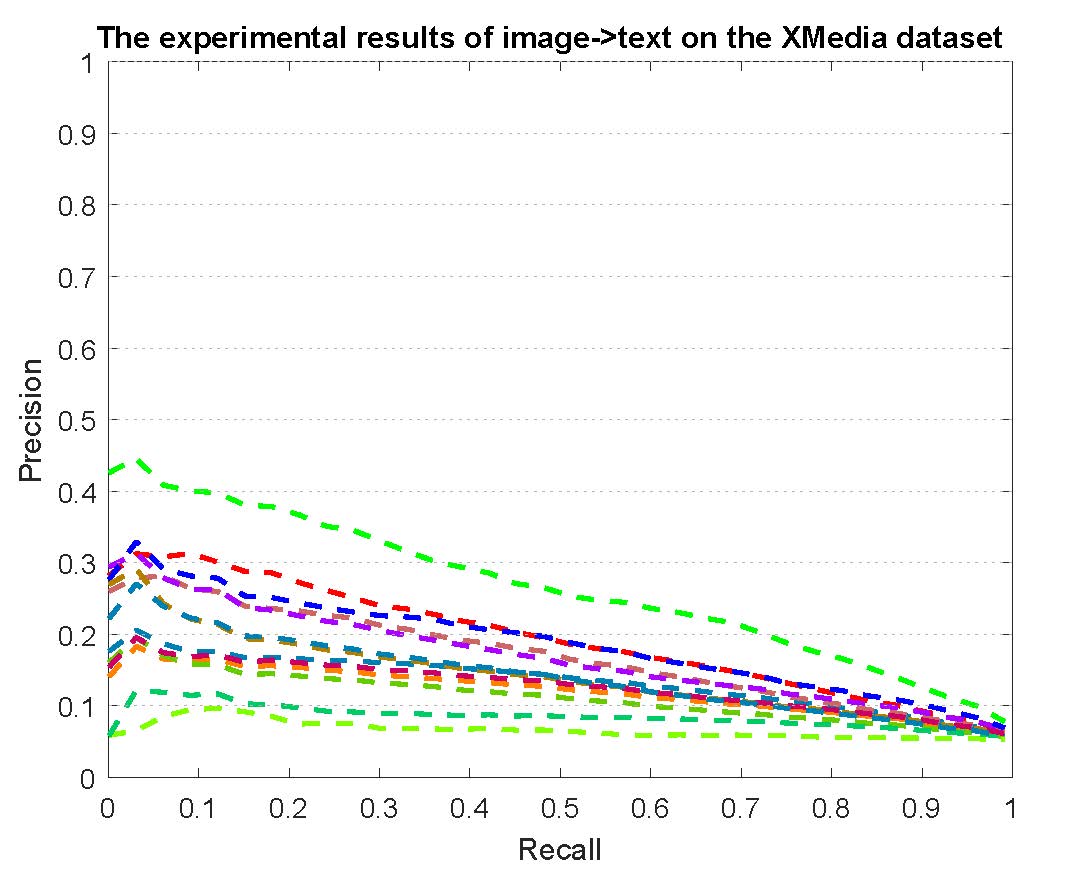
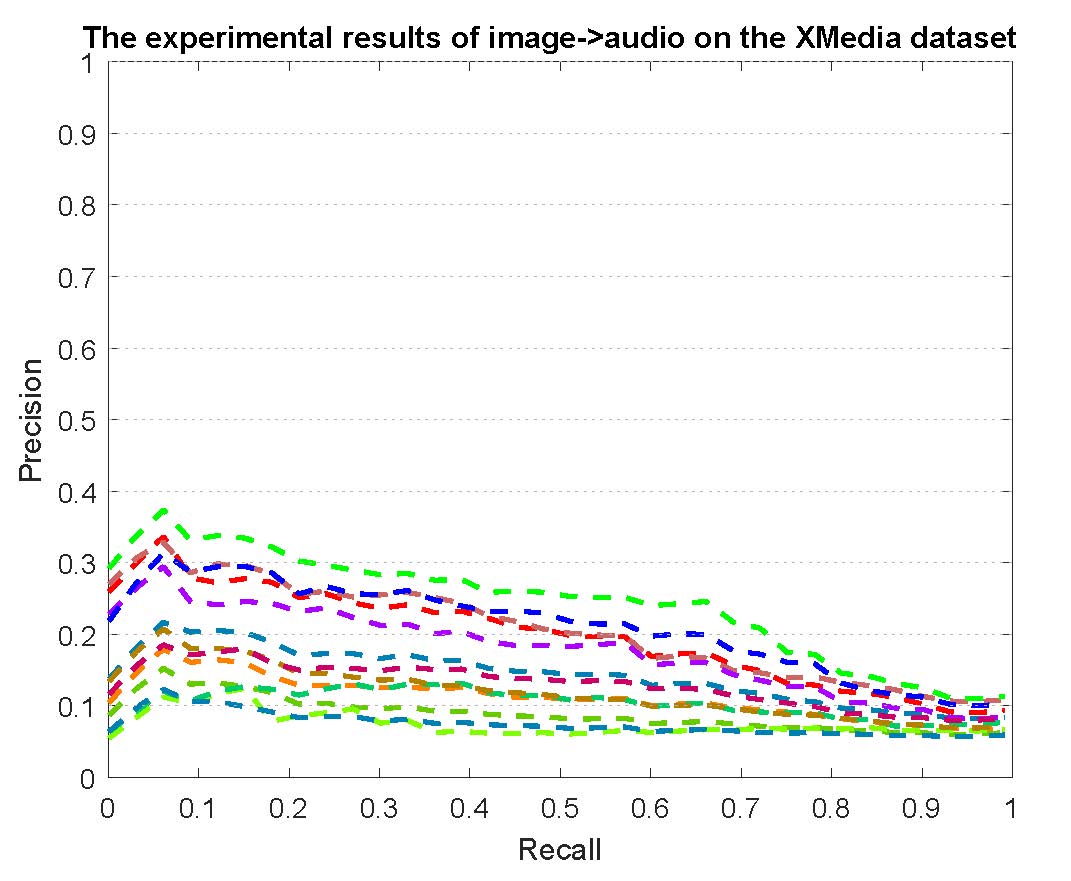
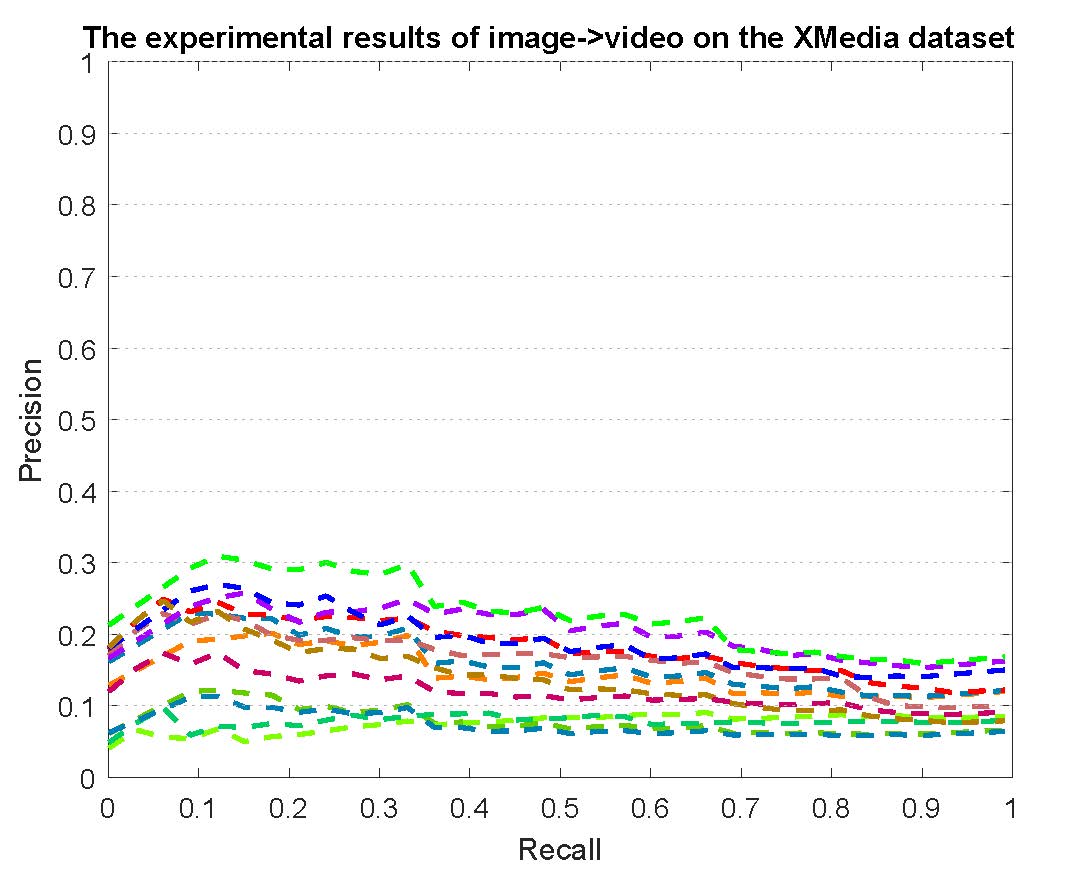
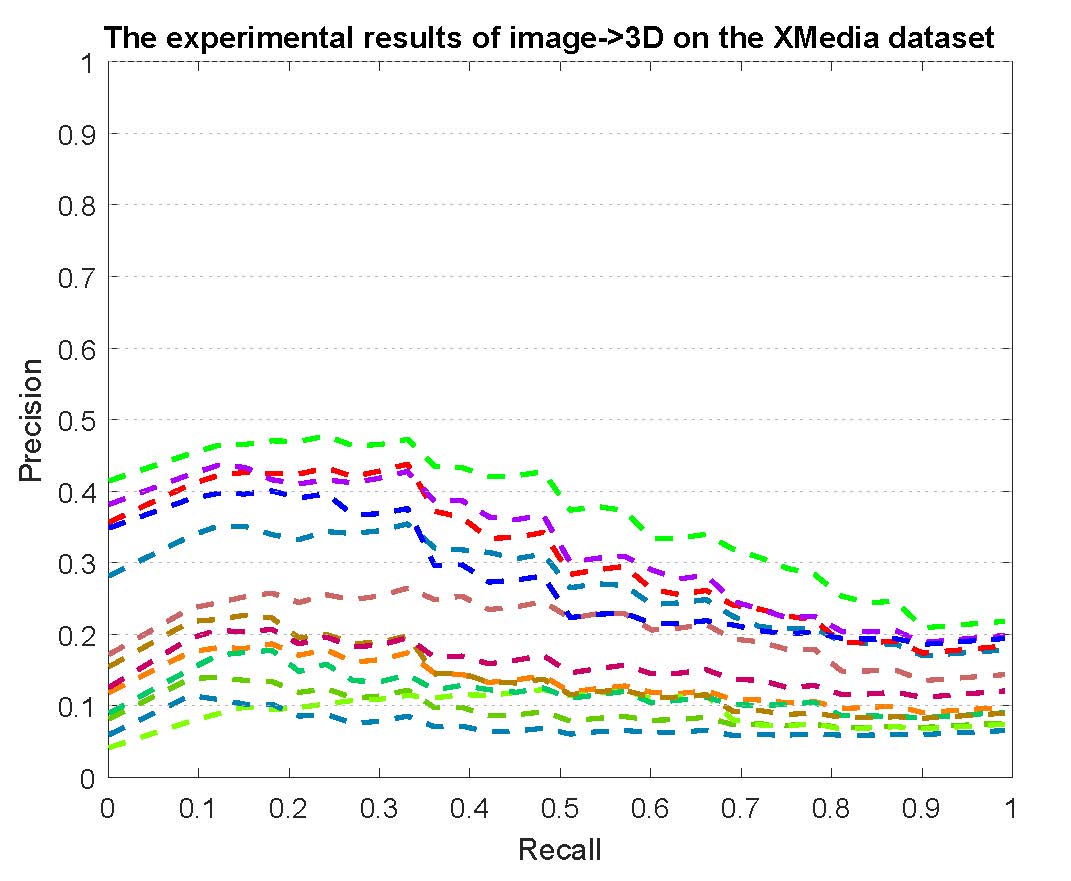
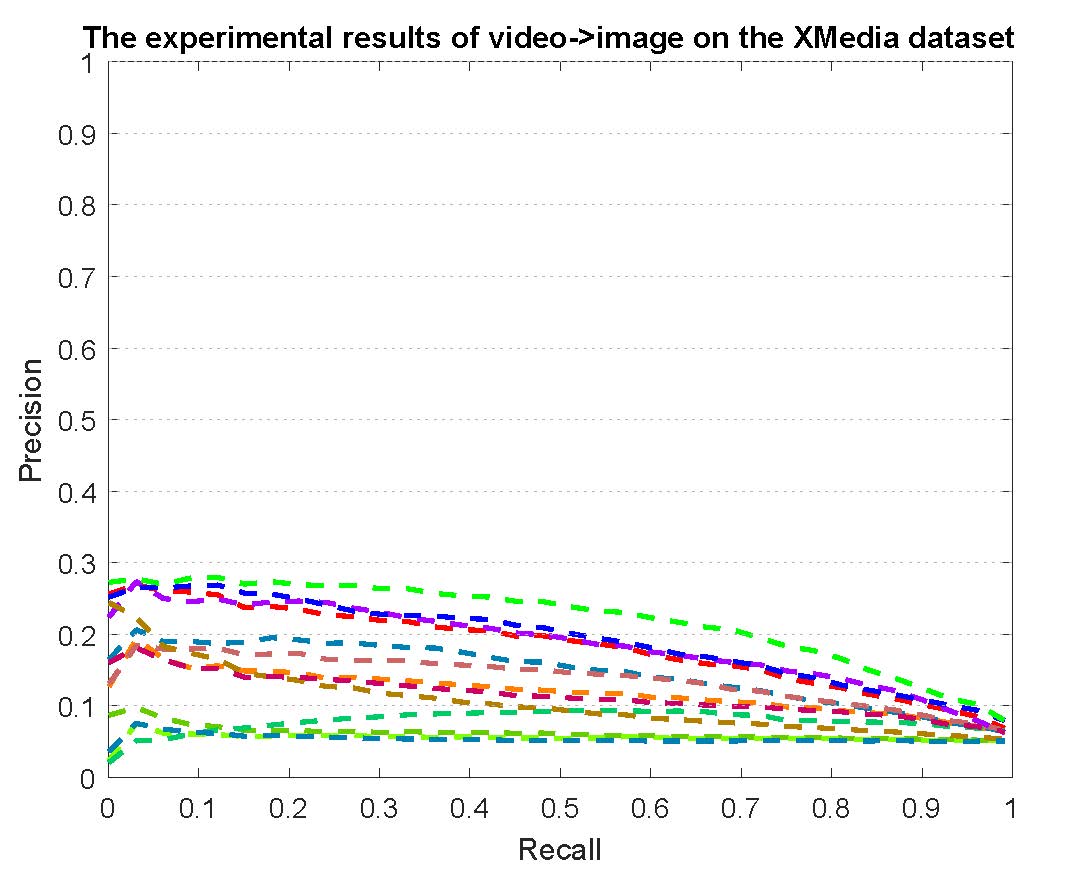
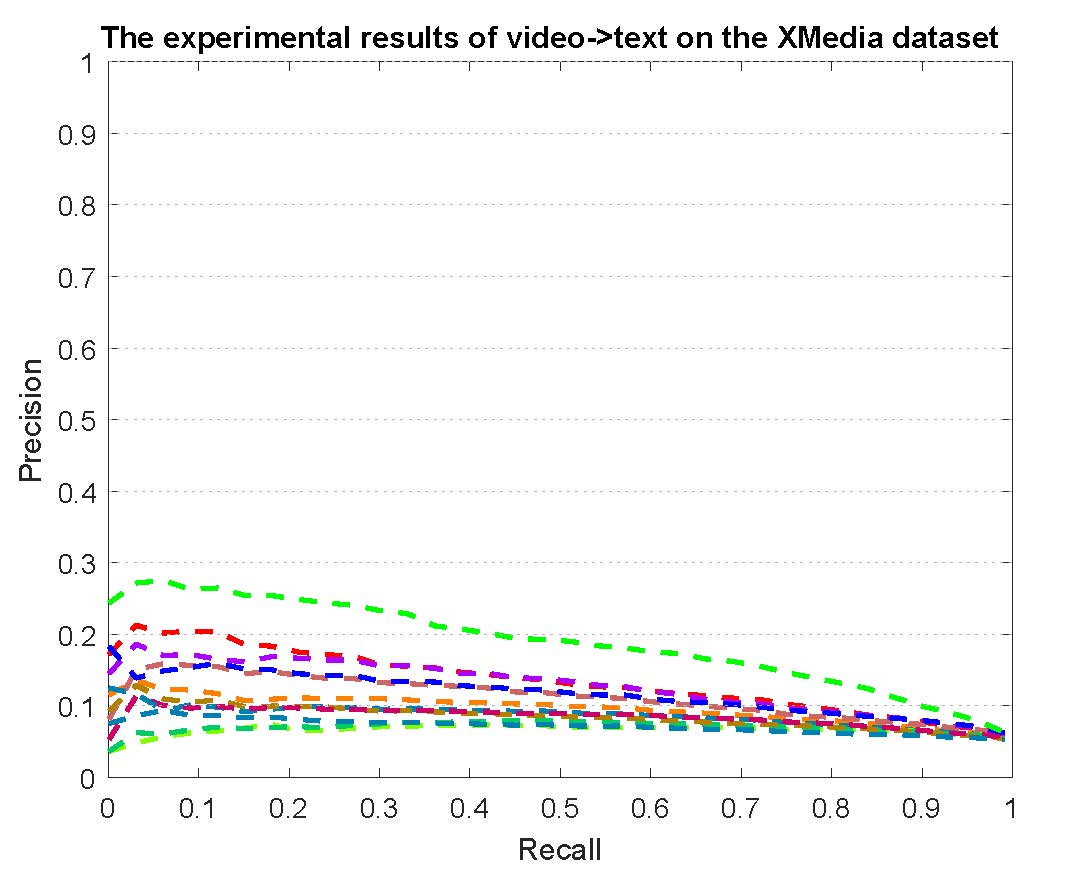
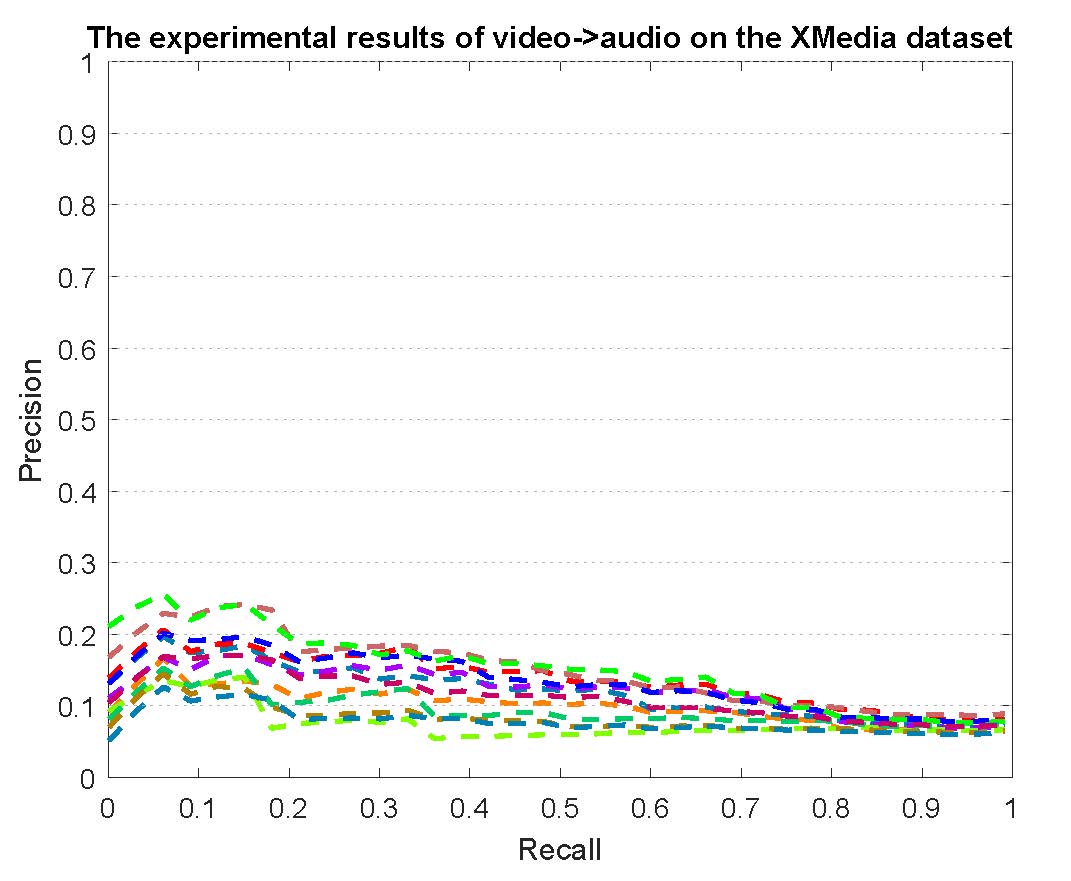
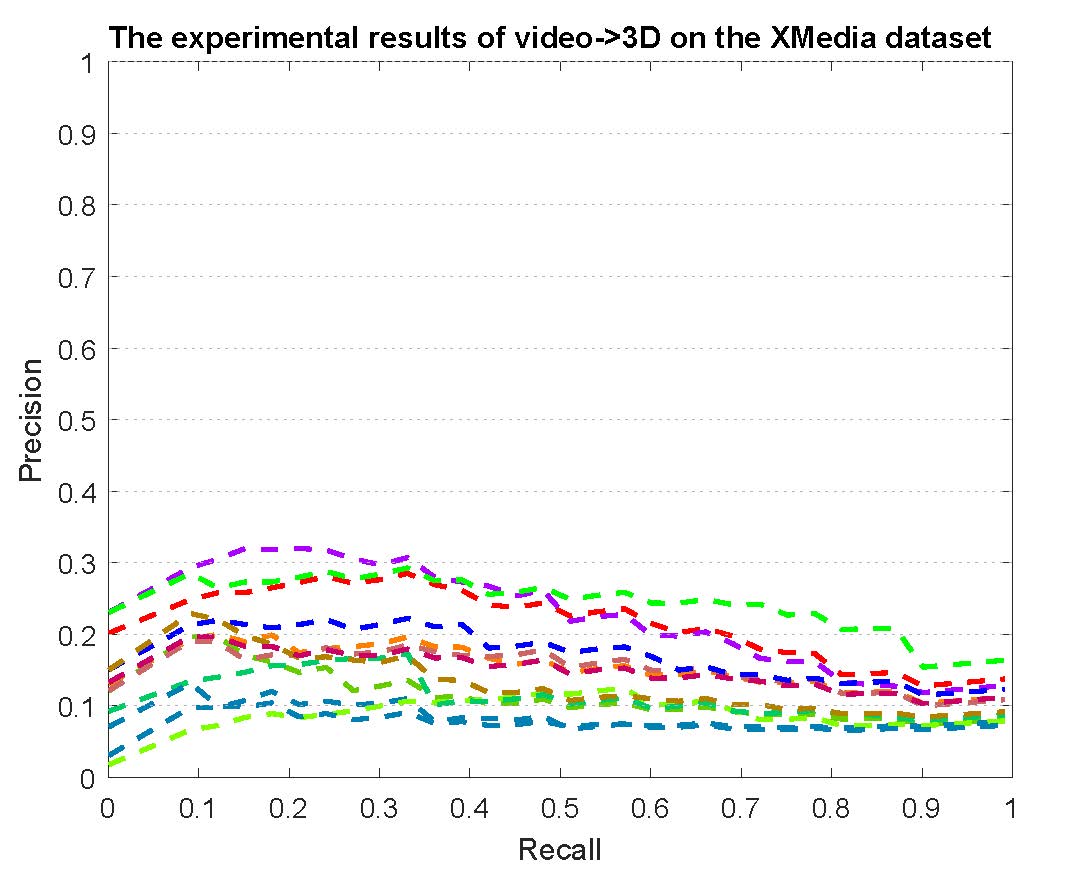
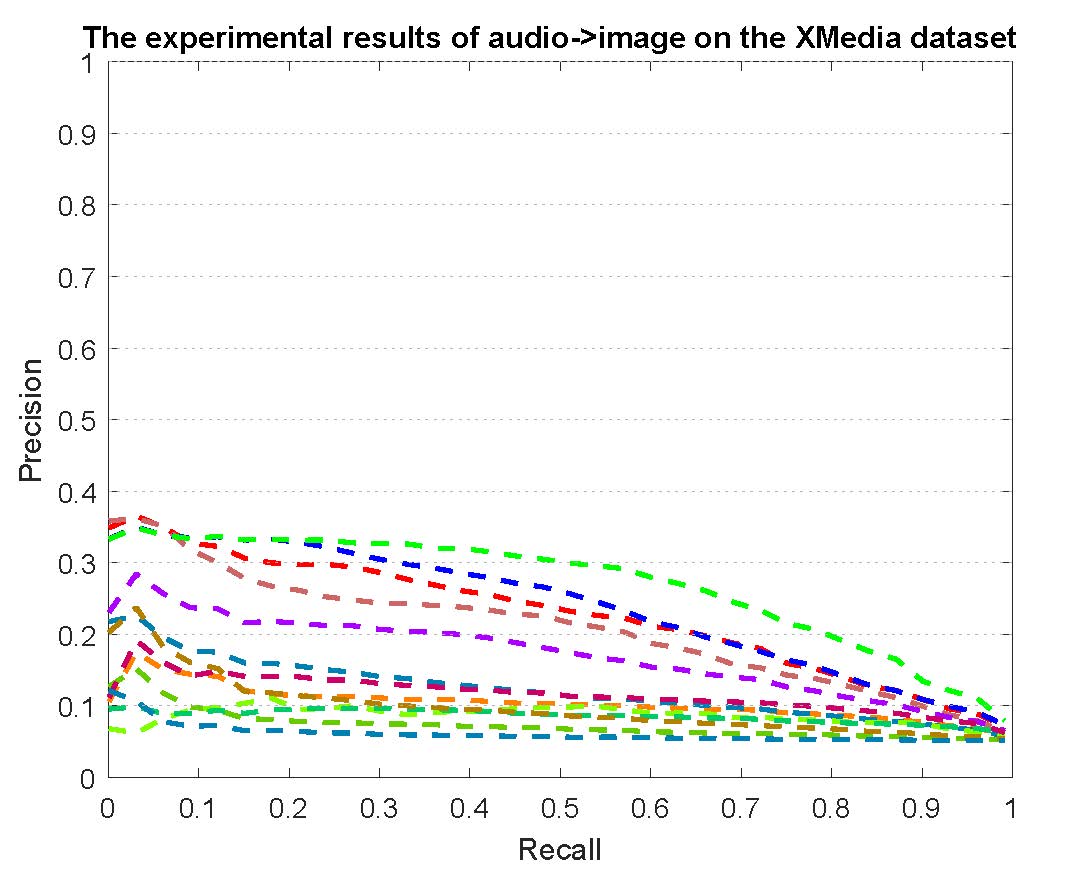
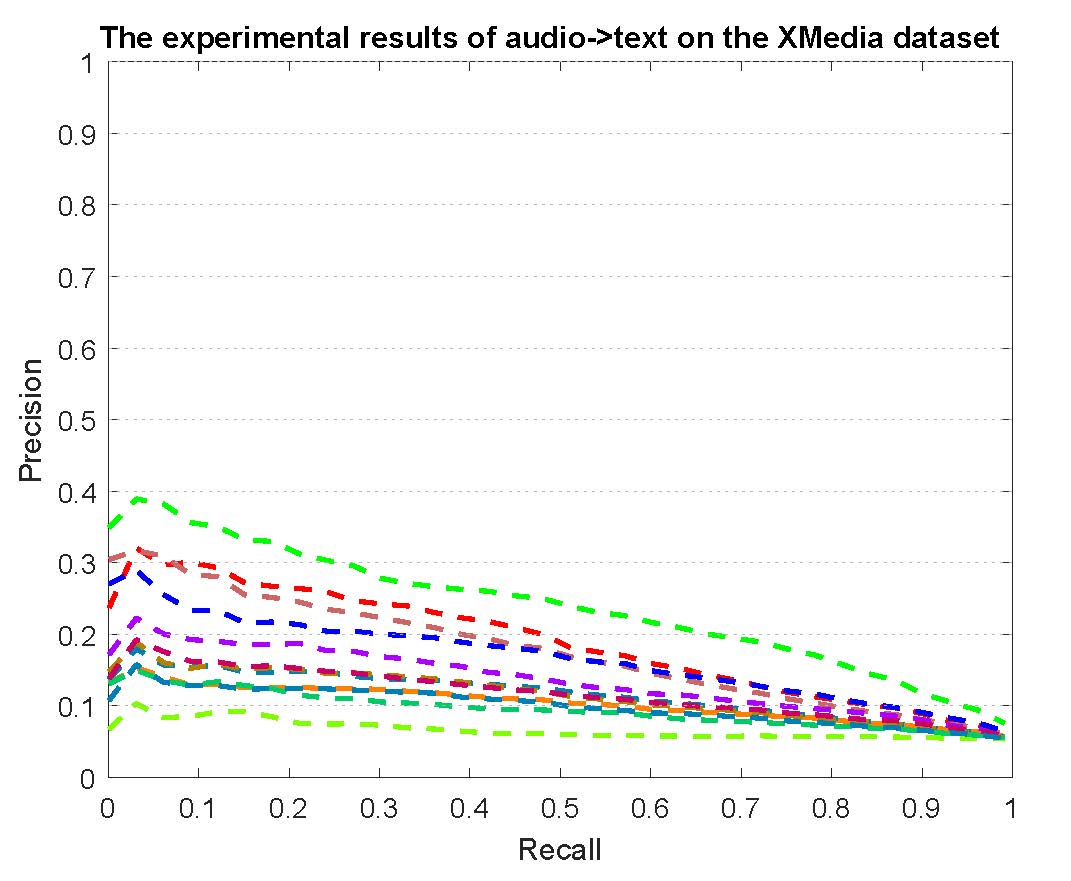
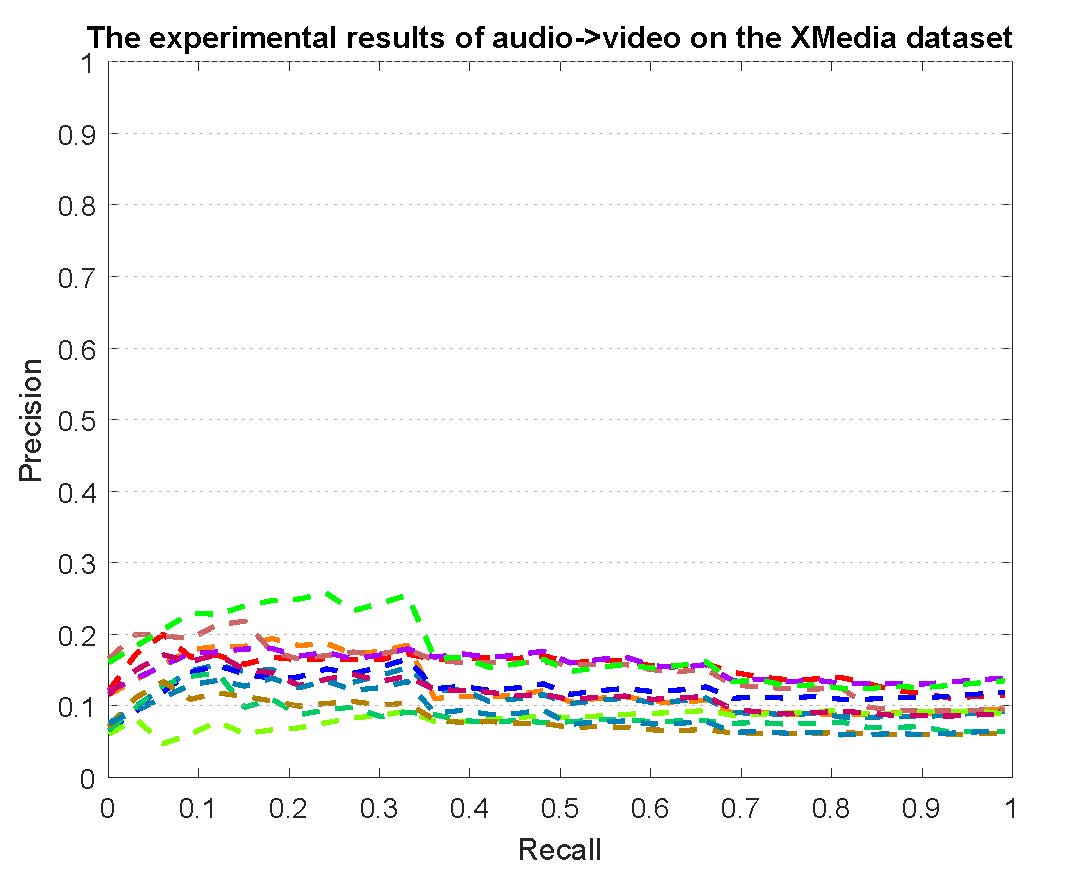
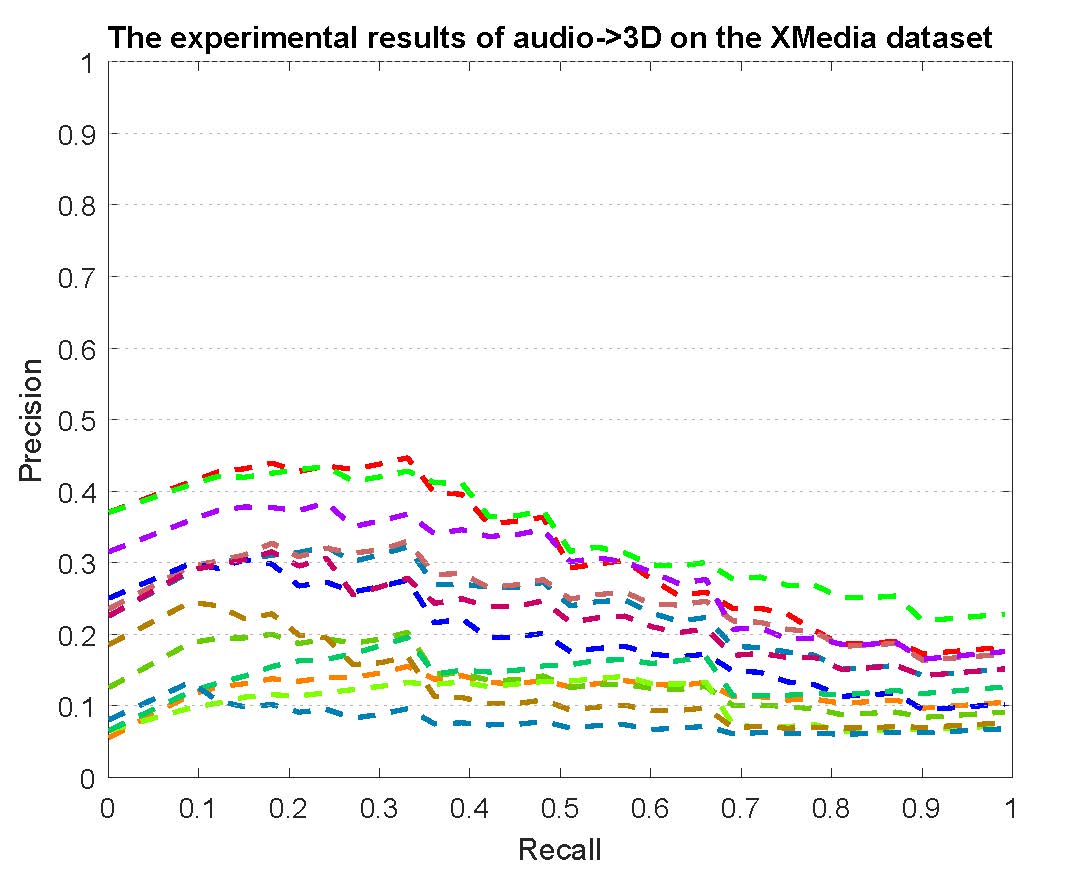
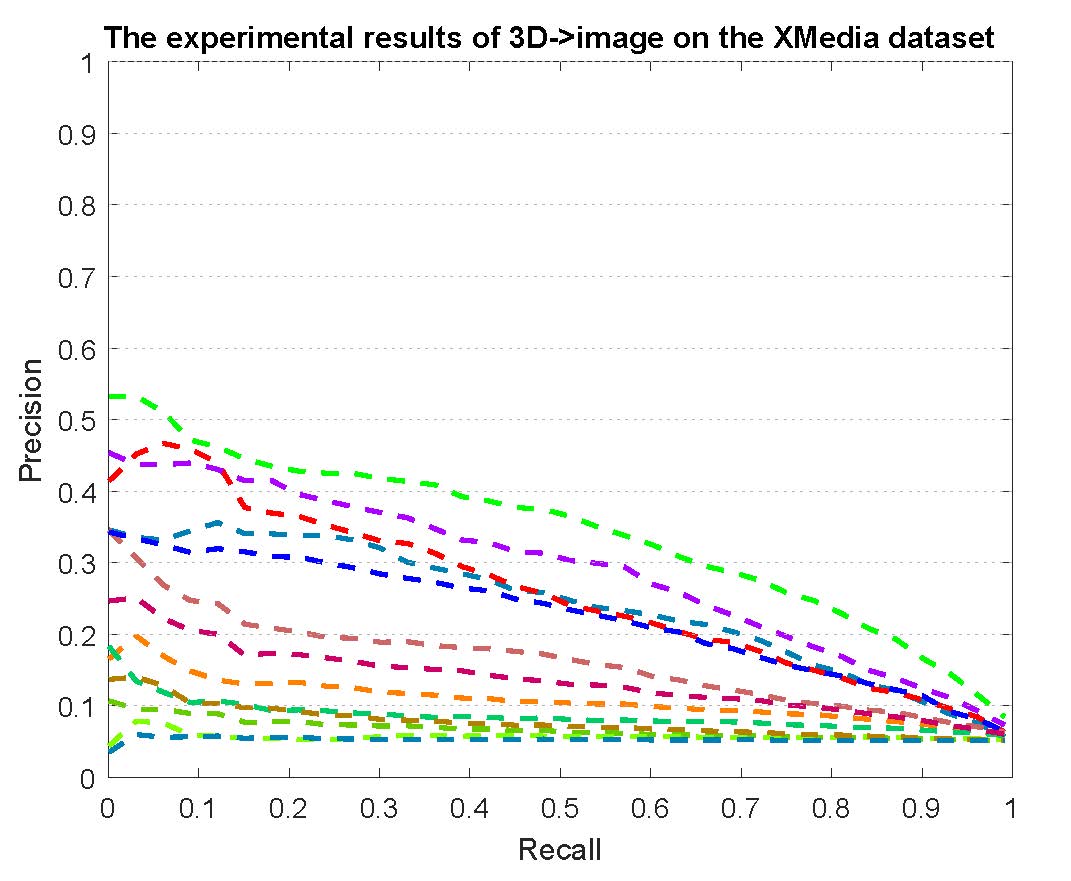
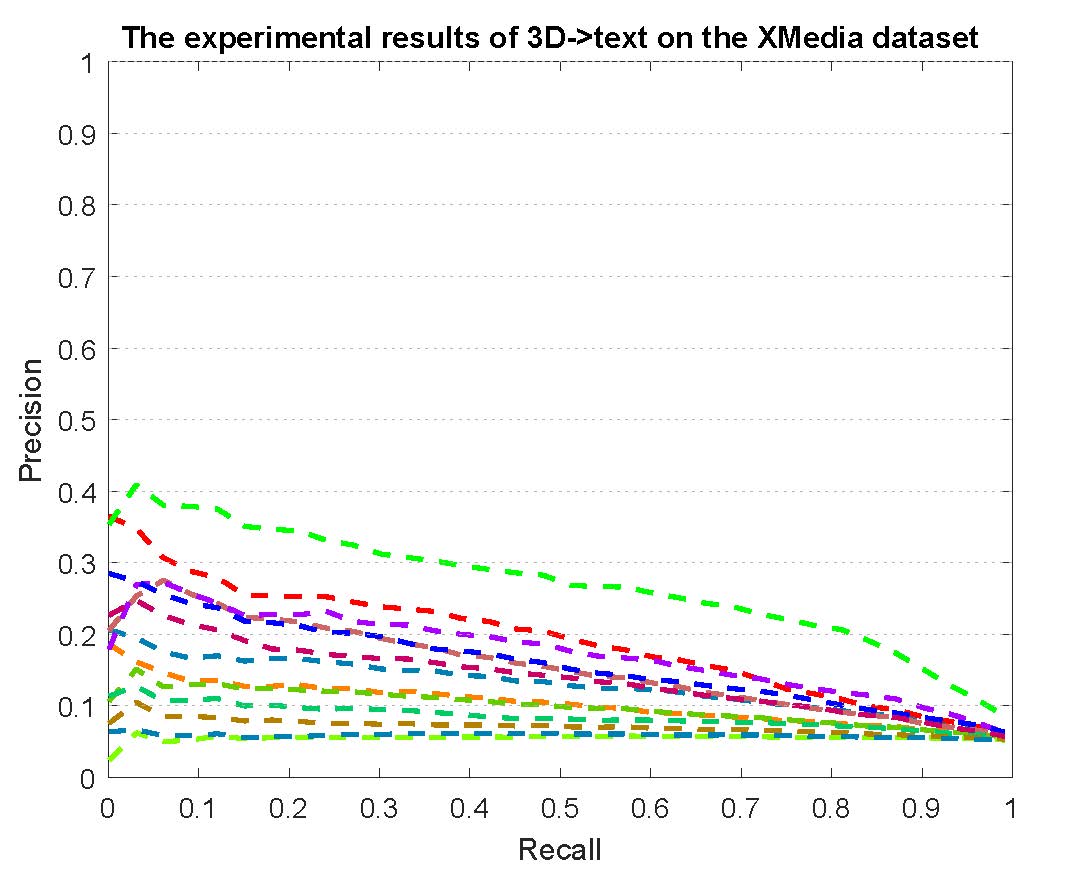
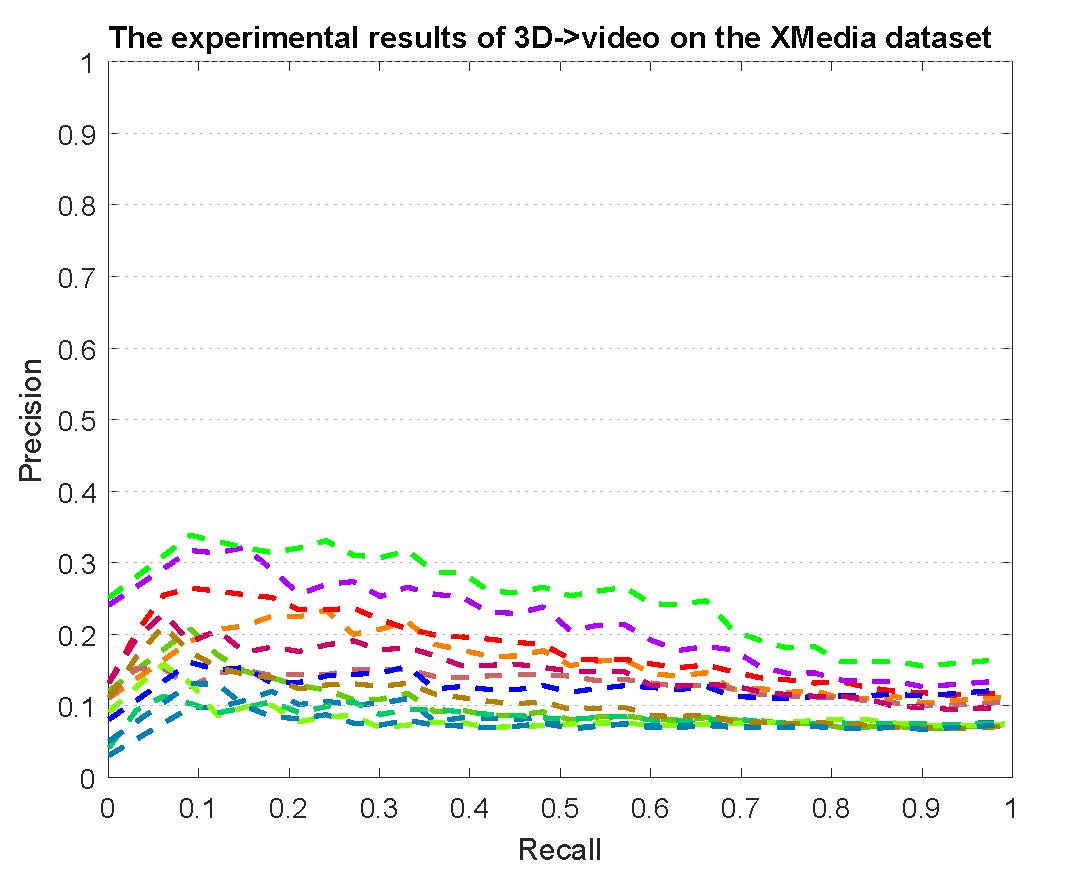
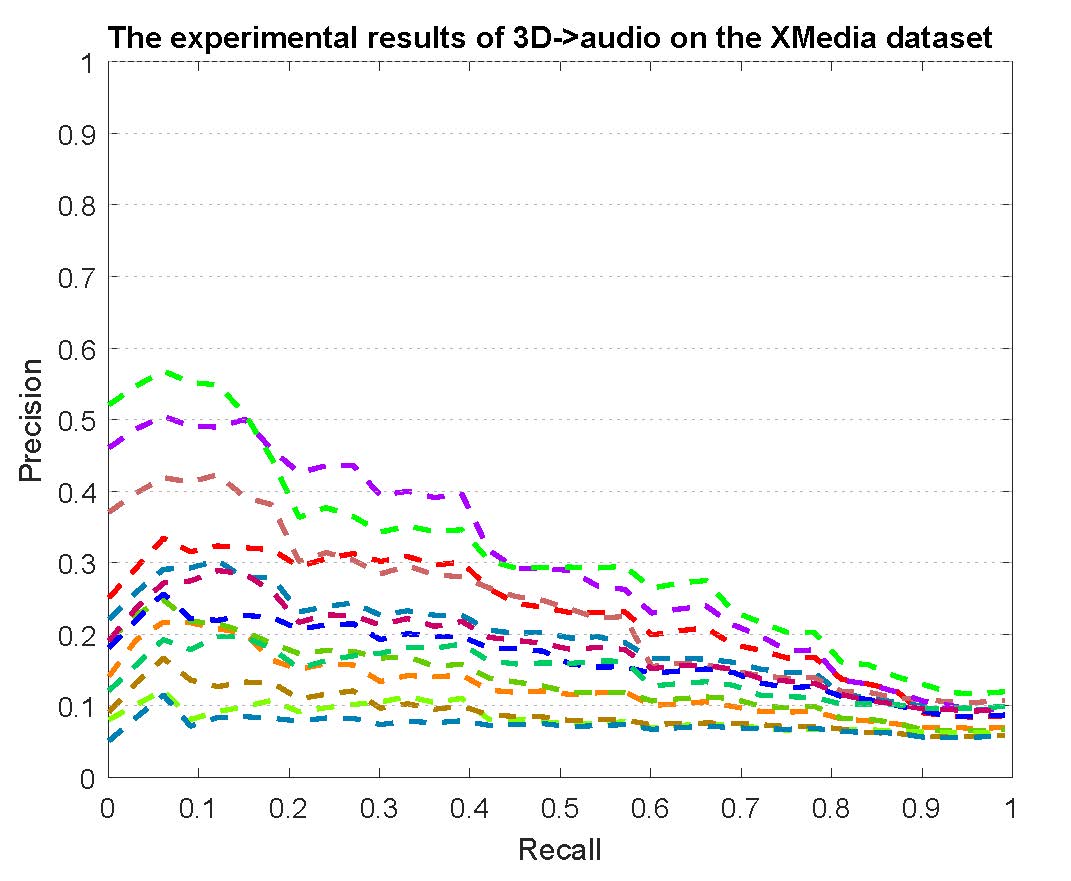
PR curves of bi-modality cross-media retrieval on the PKU XMedia dataset are reported as below.
Figure 2: The experimental results of bi-modality cross-media retrieval on the PKU XMedia dataset.
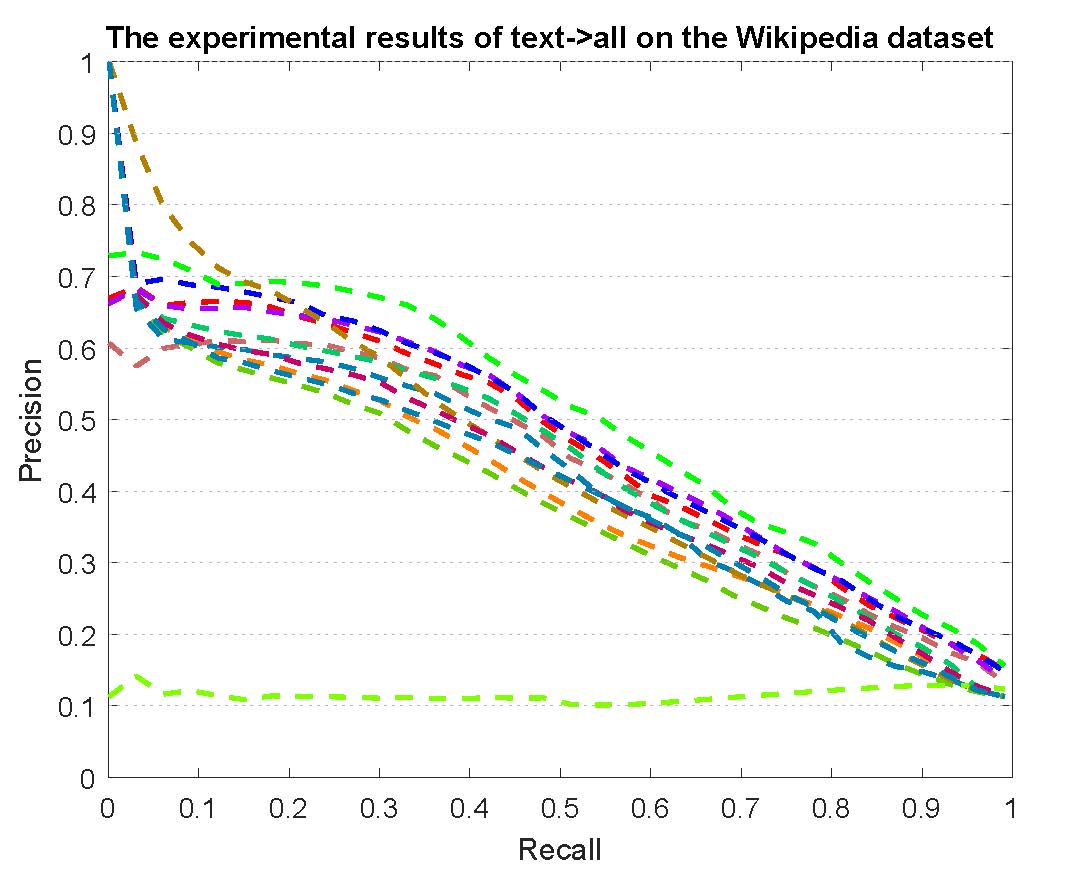
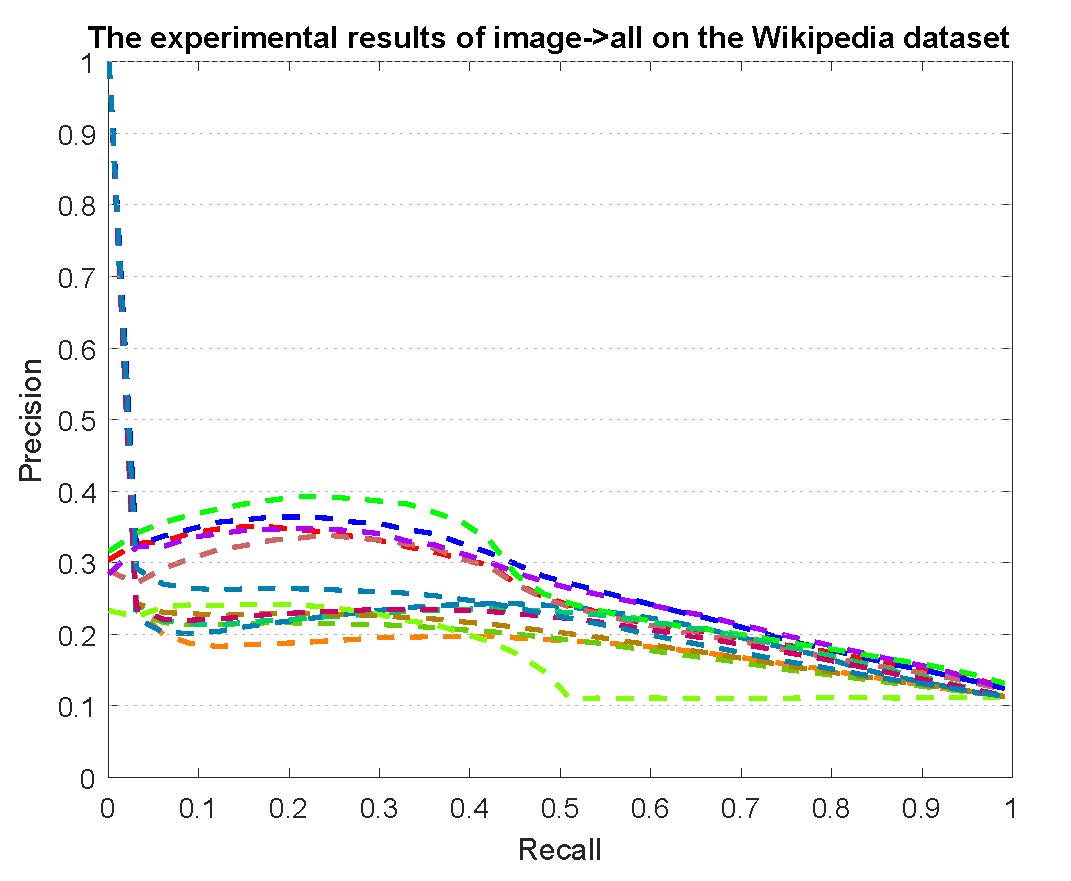
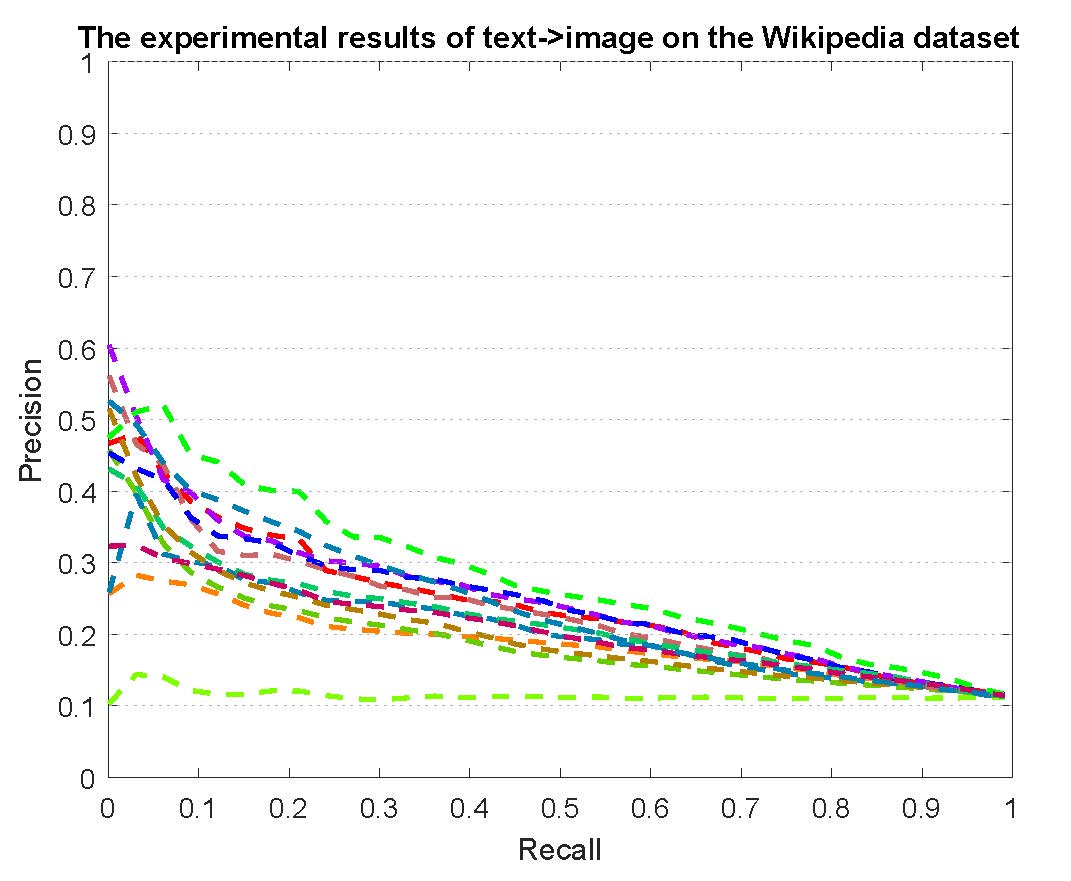
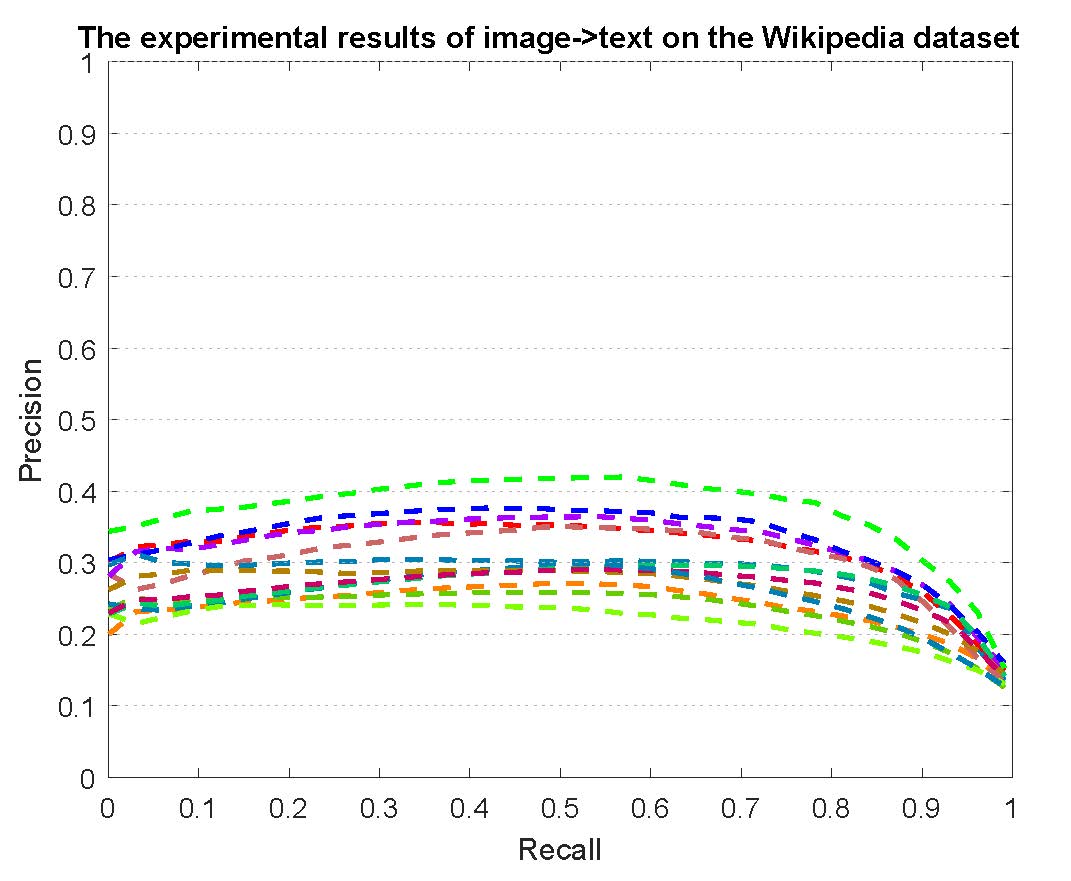
PR curves of retrieval on the Wikipedia dataset are reported as below.
Figure 3: The experimental results of multi-modality cross-media retrieval and bi-modality cross-media retrieval on the Wikipedia dataset.
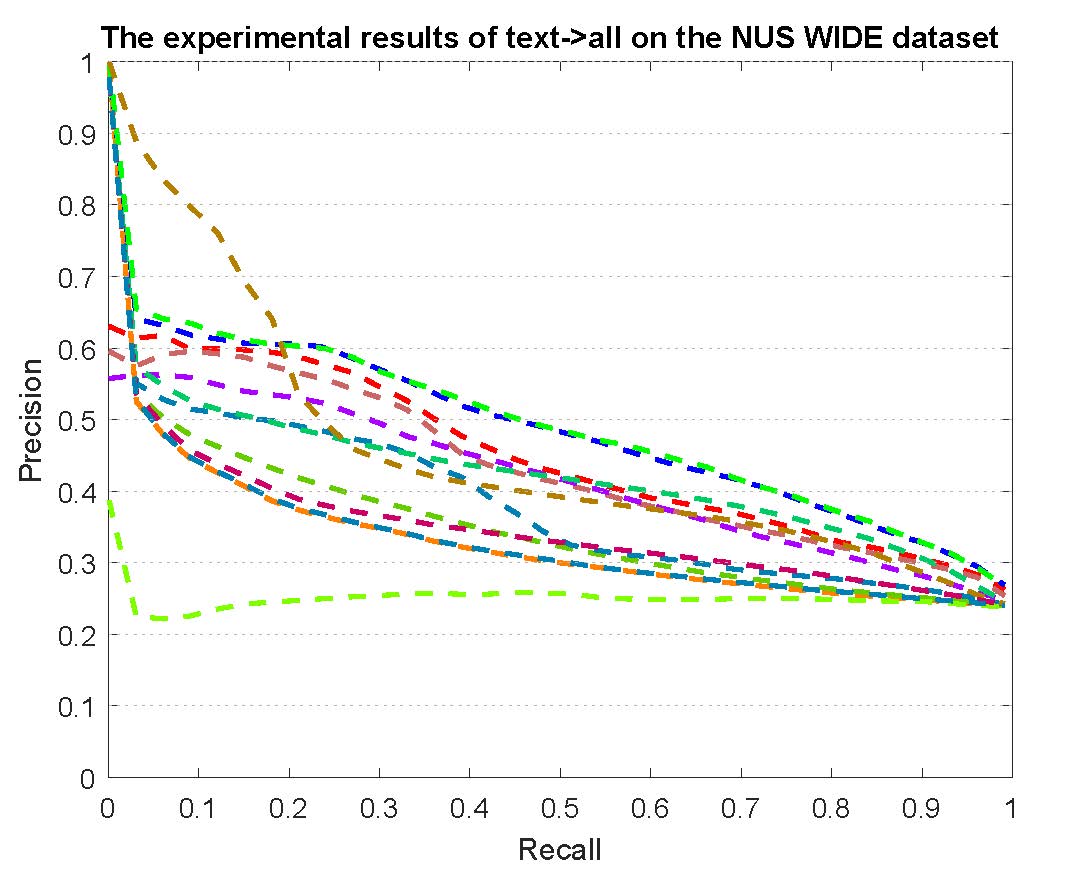
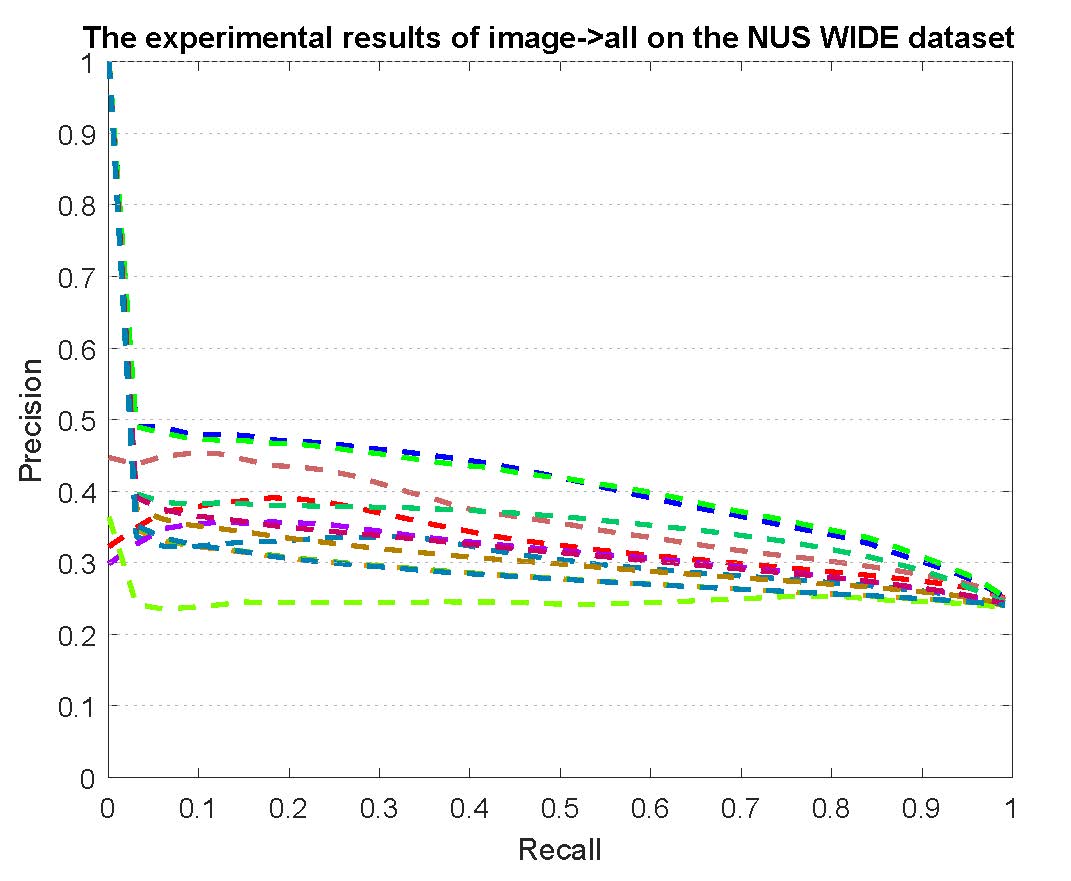
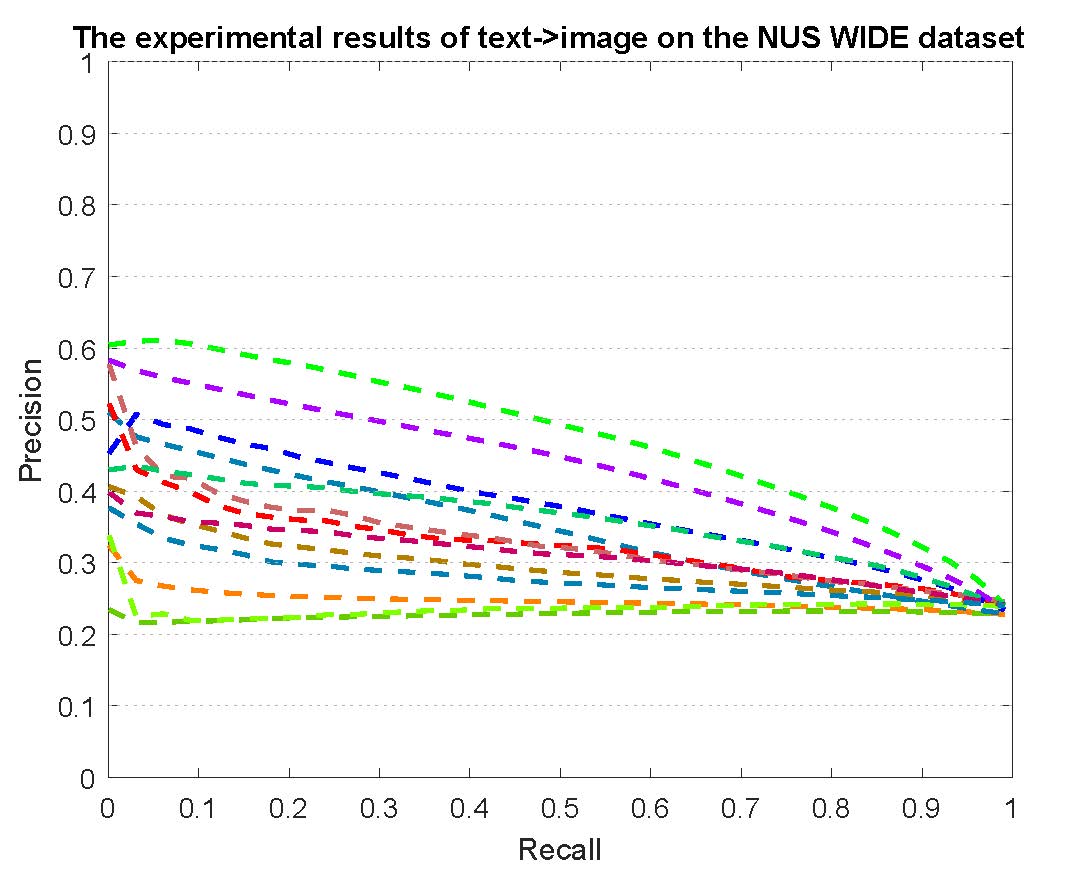
PR curves of retrieval on the NUS-WIDE dataset are reported as below.
Figure 4: The experimental results of multi-modality cross-media retrieval and bi-modality cross-media retrieval on the NUS-WIDE dataset.
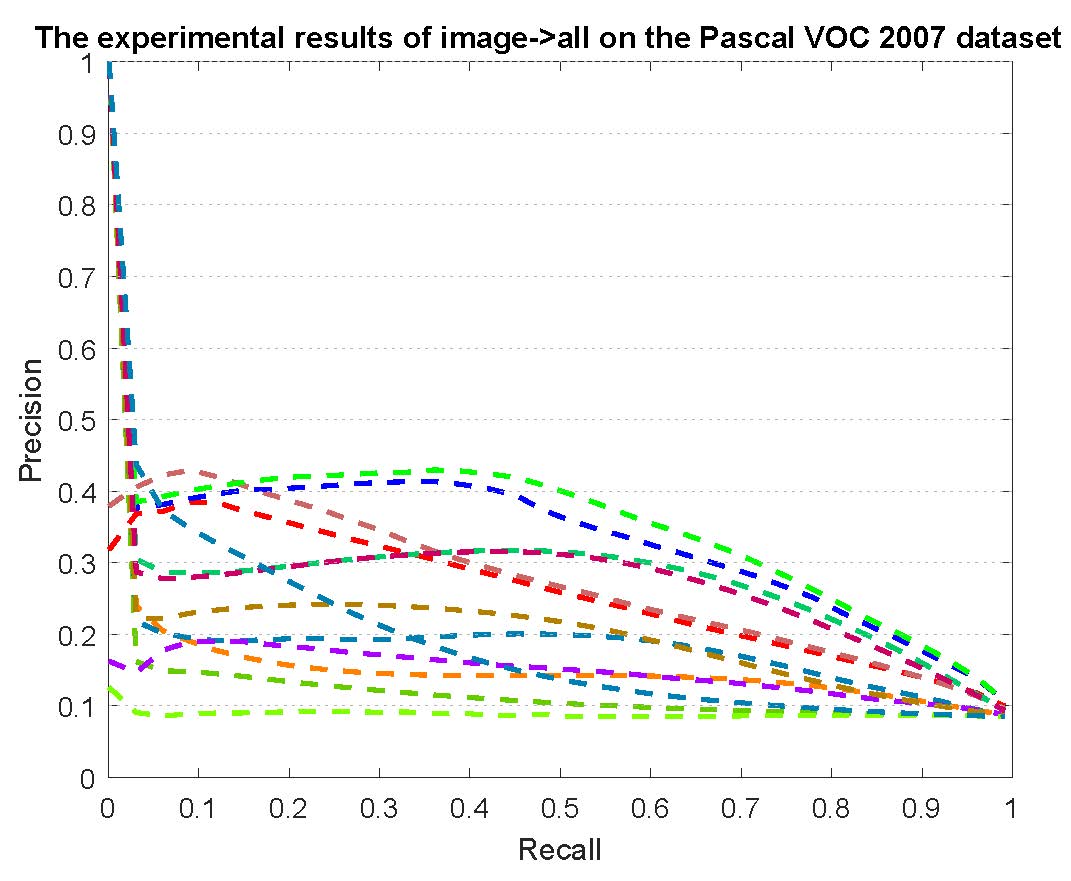
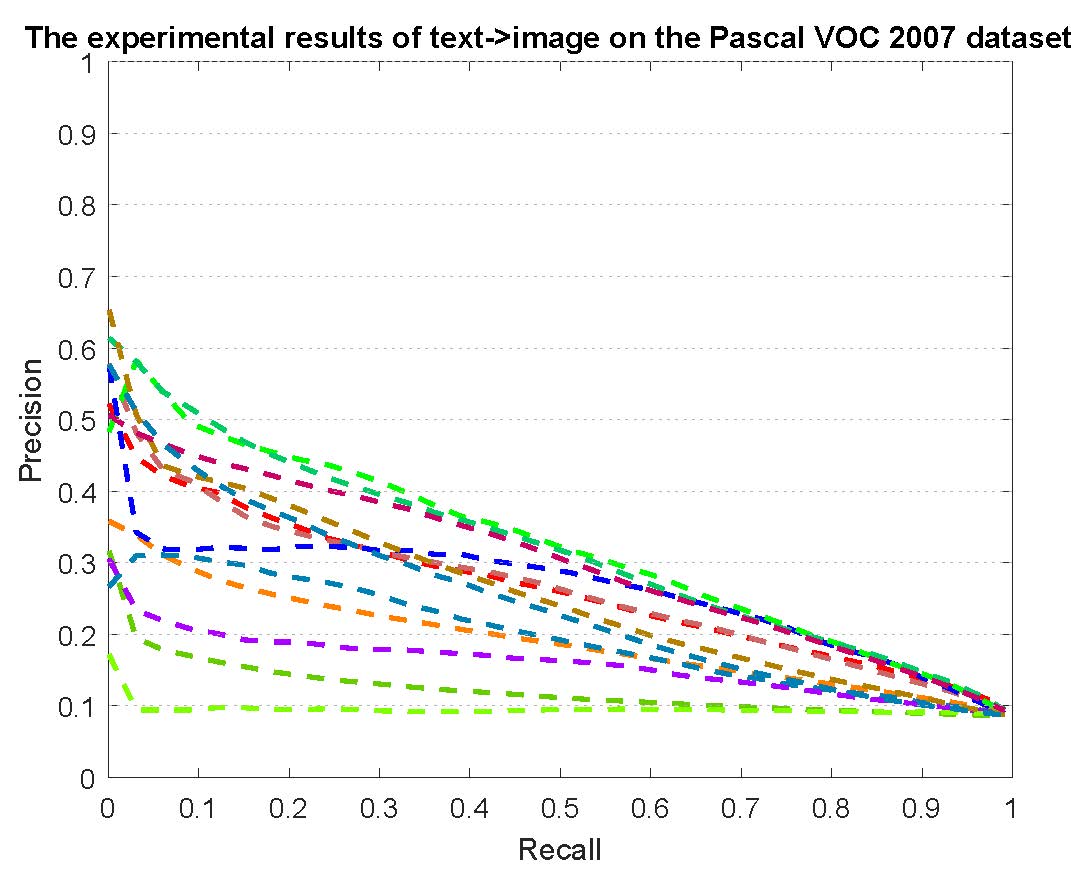
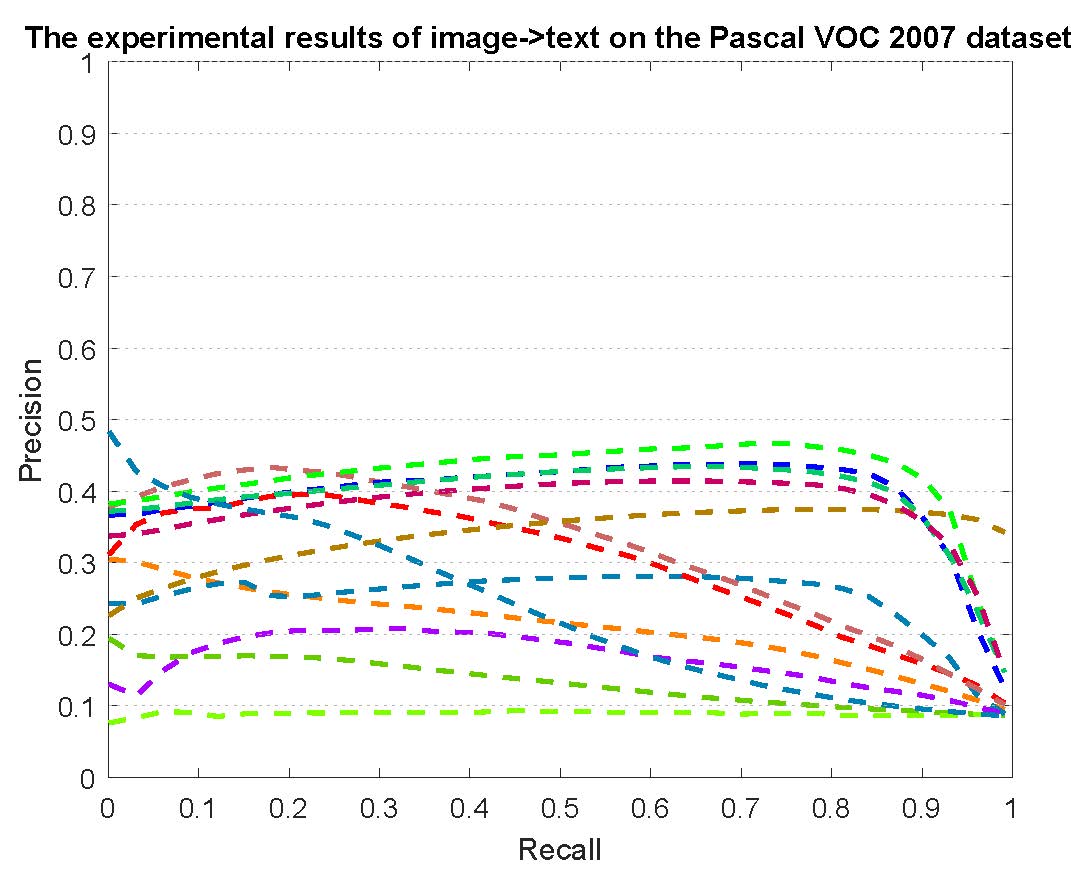
PR curves of retrieval on the Pascal VOC 2007 dataset are reported as below.
Figure 5: The experimental results of multi-modality cross-media retrieval and bi-modality cross-media retrieval on the Pascal VOC 2007 dataset.
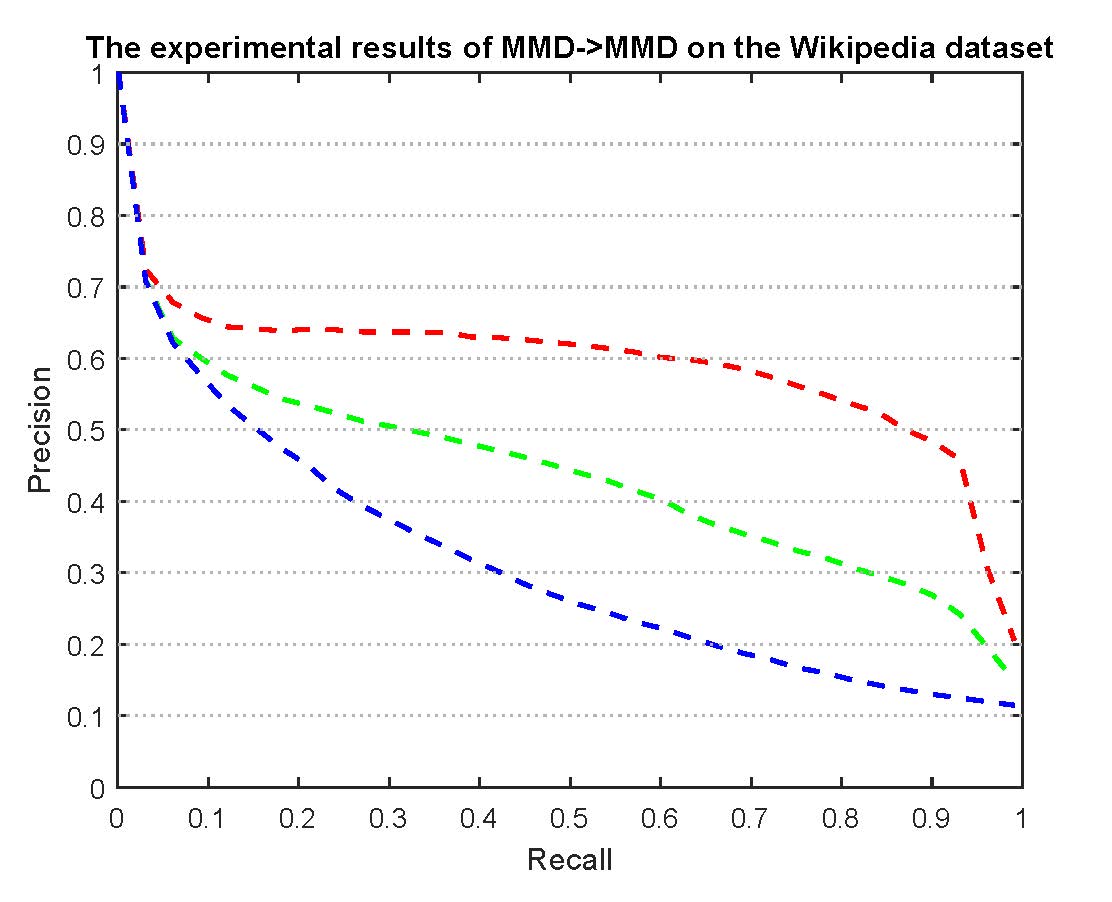
PR curves of MMD retrieval on the Wikipedia dataset are reported as below.
Figure 6: The experimental results of MMD->MMD on the Wikipedia dataset.
Download the evaluate code to calculate MAP and create plots of PR for retrieval results.
Download the data of PR curves of retrieval results.
New results: please send your results and publication to 2401112164@stu.pku.edu.cn to update
your results in Table 1-Table 11.
Time Consumption:
Table 12: Running time of multi-modality cross-media retrieval task for the compared methods on Wikipedia dataset
| Methods |
BITR |
CCA |
CCA+SMN |
CFA |
CMCP |
DCMIT |
HSNN |
JGRHML |
JRL |
LGCFL |
ml-CCA |
mv-CCA |
S2UPG |
| Time(s) |
94.1 |
0.8 |
1.6 |
0.9 |
19.4 |
0.8 |
7.5 |
9.7 |
10.1 |
0.7 |
296.6 |
0.8 |
24.1 |
Table 12 shows the time consumption of referred crossmedia
retrieval methods. We evaluate their efficiency on Wikipedia dataset by using 128-dimensional
BoVW histogram image feature and 10-dimensional LDA text
feature on a PC with an i7 4790K CPU and 16 GB memory. For fair
comparison, we measure the time consumption of the whole
running process of multi-modality cross-media retrieval for all these
methods, including the training and test stage.
Time complexity of some representative compared methods:
(n is the number of samples, d is the dimension of feature and k is the number of nearest neighbors in kNN algorithm)
- Canonical correlation analysis (CCA):O(n^3)
- Canonical correlation analysis and semantic multinomials (CCA+SMN):O(n^3)
- Cross-modal factor analysis (CFA):O(n^3)
- Cross-modality correlation propagation (CMCP):O(n^2)
- Heterogeneous similarity measure with nearest neighbors (HSNN) :O(n^2)
- Joint graph regularized heterogeneous metric learning (JGRHML):O(n^2)
- Joint representation learning (JRL):O(kn^2)
- Multi-label canonical correlation analysis (ml-CCA):O(n^2*d^2+d^3)
- Semi-supervised cross-media feature learning algorithm with unified patch graph regularization (S2UPG):O(kn^2)
Source Codes:
Download the example source codes for CMCP[14], HSNN[15], JRL[2], JGRHML[16], S2UPG[19] and CMDN[23], please
download the Release Agreement, read it carefully,
and complete it appropriately. Note that the agreement needs a handwritten signature by a full-time staff member (that is,
student is not acceptable). Then, please scan the signed agreement and send it to SiBo Yin (2401112164@stu.pku.edu.cn).
If you are from the mainland of China, please sign the agreement in Chinese rather than English.
Then we will verify your request and contact you on how to download the source codes.
References:
[1]N. Rasiwasia, J. Costa Pereira, E. Coviello, G. Doyle, G. R. Lanckriet,
R. Levy, and N. Vasconcelos, "A new approach to cross-modal
multimedia retrieval", in ACM international conference on Multimedia
(ACM-MM), pp. 251–260, 2010.
[2]X. Zhai, Y. Peng, and J. Xiao, "Learning cross-media joint representation
with sparse and semi-supervised regularization", IEEE Transactions on
Circuits and Systems for Video Technology (TCSVT), Vol. 24, No. 6, pp.
965–978, 2014.
[3]T.-S. Chua, J. Tang, R. Hong, H. Li, Z. Luo, and Y. Zheng, "Nus-wide:
a real-world web image database from national university of singapore",
in ACM International Conference on Image and Video Retrieval (CIVR), pp. 1–9, 2009.
[4]M. Everingham, L. J. V. Gool, C. K. I. Williams, J. M. Winn, and
A. Zisserman, "The pascal visual object classes (VOC) challenge",
International Journal of Computer Vision (IJCV), Vol. 88, No. 2, pp.
303–338, 2010.
[5]X. Hua, L. Yang, J. Wang, J. Wang, M. Ye, K. Wang, Y. Rui, and
J. Li, "Clickage: towards bridging semantic and intent gaps via mining
click logs of search engines", in ACM international conference on
Multimedia (ACM-MM), pp. 243–252, 2013.
[6]F. Wu, X. Lu, J. Song, S. Yan, Z. M. Zhang, Y. Rui, and Y. Zhuang,
"Learning of multimodal representations with random walks on the
click graph", IEEE Transactions on Image Processing (TIP), Vol. 25,
No. 2, pp. 630–642, 2016.
[7]Y. Pan, T. Yao, X. Tian, H. Li, and C. Ngo, "Click-through-based
subspace learning for image search", in ACM international conference
on Multimedia (ACM-MM), pp. 233–236, 2014.
[8]D.-Y. Chen, X.-P. Tian, Y.-T. Shen, and M. Ouhyoung, "On visual
similarity based 3d model retrieval", Computer Graphics Forum, Vol. 22,
No. 3, pp. 223–232, 2003.
[9]C. Kang, S. Xiang, S. Liao, C. Xu, and C. Pan, "Learning consistent
feature representation for cross-modal multimedia retrieval", IEEE
Transactions on Multimedia (TMM), Vol. 17, No. 3, pp. 370–381, 2015.
[10]F. Yan and K. Mikolajczyk, "Deep correlation for matching images and
text", in IEEE Conference on Computer Vision and Pattern Recognition
(CVPR), pp. 3441–3450, 2015.
[11]Y. Verma and C. V. Jawahar, "Im2text and text2im: Associating images
and texts for cross-modal retrieval", in British Machine Vision Conference
(BMVC), 2014.
[12]H. Hotelling, "Relations between two sets of variates", Biometrika, pp.
321–377, 1936.
[13]D. Li, N. Dimitrova, M. Li, and I. K. Sethi, "Multimedia content
processing through cross-modal association", in ACM international
conference on Multimedia (ACM-MM), pp. 604–611, 2003.
[14]X. Zhai, Y. Peng, and J. Xiao, "Cross-modality correlation propagation
for cross-media retrieval", in IEEE International Conference on Acoustics,
Speech and Signal Processing (ICASSP), pp. 2337–2340, 2012.
[15]X. Zhai, Y. Peng, and J. Xiao, "Effective heterogeneous similarity measure
with nearest neighbors for cross-media retrieval", in International
Conference on MultiMedia Modeling (MMM), pp. 312–322, 2012.
[16]X. Zhai, Y. Peng, and J. Xiao, "Heterogeneous metric learning with joint
graph regularization for cross-media retrieval", in AAAI Conference on
Artificial Intelligence (AAAI), pp. 1198–1204, 2013.
[17]V. Ranjan, N. Rasiwasia, and C. V. Jawahar, "Multi-label cross-modal
retrieval", in 2015 IEEE International Conference on Computer Vision
(ICCV), pp. 4094–4102, 2015.
[18]Y. Gong, Q. Ke, M. Isard, and S. Lazebnik, "A multi-view embedding
space for modeling internet images, tags, and their semantics", International
Journal of Computer Vision (IJCV), Vol. 106, No. 2, pp. 210–233, 2014.
[19]Y. Peng, X. Zhai, Y. Zhao, and X. Huang, "Semi-supervised crossmedia
feature learning with unified patch graph regularization", IEEE
Transactions on Circuits and Systems for Video Technology (TCSVT),
Vol. 26, No. 3, pp. 583 – 596, 2016.
[20]Y. Zhuang, Y. Yang, and F. Wu, "Mining semantic correlation of heterogeneous
multimedia data for cross-media retrieval", IEEE Transactions
on Multimedia (TMM), Vol. 10, No. 2, pp. 221–229, 2008.
[21]Y. Yang, Y. Zhuang, F. Wu, and Y. Pan, "Harmonizing hierarchical
manifolds for multimedia document semantics understanding and crossmedia
retrieval", IEEE Transactions on Multimedia (TMM), Vol. 10,
No. 3, pp. 437–446, 2008.
[22]Y. Yang, D. Xu, F. Nie, J. Luo, and Y. Zhuang, "Ranking with local
regression and global alignment for cross media retrieval", in ACM
international conference on Multimedia (ACM-MM), pp. 175–184, 2009.
[23]Y. Peng, X. Huang, and J. Qi, "Cross-media Shared Representation by Hierarchical Learning with Multiple Deep Networks", 25th International Joint Conference on Artificial Intelligence (IJCAI), pp. 3846-3853, 2016.
Contact:
Questions and comments can be sent to: 2401112164@stu.pku.edu.cn